基于Fourier Neural Operator的Navier-Stokes equation求解
![]()
![]()
![]()
概述
计算流体力学是21世纪流体力学领域的重要技术之一,其通过使用数值方法在计算机中对流体力学的控制方程进行求解,从而实现流动的分析、预测和控制。传统的有限元法(finite element method,FEM)和有限差分法(finite difference method,FDM)常用于复杂的仿真流程(物理建模、网格划分、数值离散、迭代求解等)和较高的计算成本,往往效率低下。因此,借助AI提升流体仿真效率是十分必要的。
近年来,随着神经网络的迅猛发展,为科学计算提供了新的范式。经典的神经网络是在有限维度的空间进行映射,只能学习与特定离散化相关的解。与经典神经网络不同,傅里叶神经算子(Fourier Neural Operator,FNO)是一种能够学习无限维函数空间映射的新型深度学习架构。该架构可直接学习从任意函数参数到解的映射,用于解决一类偏微分方程的求解问题,具有更强的泛化能力。更多信息可参考Fourier Neural Operator for Parametric Partial Differential Equations。
本案例教程介绍利用三维傅里叶神经算子的纳维-斯托克斯方程(Navier-Stokes equation)求解方法。
问题描述
本案例利用Fourier Neural Operator学习某一个时刻对应涡度到下一时刻涡度的映射,实现二维不可压缩N-S方程的求解:
技术路径
MindSpore Flow求解该问题的具体流程如下:
创建数据集。
构建模型。
优化器与损失函数。
模型训练。
Fourier Neural Operator
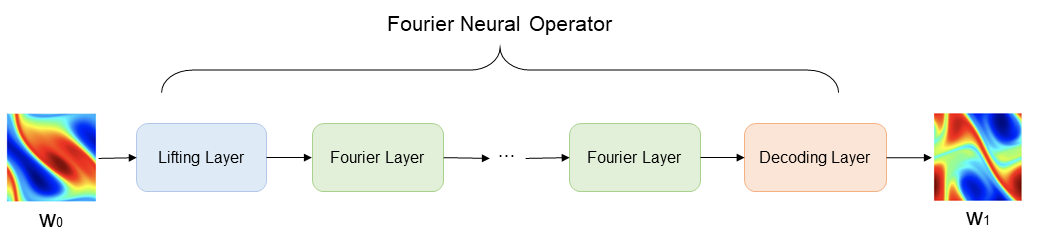
Fourier Neural Operator模型构架如下图所示。图中\(w_0(x)\)表示初始涡度,通过Lifting Layer实现输入向量的高维映射,然后将映射结果作为Fourier Layer的输入,进行频域信息的非线性变换,最后由Decoding Layer将变换结果映射至最终的预测结果\(w_1(x)\)。
Lifting Layer、Fourier Layer以及Decoding Layer共同组成了Fourier Neural Operator。
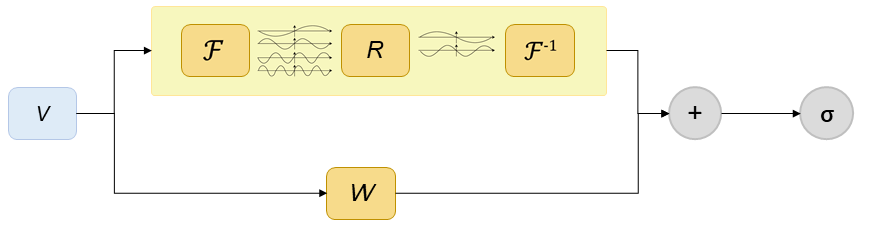
Fourier Layer网络结构如下图所示。图中V表示输入向量,上框表示向量经过傅里叶变换后,经过线性变换R,过滤高频信息,然后进行傅里叶逆变换;另一分支经过线性变换W,最后通过激活函数,得到Fourier Layer输出向量。
[1]:
import os
import time
import numpy as np
from mindspore import nn, ops, jit, data_sink, save_checkpoint, context, Tensor, ops
from mindspore.common import set_seed
from mindspore import dtype as mstype
下述src包可以在applications/data_driven/navier_stokes/fno3d/src下载。
[2]:
from mindflow import get_warmup_cosine_annealing_lr, load_yaml_config
from mindflow.cell.neural_operators.fno import FNO3D
from src import LpLoss, UnitGaussianNormalizer, create_training_dataset
set_seed(0)
np.random.seed(0)
[3]:
# set context for training: using graph mode for high performance training with GPU acceleration
context.set_context(mode=context.GRAPH_MODE, device_target='GPU', device_id=0)
use_ascend = context.get_context(attr_key='device_target') == "Ascend"
config = load_yaml_config('./configs/fno3d.yaml')
data_params = config["data"]
model_params = config["model"]
optimizer_params = config["optimizer"]
sub = model_params["sub"]
grid_size = model_params["input_resolution"] // sub
input_timestep = model_params["input_timestep"]
output_timestep = model_params["output_timestep"]
创建数据集
训练与测试数据下载: data_driven/navier_stokes_3d_fno/dataset .
本案例根据Zongyi Li在 Fourier Neural Operator for Parametric Partial Differential Equations 一文中对数据集的设置生成训练数据集与测试数据集。具体设置如下:
基于周期性边界,生成满足如下分布的初始条件\(w_0(x)\):
外力项设置为:
采用Crank-Nicolson方法生成数据,时间步长设置为1e-4,最终数据以每 t = 1 个时间单位记录解。所有数据均在256×256的网格上生成,并被下采样至64×64网格。本案例选取粘度系数\(\nu=1e−3\),训练集样本量为1000个,测试集样本量为200个。
[4]:
train_a = Tensor(np.load(os.path.join(
data_params["path"], "train_a.npy")), mstype.float32)
train_u = Tensor(np.load(os.path.join(
data_params["path"], "train_u.npy")), mstype.float32)
test_a = Tensor(np.load(os.path.join(
data_params["path"], "test_a.npy")), mstype.float32)
test_u = Tensor(np.load(os.path.join(
data_params["path"], "test_u.npy")), mstype.float32)
train_loader = create_training_dataset(data_params,
shuffle=True)
Data preparation finished
构建模型
网络由1层Lifting layer、多层Fourier Layer以及1层Decoding layer叠加组成:
Lifting layer对应样例代码中
FNO3D.fc0,将输出数据\(x\)映射至高维;多层Fourier Layer的叠加对应样例代码中
FNO3D.fno_seq,本案例采用离散傅里叶变换实现时域与频域的转换;Decoding layer对应代码中
FNO3D.fc1与FNO3D.fc2,获得最终的预测值。
[5]:
if use_ascend:
compute_type = mstype.float16
else:
compute_type = mstype.float32
# prepare model
model = FNO3D(in_channels=model_params["in_channels"],
out_channels=model_params["out_channels"],
n_modes=model_params["modes"],
resolutions=[model_params["input_resolution"],
model_params["input_resolution"], output_timestep],
hidden_channels=model_params["width"],
n_layers=model_params["depth"],
projection_channels=4*model_params["width"],
fno_compute_dtype=compute_type
)
model_params_list = []
for k, v in model_params.items():
model_params_list.append(f"{k}-{v}")
model_name = "_".join(model_params_list)
优化器与损失函数
使用相对均方根误差作为网络训练损失函数:
[6]:
lr = get_warmup_cosine_annealing_lr(lr_init=optimizer_params["initial_lr"],
last_epoch=optimizer_params["train_epochs"],
steps_per_epoch=train_loader.get_dataset_size(),
warmup_epochs=optimizer_params["warmup_epochs"])
optimizer = nn.optim.Adam(model.trainable_params(),
learning_rate=Tensor(lr), weight_decay=optimizer_params['weight_decay'])
loss_fn = LpLoss()
a_normalizer = UnitGaussianNormalizer(train_a)
y_normalizer = UnitGaussianNormalizer(train_u)
[1]:
def calculate_l2_error(model, inputs, labels):
"""
Evaluate the model respect to input data and label.
Args:
model (Cell): list of expressions node can by identified by mindspore.
inputs (Tensor): the input data of network.
labels (Tensor): the true output value of given inputs.
"""
print("================================Start Evaluation================================")
time_beg = time.time()
rms_error = 0.0
for i in range(labels.shape[0]):
label = labels[i:i + 1]
test_batch = inputs[i:i + 1]
test_batch = a_normalizer.encode(test_batch)
label = y_normalizer.encode(label)
test_batch = test_batch.reshape(
1, grid_size, grid_size, 1, input_timestep).repeat(output_timestep, axis=3)
prediction = model(test_batch).reshape(
1, grid_size, grid_size, output_timestep)
prediction = y_normalizer.decode(prediction)
label = y_normalizer.decode(label)
rms_error_step = loss_fn(prediction.reshape(
1, -1), label.reshape(1, -1))
rms_error += rms_error_step
rms_error = rms_error / labels.shape[0]
print("mean rms_error:", rms_error)
print("predict total time: {} s".format(time.time() - time_beg))
print("=================================End Evaluation=================================")
训练函数
使用MindSpore>= 2.0.0的版本,可以使用函数式编程范式训练神经网络,单步训练函数使用jit装饰。数据下沉函数data_sink,传入单步训练函数和训练数据集。
[2]:
def forward_fn(data, label):
bs = data.shape[0]
data = a_normalizer.encode(data)
label = y_normalizer.encode(label)
data = data.reshape(bs, grid_size, grid_size, 1, input_timestep).repeat(
output_timestep, axis=3)
logits = model(data).reshape(bs, grid_size, grid_size, output_timestep)
logits = y_normalizer.decode(logits)
label = y_normalizer.decode(label)
loss = loss_fn(logits.reshape(bs, -1), label.reshape(bs, -1))
return loss
grad_fn = ops.value_and_grad(
forward_fn, None, optimizer.parameters, has_aux=False)
@jit
def train_step(data, label):
loss, grads = grad_fn(data, label)
loss = ops.depend(loss, optimizer(grads))
return loss
sink_process = data_sink(train_step, train_loader, sink_size=100)
模型训练
使用MindSpore >= 2.0.0的版本,可以使用函数式编程范式训练神经网络。
[7]:
def train():
summary_dir = os.path.join(config["summary_dir"], model_name)
ckpt_dir = os.path.join(summary_dir, "ckpt")
if not os.path.exists(ckpt_dir):
os.makedirs(ckpt_dir)
model.set_train()
for step in range(1, 1 + optimizer_params["train_epochs"]):
local_time_beg = time.time()
cur_loss = sink_process()
print(
f"epoch: {step} train loss: {cur_loss} epoch time: {time.time() - local_time_beg:.2f}s")
if step % 10 == 0:
print(f"loss: {cur_loss.asnumpy():>7f}")
print("step: {}, time elapsed: {}ms".format(
step, (time.time() - local_time_beg) * 1000))
calculate_l2_error(model, test_a, test_u)
save_checkpoint(model, os.path.join(
ckpt_dir, model_params["name"]))
[3]:
train()
pid: 1993
2023-02-01 12:14:12.2323
use_ascend: False
device_id: 2
Data preparation finished
steps_per_epoch: 1000
epoch: 1 train loss: 1.7631323 epoch time: 50.41s
epoch: 2 train loss: 1.9283392 epoch time: 36.59s
epoch: 3 train loss: 1.4265916 epoch time: 35.09s
epoch: 4 train loss: 1.8609437 epoch time: 34.41s
epoch: 5 train loss: 1.5222052 epoch time: 34.60s
epoch: 6 train loss: 1.3424721 epoch time: 33.85s
epoch: 7 train loss: 1.607729 epoch time: 33.11s
epoch: 8 train loss: 1.3308442 epoch time: 33.05s
epoch: 9 train loss: 1.3169765 epoch time: 33.90s
epoch: 10 train loss: 1.4149593 epoch time: 33.91s
...
predict total time: 15.179609298706055 s
epoch: 141 train loss: 0.777328 epoch time: 32.55s
epoch: 142 train loss: 0.7008966 epoch time: 32.52s
epoch: 143 train loss: 0.72377646 epoch time: 32.57s
epoch: 144 train loss: 0.72175145 epoch time: 32.44s
epoch: 145 train loss: 0.6235678 epoch time: 32.46s
epoch: 146 train loss: 0.9351083 epoch time: 32.45s
epoch: 147 train loss: 0.9283789 epoch time: 32.47s
epoch: 148 train loss: 0.7655642 epoch time: 32.60s
epoch: 149 train loss: 0.7233772 epoch time: 32.65s
epoch: 150 train loss: 0.86825275 epoch time: 32.59s
================================Start Evaluation================================
mean rel_rmse_error: 0.07437102290522307
=================================End Evaluation=================================
predict total time: 15.212349653244019 s