PeRCNN求解3D 反应扩散方程
![]()
![]()
![]()
概述
近日,华为与中国人民大学孙浩教授团队合作,基于昇腾AI基础软硬件平台与昇思 MindSpore AI框架提出了一种物理编码递归卷积神经网络(Physics-encoded Recurrent Convolutional Neural Network, PeRCNN)。相较于物理信息神经网络、ConvLSTM、PDE-NET等方法,模型泛化性和抗噪性明显提升,长期推理精度提升了 10倍以上,在航空航天、船舶制造、气象预报等领域拥有广阔的应用前景,目前该成果已在 nature machine intelligence 上发表。
问题描述
反应扩散方程(reaction-diffusion equation)是非常重要且应用广泛的一类偏微分方程,它描述了物理学中的种种现象,也在化学反应中被广泛使用。
控制方程
在本研究中,反应扩散方程的形式为:
\[u_t = \mu_u \Delta u - u{v*2} + F(1-v).\]
\[v_t = \mu_v \Delta v + u{v*2} + (F+\kappa)v.\]
其中,
\[\mu_v = 0.1, \mu_u = 0.2, F = 0.025, \kappa = 0.055.\]
在本案例中,拟在$ \Omega `:nbsphinx-math:times :nbsphinx-math:tau = {[-50,50]}^3 :nbsphinx-math:times [0,500] `$ 的物理域中求解100个时间步的流场演化(时间步长为0.5s),初始条件经历了高斯加噪,采取周期性边界条件。
技术路径
MindSpore Flow求解该问题的具体流程如下:
优化器
构建模型
模型训练
模型推理及可视化。
[1]:
import os
import sys
import time
import numpy as np
[2]:
from mindspore import context, jit, nn, ops, save_checkpoint, set_seed
import mindspore.common.dtype as mstype
from mindflow.utils import load_yaml_config, print_log
from src import RecurrentCnn, post_process, Trainer, UpScaler, count_params
[3]:
set_seed(123456)
np.random.seed(123456)
context.set_context(mode=context.GRAPH_MODE, device_target="GPU", device_id=0)
优化器和单步训练
[4]:
def train_stage(trainer, stage, config, ckpt_dir, use_ascend):
"""train stage"""
if use_ascend:
from mindspore.amp import DynamicLossScaler, all_finite
loss_scaler = DynamicLossScaler(2**10, 2, 100)
if 'milestone_num' in config.keys():
milestone = list([(config['epochs']//config['milestone_num'])*(i + 1)
for i in range(config['milestone_num'])])
learning_rate = config['learning_rate']
lr = float(config['learning_rate'])*np.array(list([config['gamma']
** i for i in range(config['milestone_num'])]))
learning_rate = nn.piecewise_constant_lr(milestone, list(lr))
else:
learning_rate = config['learning_rate']
if stage == 'pretrain':
params = trainer.upconv.trainable_params()
else:
params = trainer.upconv.trainable_params() + trainer.recurrent_cnn.trainable_params()
optimizer = nn.Adam(params, learning_rate=learning_rate)
def forward_fn():
if stage == 'pretrain':
loss = trainer.get_ic_loss()
else:
loss = trainer.get_loss()
if use_ascend:
loss = loss_scaler.scale(loss)
return loss
if stage == 'pretrain':
grad_fn = ops.value_and_grad(forward_fn, None, params, has_aux=False)
else:
grad_fn = ops.value_and_grad(forward_fn, None, params, has_aux=True)
@jit
def train_step():
loss, grads = grad_fn()
if use_ascend:
loss = loss_scaler.unscale(loss)
is_finite = all_finite(grads)
if is_finite:
grads = loss_scaler.unscale(grads)
loss = ops.depend(loss, optimizer(grads))
loss_scaler.adjust(is_finite)
else:
loss = ops.depend(loss, optimizer(grads))
return loss
best_loss = sys.maxsize
for epoch in range(1, 1 + config['epochs']):
time_beg = time.time()
trainer.upconv.set_train(True)
trainer.recurrent_cnn.set_train(True)
if stage == 'pretrain':
step_train_loss = train_step()
print_log(
f"epoch: {epoch} train loss: {step_train_loss} epoch time: {(time.time() - time_beg) :.3f} s")
else:
if epoch == 3800:
break
epoch_loss, loss_data, loss_ic, loss_phy, loss_valid = train_step()
print_log(f"epoch: {epoch} train loss: {epoch_loss} ic_loss: {loss_ic} data_loss: {loss_data} \
phy_loss: {loss_phy} valid_loss: {loss_valid} epoch time: {(time.time() - time_beg): .3f} s")
if epoch_loss < best_loss:
best_loss = epoch_loss
print_log('best loss', best_loss, 'save model')
save_checkpoint(trainer.upconv, os.path.join(ckpt_dir, "train_upconv.ckpt"))
save_checkpoint(trainer.recurrent_cnn,
os.path.join(ckpt_dir, "train_recurrent_cnn.ckpt"))
构建模型
PeRCNN要构建两个网络,一个是做上采样的UpSclaer,一个是作为主体的recurrent CNN。
[5]:
def train():
"""train"""
rd_config = load_yaml_config('./configs/percnn_3d_rd.yaml')
data_config = rd_config['data']
optim_config = rd_config['optimizer']
summary_config = rd_config['summary']
model_config = rd_config['model']
use_ascend = context.get_context(attr_key='device_target') == "Ascend"
print_log(f"use_ascend: {use_ascend}")
if use_ascend:
compute_dtype = mstype.float16
else:
compute_dtype = mstype.float32
upconv_config = model_config['upconv']
upconv = UpScaler(in_channels=upconv_config['in_channel'],
out_channels=upconv_config['out_channel'],
hidden_channels=upconv_config['hidden_channel'],
kernel_size=upconv_config['kernel_size'],
stride=upconv_config['stride'],
has_bais=True)
if use_ascend:
from mindspore.amp import auto_mixed_precision
auto_mixed_precision(upconv, 'O1')
rcnn_config = model_config['rcnn']
recurrent_cnn = RecurrentCnn(input_channels=rcnn_config['in_channel'],
hidden_channels=rcnn_config['hidden_channel'],
kernel_size=rcnn_config['kernel_size'],
stride=rcnn_config['stride'],
compute_dtype=compute_dtype)
percnn_trainer = Trainer(upconv=upconv,
recurrent_cnn=recurrent_cnn,
timesteps_for_train=data_config['rollout_steps'],
dx=data_config['dx'],
grid_size=data_config['grid_size'],
dt=data_config['dt'],
mu=data_config['mu'],
data_path=data_config['data_path'],
compute_dtype=compute_dtype)
total_params = int(count_params(upconv.trainable_params()) +
count_params(recurrent_cnn.trainable_params()))
print(f"There are {total_params} parameters")
ckpt_dir = summary_config["ckpt_dir"]
fig_path = summary_config["fig_save_path"]
if not os.path.exists(ckpt_dir):
os.makedirs(ckpt_dir)
train_stage(percnn_trainer, 'pretrain',
optim_config['pretrain'], ckpt_dir, use_ascend)
train_stage(percnn_trainer, 'finetune',
optim_config['finetune'], ckpt_dir, use_ascend)
output = percnn_trainer.get_output(100).asnumpy()
output = np.transpose(output, (1, 0, 2, 3, 4))[:, :-1:10]
print('output shape is ', output.shape)
for i in range(0, 10, 2):
post_process(output[0, i], fig_path, is_u=True, num=i)
模型训练
[1]:
train()
use_ascend: False
shape of uv is (3001, 2, 48, 48, 48)
shape of ic is (1, 2, 48, 48, 48)
shape of init_state_low is (1, 2, 24, 24, 24)
There are 10078 parameters
epoch: 1 train loss: 0.160835 epoch time: 5.545 s
epoch: 2 train loss: 104.36749 epoch time: 0.010 s
epoch: 3 train loss: 4.3207517 epoch time: 0.009 s
epoch: 4 train loss: 8.491383 epoch time: 0.009 s
epoch: 5 train loss: 23.683647 epoch time: 0.009 s
epoch: 6 train loss: 23.857117 epoch time: 0.010 s
epoch: 7 train loss: 16.037672 epoch time: 0.010 s
epoch: 8 train loss: 8.406443 epoch time: 0.009 s
epoch: 9 train loss: 3.527469 epoch time: 0.020 s
epoch: 10 train loss: 1.0823832 epoch time: 0.009 s
...
epoch: 9990 train loss: 8.7615306e-05 epoch time: 0.008 s
epoch: 9991 train loss: 8.76504e-05 epoch time: 0.008 s
epoch: 9992 train loss: 8.761823e-05 epoch time: 0.008 s
epoch: 9993 train loss: 8.7546505e-05 epoch time: 0.008 s
epoch: 9994 train loss: 8.7519744e-05 epoch time: 0.008 s
epoch: 9995 train loss: 8.753734e-05 epoch time: 0.008 s
epoch: 9996 train loss: 8.753101e-05 epoch time: 0.008 s
epoch: 9997 train loss: 8.748294e-05 epoch time: 0.008 s
epoch: 9998 train loss: 8.7443106e-05 epoch time: 0.008 s
epoch: 9999 train loss: 8.743979e-05 epoch time: 0.008 s
epoch: 10000 train loss: 8.744074e-05 epoch time: 0.008 s
epoch: 1 train loss: 61.754555 ic_loss: 8.7413886e-05 data_loss: 6.1754117 phy_loss: 2.6047118 valid_loss: 7.221066 truth_loss: 2.7125626 epoch time: 138.495 s
best loss 61.754555 save model
epoch: 2 train loss: 54.79151 ic_loss: 0.32984126 data_loss: 5.3142304 phy_loss: 52.50226 valid_loss: 6.812231 truth_loss: 2.7744124 epoch time: 1.342 s
best loss 54.79151 save model
epoch: 3 train loss: 46.904842 ic_loss: 0.12049961 data_loss: 4.6302347 phy_loss: 32.494545 valid_loss: 5.953037 truth_loss: 2.579268 epoch time: 1.262 s
best loss 46.904842 save model
epoch: 4 train loss: 40.674736 ic_loss: 0.031907484 data_loss: 4.05152 phy_loss: 11.360751 valid_loss: 5.08032 truth_loss: 2.3503494 epoch time: 1.233 s
best loss 40.674736 save model
epoch: 5 train loss: 36.910408 ic_loss: 0.10554239 data_loss: 3.6382694 phy_loss: 3.5776496 valid_loss: 4.4271708 truth_loss: 2.1671412 epoch time: 1.315 s
best loss 36.910408 save model
epoch: 6 train loss: 33.767193 ic_loss: 0.14396289 data_loss: 3.304738 phy_loss: 1.4308721 valid_loss: 3.954126 truth_loss: 2.0307255 epoch time: 1.322 s
best loss 33.767193 save model
epoch: 7 train loss: 30.495178 ic_loss: 0.09850004 data_loss: 3.0002677 phy_loss: 0.8241035 valid_loss: 3.586939 truth_loss: 1.9244627 epoch time: 1.178 s
best loss 30.495178 save model
epoch: 8 train loss: 27.448381 ic_loss: 0.03362463 data_loss: 2.728026 phy_loss: 0.6343211 valid_loss: 3.286183 truth_loss: 1.8369334 epoch time: 1.271 s
best loss 27.448381 save model
epoch: 9 train loss: 24.990078 ic_loss: 0.0024543565 data_loss: 2.4977806 phy_loss: 0.5740176 valid_loss: 3.0332325 truth_loss: 1.7619449 epoch time: 1.573 s
best loss 24.990078 save model
epoch: 10 train loss: 23.15583 ic_loss: 0.014634784 data_loss: 2.3082657 phy_loss: 0.5407104 valid_loss: 2.8156128 truth_loss: 1.6955423 epoch time: 1.351 s
best loss 23.15583 save model
...
epoch: 1640 train loss: 0.094870105 ic_loss: 0.0006555757 data_loss: 0.009159223 phy_loss: 0.000713372 valid_loss: 0.012182931 truth_loss: 0.16177362 epoch time: 1.289 s
best loss 0.094870105 save model
epoch: 1641 train loss: 0.09474868 ic_loss: 0.00065547746 data_loss: 0.00914713 phy_loss: 0.00071231654 valid_loss: 0.01216803 truth_loss: 0.16169967 epoch time: 1.259 s
best loss 0.09474868 save model
epoch: 1642 train loss: 0.09462735 ic_loss: 0.0006553787 data_loss: 0.009135046 phy_loss: 0.00071125705 valid_loss: 0.012153144 truth_loss: 0.16162594 epoch time: 1.310 s
best loss 0.09462735 save model
epoch: 1643 train loss: 0.094506115 ic_loss: 0.000655279 data_loss: 0.009122972 phy_loss: 0.00071020663 valid_loss: 0.01213827 truth_loss: 0.16155209 epoch time: 1.379 s
best loss 0.094506115 save model
epoch: 1644 train loss: 0.094384976 ic_loss: 0.0006551788 data_loss: 0.009110908 phy_loss: 0.0007091502 valid_loss: 0.012123411 truth_loss: 0.16147849 epoch time: 1.375 s
best loss 0.094384976 save model
epoch: 1645 train loss: 0.094263926 ic_loss: 0.0006550779 data_loss: 0.009098854 phy_loss: 0.0007081007 valid_loss: 0.012108564 truth_loss: 0.16140485 epoch time: 1.354 s
best loss 0.094263926 save model
epoch: 1646 train loss: 0.09414298 ic_loss: 0.0006549765 data_loss: 0.00908681 phy_loss: 0.00070705137 valid_loss: 0.012093734 truth_loss: 0.16133131 epoch time: 1.332 s
best loss 0.09414298 save model
epoch: 1647 train loss: 0.09402215 ic_loss: 0.0006548743 data_loss: 0.009074777 phy_loss: 0.0007060007 valid_loss: 0.012078916 truth_loss: 0.16125791 epoch time: 1.435 s
best loss 0.09402215 save model
epoch: 1648 train loss: 0.09390141 ic_loss: 0.0006547714 data_loss: 0.009062755 phy_loss: 0.00070495723 valid_loss: 0.012064112 truth_loss: 0.16118445 epoch time: 1.402 s
best loss 0.09390141 save model
epoch: 1649 train loss: 0.09378076 ic_loss: 0.00065466797 data_loss: 0.009050743 phy_loss: 0.0007039088 valid_loss: 0.012049323 truth_loss: 0.1611112 epoch time: 1.284 s
best loss 0.09378076 save model
epoch: 1650 train loss: 0.09366022 ic_loss: 0.00065456395 data_loss: 0.009038741 phy_loss: 0.00070286694 valid_loss: 0.0120345475 truth_loss: 0.16103792 epoch time: 1.502 s
best loss 0.09366022 save model
epoch: 1651 train loss: 0.093539774 ic_loss: 0.0006544591 data_loss: 0.009026748 phy_loss: 0.0007018241 valid_loss: 0.012019787 truth_loss: 0.16096477 epoch time: 1.274 s
best loss 0.093539774 save model
epoch: 1652 train loss: 0.093419425 ic_loss: 0.0006543536 data_loss: 0.009014766 phy_loss: 0.00070078264 valid_loss: 0.012005039 truth_loss: 0.16089168 epoch time: 1.456 s
best loss 0.093419425 save model
epoch: 1653 train loss: 0.09329918 ic_loss: 0.00065424765 data_loss: 0.0090027945 phy_loss: 0.00069974473 valid_loss: 0.011990305 truth_loss: 0.16081864 epoch time: 1.203 s
best loss 0.09329918 save model
epoch: 1654 train loss: 0.09317903 ic_loss: 0.00065414095 data_loss: 0.008990833 phy_loss: 0.000698706 valid_loss: 0.011975586 truth_loss: 0.16074573 epoch time: 1.285 s
best loss 0.09317903 save model
epoch: 1655 train loss: 0.09305898 ic_loss: 0.0006540336 data_loss: 0.008978881 phy_loss: 0.0006976697 valid_loss: 0.011960882 truth_loss: 0.16067289 epoch time: 1.159 s
best loss 0.09305898 save model
epoch: 1656 train loss: 0.092939034 ic_loss: 0.0006539258 data_loss: 0.00896694 phy_loss: 0.00069663546 valid_loss: 0.01194619 truth_loss: 0.16060013 epoch time: 1.274 s
best loss 0.092939034 save model
epoch: 1657 train loss: 0.092819184 ic_loss: 0.00065381714 data_loss: 0.00895501 phy_loss: 0.00069560105 valid_loss: 0.011931514 truth_loss: 0.16052744 epoch time: 1.174 s
best loss 0.092819184 save model
epoch: 1658 train loss: 0.09269943 ic_loss: 0.0006537079 data_loss: 0.008943089 phy_loss: 0.0006945693 valid_loss: 0.011916851 truth_loss: 0.1604548 epoch time: 1.296 s
best loss 0.09269943 save model
epoch: 1659 train loss: 0.092579775 ic_loss: 0.00065359805 data_loss: 0.008931179 phy_loss: 0.0006935386 valid_loss: 0.0119022 truth_loss: 0.16038223 epoch time: 1.426 s
best loss 0.092579775 save model
epoch: 1660 train loss: 0.09246021 ic_loss: 0.0006534874 data_loss: 0.008919277 phy_loss: 0.00069250836 valid_loss: 0.011887563 truth_loss: 0.16030973 epoch time: 1.389 s
best loss 0.09246021 save model
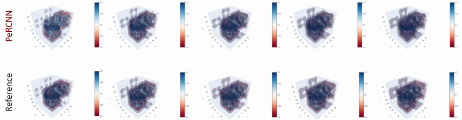
模型推理及可视化
完成训练后,下图展示了预测结果和真实标签的对比情况。