数据驱动(FNO2D和UNET2D两种backbone)下跨声速翼型复杂流场的多时间步预测
![]()
![]()
![]()
概述
高精度非定常流动模拟是计算流体力学中的关键课题,有着广泛的应用场景和广阔的市场价值。然而,传统方法存在着算不快、算不准、算不稳等问题,通过AI方法探索流场演化规律为此提供了新的视角。
本案例在二维跨声速翼型场景下提供了端到端的非定常复杂流场预测解决方案。案例中搭建了傅里叶神经算子(Fourier Neural Operator,FNO)和Unet两种网络结构。可以在保证一定精度的前提下,根据输入的k个时间步的流场,稳定预测出接续的m个时间步的流场。
本案例中,流场来流马赫数达到了Ma=0.73。通过本案例可以验证深度学习方法在存在激波等复杂流动结构场景中,对多物理参数变化下非定常流场预测的有效性。
问题描述
本案例利用k个时刻的流场学习接续的m个时刻的流场,实现二维可压缩非定常流场的预测:
技术路径
求解该问题的具体流程如下:
构建数据集。
构建模型。
优化器与损失函数。
模型训练。
准备环节
实践前,确保已经正确安装合适版本的MindSpore。如果没有,可以通过:
MindSpore安装页面 安装MindSpore。
二维翼型非定常流场预测的实现
二维翼型非定常流场预测的实现分为以下7个步骤:
配置网络与训练参数
数据集的准备
模型构建
损失函数与优化器
训练函数
模型训练
结果可视化
[1]:
import os
import time
import numpy as np
from mindspore import nn, Tensor, context, ops, jit, set_seed, data_sink, save_checkpoint
from mindspore import dtype as mstype
from mindflow.common import get_warmup_cosine_annealing_lr
from mindflow.loss import RelativeRMSELoss
from mindflow.utils import load_yaml_config, print_log
from src import Trainer, init_dataset, init_model, plt_log, check_file_path, count_params
[2]:
set_seed(0)
np.random.seed(0)
[3]:
context.set_context(mode=context.GRAPH_MODE,
save_graphs=False,
device_target="Ascend",
device_id=0)
use_ascend = context.get_context("device_target") == "Ascend"
配置网络与训练参数
从配置文件中读取四类参数,分别为模型相关参数(model)、数据相关参数(data)、优化器相关参数(optimizer)和回调相关参数(callback)。
[4]:
config = load_yaml_config("./config/2D_unsteady.yaml")
data_params = config["data"]
model_params = config["model"]
optimizer_params = config["optimizer"]
summary_params = config["summary"]
数据集的准备
数据集下载地址:data_driven/airfoil/2D_unsteady
数据为npz类型文件,其维度(t, H, W, C)为(9997, 128, 128, 3)。其中,t为时间步数,H和W为流场分辨率,C为通道数,3个通道分别为速度U、V和压力P。
[5]:
train_dataset, test_dataset, means, stds = init_dataset(data_params)
input size (3560, 8, 128, 128, 3)
label size (3560, 32, 128, 128, 3)
train_batch_size : 8
train dataset size: 2967
test dataset size: 593
train batch dataset size: 370
test batch dataset size: 74
模型构建
通过initial_model()函数调用,调用之前,需要先针对硬件定制loss_scaler和compute_dtype。
[6]:
if use_ascend:
from mindspore.amp import DynamicLossScaler, all_finite, auto_mixed_precision
loss_scaler = DynamicLossScaler(1024, 2, 100)
compute_dtype = mstype.float16
model = init_model("fno2d", data_params, model_params, compute_dtype=compute_dtype)
auto_mixed_precision(model, optimizer_params["amp_level"]["fno2d"])
else:
context.set_context(enable_graph_kernel=True)
loss_scaler = None
compute_dtype = mstype.float32
model = init_model("fno2d", data_params, model_params, compute_dtype=compute_dtype)
compute_dtype_of_FNO Float16
损失函数与优化器
当前案例中的损失函数采用了RelativeRMSELoss,优化器则选择了AdamWeightDecay,其中,学习率衰减采用了warmup_cosine_annealing_lr的策略。用户也可以根据需要定制适合的损失函数与优化器。
[7]:
loss_fn = RelativeRMSELoss()
summary_dir = os.path.join(summary_params["summary_dir"], "Exp01", "fno2d")
ckpt_dir = os.path.join(summary_dir, "ckpt_dir")
check_file_path(ckpt_dir)
check_file_path(os.path.join(ckpt_dir, 'img'))
print_log('model parameter count:', count_params(model.trainable_params()))
print_log(
f'learing rate: {optimizer_params["lr"]["fno2d"]}, T_in: {data_params["T_in"]}, T_out: {data_params["T_out"]}')
steps_per_epoch = train_dataset.get_dataset_size()
lr = get_warmup_cosine_annealing_lr(optimizer_params["lr"]["fno2d"], steps_per_epoch,
optimizer_params["epochs"], optimizer_params["warm_up_epochs"])
optimizer = nn.AdamWeightDecay(model.trainable_params(),
learning_rate=Tensor(lr),
weight_decay=optimizer_params["weight_decay"])
model parameter count: 9464259
learing rate: 0.001, T_in: 8, T_out: 32
训练函数
使用MindSpore>= 2.0.0的版本,可以使用函数式编程范式训练神经网络,单步训练函数使用jit装饰。数据下沉函数data_sink,传入单步训练函数和训练数据集。
[8]:
trainer = Trainer(model, data_params, loss_fn, means, stds)
def forward_fn(inputs, labels):
loss, _, _, _ = trainer.get_loss(inputs, labels)
if use_ascend:
loss = loss_scaler.scale(loss)
return loss
grad_fn = ops.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=False)
@jit
def train_step(inputs, labels):
loss, grads = grad_fn(inputs, labels)
if use_ascend:
loss = loss_scaler.unscale(loss)
if all_finite(grads):
grads = loss_scaler.unscale(grads)
loss_new = ops.depend(loss, optimizer(grads))
return loss_new
def test_step(inputs, labels):
return trainer.get_loss(inputs, labels)
train_size = train_dataset.get_dataset_size()
test_size = test_dataset.get_dataset_size()
train_sink = data_sink(train_step, train_dataset, sink_size=1)
test_sink = data_sink(test_step, test_dataset, sink_size=1)
test_interval = summary_params["test_interval"]
save_ckpt_interval = summary_params["save_ckpt_interval"]
模型训练
模型训练过程中边训练边推理。用户可以直接加载测试数据集,每训练test_interval个epoch后输出一次测试集上的推理精度并保存可视化结果。同时,还可以每隔save_checkpoint_interval保存一次checkpoint文件。
[9]:
for epoch in range(1, optimizer_params["epochs"] + 1):
time_beg = time.time()
train_l2_step = 0.0
model.set_train()
for step in range(1, train_size + 1):
loss = train_sink()
train_l2_step += loss.asnumpy()
train_l2_step = train_l2_step / train_size / data_params["T_out"]
print_log(
f"epoch: {epoch}, step time: {(time.time() - time_beg) / steps_per_epoch:>7f}, loss: {train_l2_step:>7f}")
if epoch % test_interval == 0:
model.set_train(False)
test_l2_by_step = [0.0 for _ in range(data_params["T_out"])]
print_log("---------------------------start test-------------------------")
for step in range(test_size):
_, pred, truth, step_losses = test_sink()
for i in range(data_params["T_out"]):
test_l2_by_step[i] += step_losses[i].asnumpy()
test_l2_by_step = [error / test_size for error in test_l2_by_step]
test_l2_step = np.mean(test_l2_by_step)
print_log(f' test epoch: {epoch}, loss: {test_l2_step}')
print_log("---------------------------end test---------------------------")
plt_log(predicts=pred.asnumpy(),
labels=truth.asnumpy(),
img_dir=os.path.join(ckpt_dir, 'img'),
epoch=epoch
)
if epoch % save_ckpt_interval == 0:
save_checkpoint(model, ckpt_file_name=os.path.join(ckpt_dir, 'airfoil2D_unsteady.ckpt'))
epoch: 1, step time: 2.652332, loss: 0.733017
epoch: 2, step time: 0.688175, loss: 0.203251
epoch: 3, step time: 0.686817, loss: 0.128816
epoch: 4, step time: 0.685909, loss: 0.109786
epoch: 5, step time: 0.688545, loss: 0.093725
epoch: 6, step time: 0.685986, loss: 0.076027
epoch: 7, step time: 0.686459, loss: 0.069847
epoch: 8, step time: 0.688228, loss: 0.058694
epoch: 9, step time: 0.688053, loss: 0.060886
epoch: 10, step time: 0.692221, loss: 0.065305
---------------------------start test-------------------------
test epoch: 10, loss: 0.03798117920381923
---------------------------end test---------------------------
...
epoch: 191, step time: 0.693253, loss: 0.007012
epoch: 192, step time: 0.691330, loss: 0.007043
epoch: 193, step time: 0.692804, loss: 0.006986
epoch: 194, step time: 0.690053, loss: 0.006973
epoch: 195, step time: 0.692159, loss: 0.006967
epoch: 196, step time: 0.690170, loss: 0.006944
epoch: 197, step time: 0.690344, loss: 0.006930
epoch: 198, step time: 0.690674, loss: 0.006911
epoch: 199, step time: 0.690877, loss: 0.006904
epoch: 200, step time: 0.689170, loss: 0.006892
---------------------------start test-------------------------
test epoch: 200, loss: 0.005457837492891436
---------------------------end test---------------------------
结果可视化
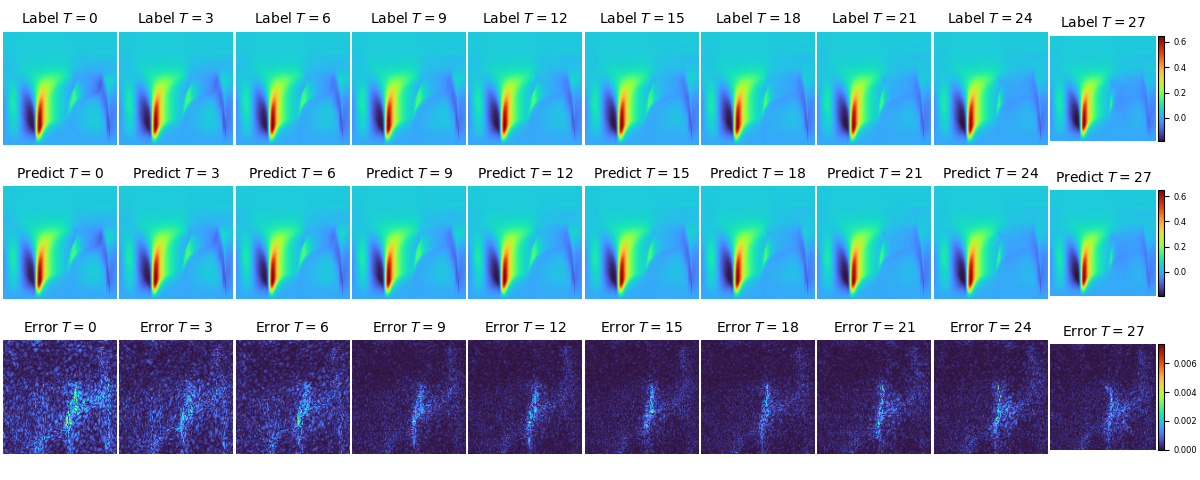
UNET2D backbone下,不同时刻压力P的实际值、预测值和误差在流场中的分布如下图:
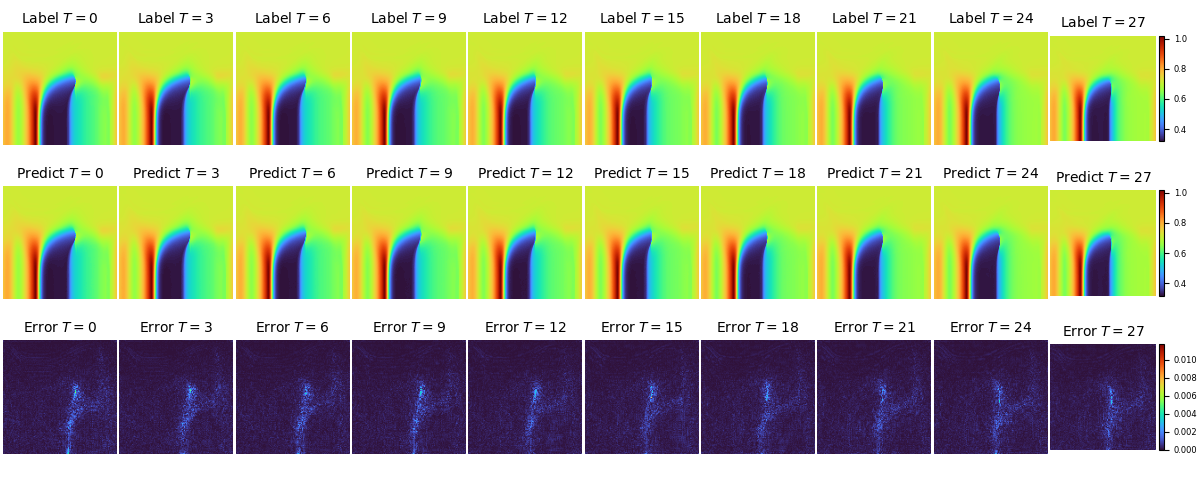
UNET2D backbone下,不同时刻速度U的实际值、预测值和误差在流场中的分布如下图:
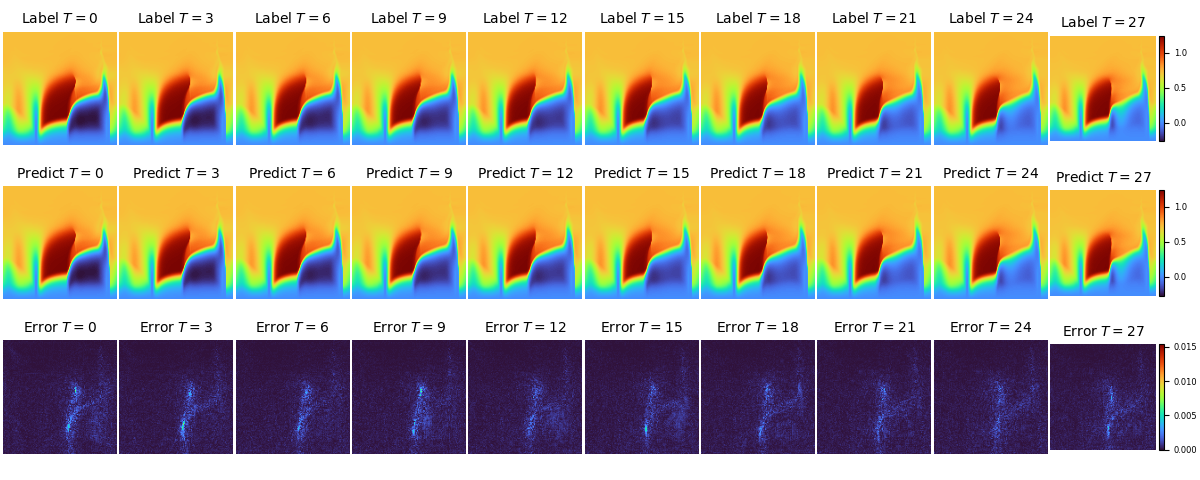
UNET2D backbone下,不同时刻速度V的实际值、预测值和误差在流场中的分布如下图:

FNO2D backbone下,不同时刻压力P的实际值、预测值和误差在流场中的分布如下图:
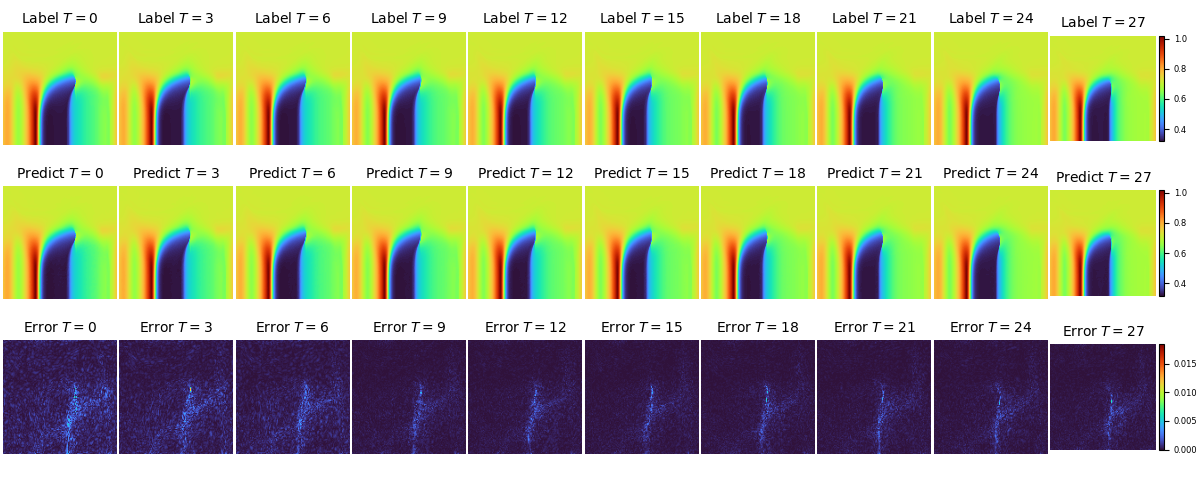
FNO2D backbone下,不同时刻速度U的实际值、预测值和误差在流场中的分布如下图:
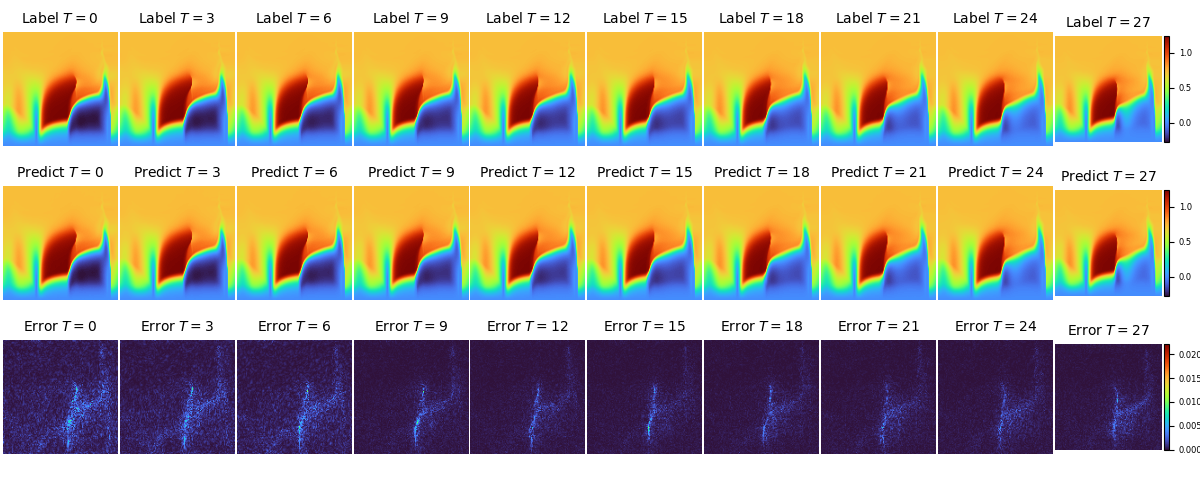
FNO2D backbone下,不同时刻速度V的实际值、预测值和误差在流场中的分布如下图: