Inverse Navier-Stokes Problem
![]()
![]()
![]()
This notebook requires MindSpore version >= 2.0.0 to support new APIs including: mindspore.jit, mindspore.jit_class, mindspore.jacrev.
Overview
The Navier-Stokes equations are a set of partial differential equations describing the variation of fluid velocity and pressure in fluid mechanics.The inverse problem of Navier-Stokes is that of solving the fluid properties (e.g., viscosity, density, etc.) and fluid boundary conditions (e.g., wall friction, etc.) that can produce certain fluid motion characteristics (e.g., flow rate, velocity, etc.), given that these characteristics are known Problem. Unlike the positive problem (i.e., the fluid properties and boundary conditions are known and the kinematic characteristics of the fluid are solved), the solution of the inverse problem needs to be solved by numerical optimization and inverse extrapolation methods.
The inverse problem of Navier-Stokes has a wide range of applications in engineering and scientific computing, for example, in the fields of aviation, energy, geology, and biology, where it can be used to optimize fluid design, predict fluid motion, diagnose fluid problems, and so on. Although the inverse problem of Navier-Stokes is very challenging, some progress has been made in recent years with the development of computer technology and numerical methods. For example, the solution process of the inverse problem can be accelerated and the solution accuracy can be improved by using techniques such as high-performance computing and machine learning-based inverse projection methods.
Problem Description
In inverse Navier-Stokes problem, two parameters remain unknown, which is different from Navier-Stokes equation. The inverse Navier-Stokes problem has the following form:
where
In this case, the PINNs method is used to learn the mapping from the location and time to flow field quantities to solve the parameters .
Technology Path
The specific process of MindSpore Flow for solving the problem is as follows:
Training Dataset Construction.
Model Construction.
Optimizer.
InvNavierStokes.
Model Training.
Model Evaluation and Visualization.
[1]:
import time
import numpy as np
import mindspore
from mindspore import context, nn, ops, jit, set_seed, load_checkpoint, load_param_into_net
The following src package can be downloaded in applications/physics_driven/navier_stokes/cylinder_flow_inverse/src
[2]:
from mindflow.cell import MultiScaleFCSequential
from mindflow.utils import load_yaml_config
from mindflow.pde import sympy_to_mindspore, PDEWithLoss
from mindflow.loss import get_loss_metric
from src import create_training_dataset, create_test_dataset, calculate_l2_error
set_seed(123456)
np.random.seed(123456)
The following inverse_navier_stokes.yaml can be downloaded in applications/physics_driven/navier_stokes/cylinder_flow_inverse/configs/navier_stokes_inverse.yaml.
[3]:
# set context for training: using graph mode for high performance training with GPU acceleration
config = load_yaml_config('inverse_navier_stokes.yaml')
context.set_context(mode=context.GRAPH_MODE, device_target="GPU", device_id=0)
use_ascend = context.get_context(attr_key='device_target') == "Ascend"
Training Dataset Construction
In this case, training data and test data are sampled from raw data.
Download the training and test dataset: physics_driven/inverse_navier_stokes/dataset.
[4]:
# create dataset
inv_ns_train_dataset = create_training_dataset(config)
train_dataset = inv_ns_train_dataset.create_dataset(batch_size=config["train_batch_size"],
shuffle=True,
prebatched_data=True,
drop_remainder=True)
# create test dataset
inputs, label = create_test_dataset(config)
./inverse_navier_stokes/dataset
get dataset path: ./inverse_navier_stokes/dataset
check eval dataset length: (40, 100, 50, 3)
Model Construction
This example uses a simple fully-connected network with a depth of 6 layers and the activation function is the tanh function, each layer has 20 neurons.
[5]:
coord_min = np.array(config["geometry"]["coord_min"] + [config["geometry"]["time_min"]]).astype(np.float32)
coord_max = np.array(config["geometry"]["coord_max"] + [config["geometry"]["time_max"]]).astype(np.float32)
input_center = list(0.5 * (coord_max + coord_min))
input_scale = list(2.0 / (coord_max - coord_min))
model = MultiScaleFCSequential(in_channels=config["model"]["in_channels"],
out_channels=config["model"]["out_channels"],
layers=config["model"]["layers"],
neurons=config["model"]["neurons"],
residual=config["model"]["residual"],
act='tanh',
num_scales=1,
input_scale=input_scale,
input_center=input_center)
Optimizer
When constructing Optimizer, the two unknown parameters are added into the Optimizer, along with the parameters from the model.
[6]:
if config["load_ckpt"]:
param_dict = load_checkpoint(config["load_ckpt_path"])
load_param_into_net(model, param_dict)
theta = mindspore.Parameter(mindspore.Tensor(np.array([0.0, 0.0]).astype(np.float32)), name="theta", requires_grad=True)
params = model.trainable_params()
params.append(theta)
optimizer = nn.Adam(params, learning_rate=config["optimizer"]["initial_lr"])
Model Training
With MindSpore version >= 2.0.0, we can use the functional programming for training neural networks.
[8]:
def train():
problem = InvNavierStokes(model, params)
if use_ascend:
from mindspore.amp import DynamicLossScaler, auto_mixed_precision, all_finite
loss_scaler = DynamicLossScaler(1024, 2, 100)
auto_mixed_precision(model, 'O3')
def forward_fn(pde_data, train_points, train_label):
loss = problem.get_loss(pde_data, train_points, train_label)
if use_ascend:
loss = loss_scaler.scale(loss)
return loss
grad_fn = ops.value_and_grad(forward_fn, None, optimizer.parameters, has_aux=False)
@jit
def train_step(pde_data, train_points, train_label):
loss, grads = grad_fn(pde_data, train_points, train_label)
if use_ascend:
loss = loss_scaler.unscale(loss)
if all_finite(grads):
grads = loss_scaler.unscale(grads)
loss = ops.depend(loss, optimizer(grads))
else:
loss = ops.depend(loss, optimizer(grads))
return loss
epochs = config["train_epochs"]
steps_per_epochs = train_dataset.get_dataset_size()
sink_process = mindspore.data_sink(train_step, train_dataset, sink_size=1)
param1_hist = []
param2_hist = []
for epoch in range(1, 1 + epochs):
# train
time_beg = time.time()
model.set_train(True)
for _ in range(steps_per_epochs):
step_train_loss = sink_process()
print(f"epoch: {epoch} train loss: {step_train_loss} epoch time: {(time.time() - time_beg) * 1000 :.3f} ms")
model.set_train(False)
if epoch % config["eval_interval_epochs"] == 0:
print(f"Params are{params[-1].value()}")
param1_hist.append(params[-1].value()[0])
param2_hist.append(params[-1].value()[1])
calculate_l2_error(model, inputs, label, config)
[9]:
start_time = time.time()
train()
print("End-to-End total time: {} s".format(time.time() - start_time))
momentum_x: theta1*u(x, y, t)*Derivative(u(x, y, t), x) + theta1*v(x, y, t)*Derivative(u(x, y, t), y) - theta2*Derivative(u(x, y, t), (x, 2)) - theta2*Derivative(u(x, y, t), (y, 2)) + Derivative(p(x, y, t), x) + Derivative(u(x, y, t), t)
Item numbers of current derivative formula nodes: 6
momentum_y: theta1*u(x, y, t)*Derivative(v(x, y, t), x) + theta1*v(x, y, t)*Derivative(v(x, y, t), y) - theta2*Derivative(v(x, y, t), (x, 2)) - theta2*Derivative(v(x, y, t), (y, 2)) + Derivative(p(x, y, t), y) + Derivative(v(x, y, t), t)
Item numbers of current derivative formula nodes: 6
continuty: Derivative(u(x, y, t), x) + Derivative(v(x, y, t), y)
Item numbers of current derivative formula nodes: 2
velocity_u: u(x, y, t)
Item numbers of current derivative formula nodes: 1
velocity_v: v(x, y, t)
Item numbers of current derivative formula nodes: 1
p: p(x, y, t)
Item numbers of current derivative formula nodes: 1
epoch: 100 train loss: 0.04028289 epoch time: 2229.404 ms
Params are[-0.09575531 0.00106778]
predict total time: 652.7423858642578 ms
l2_error, U: 0.17912744544874443 , V: 1.0003739133641472 , P: 0.7065071079210473 , Total: 0.3464922229721188
==================================================================================================
epoch: 200 train loss: 0.036820486 epoch time: 1989.347 ms
Params are[-0.09443577 0.00024772]
predict total time: 205.59978485107422 ms
l2_error, U: 0.17490993243690725 , V: 1.0000642916277709 , P: 0.7122513574462407 , Total: 0.3447007384838206
==================================================================================================
epoch: 300 train loss: 0.038683612 epoch time: 2111.895 ms
Params are[-0.08953815 0.00040177]
predict total time: 222.2282886505127 ms
l2_error, U: 0.17713679346188396 , V: 1.000105316860139 , P: 0.718292536660169 , Total: 0.34596943008999737
==================================================================================================
Params are[-0.08414971 0.00108538]
predict total time: 183.55488777160645 ms
l2_error, U: 0.17421055947839162 , V: 1.0021844256262489 , P: 0.7172107774589106 , Total: 0.34508045682750343
... ...
epoch: 9700 train loss: 0.00012139356 epoch time: 1816.661 ms
Params are[0.9982705 0.01092069]
predict total time: 126.16825103759766 ms
l2_error, U: 0.010509542864484654 , V: 0.023635759087951035 , P: 0.029506766787788633 , Total: 0.012708719069239902
==================================================================================================
epoch: 9800 train loss: 0.00013328926 epoch time: 1790.342 ms
Params are[0.9984688 0.01081933]
predict total time: 121.35672569274902 ms
l2_error, U: 0.009423471629415427 , V: 0.034303037318821124 , P: 0.03254805487768195 , Total: 0.01400324770722587
==================================================================================================
epoch: 9900 train loss: 0.00013010873 epoch time: 1805.052 ms
Params are[0.9978893 0.01079915]
predict total time: 125.68926811218262 ms
l2_error, U: 0.009608467956285763 , V: 0.02630037021521753 , P: 0.029346654211944684 , Total: 0.012485673337358347
==================================================================================================
epoch: 10000 train loss: 0.00010107973 epoch time: 1809.868 ms
Params are[0.9984444 0.01072927]
predict total time: 132.6577663421631 ms
l2_error, U: 0.008157992439025805 , V: 0.022894215240181922 , P: 0.028113136535916225 , Total: 0.010848400336992805
==================================================================================================
End-to-End total time: 27197.875846385956 s
Model Evaluation and Visualization
After training, all data points in the flow field can be inferred. And related results can be visualized.
[15]:
from src import visual
# visualization
visual(model=model, epochs=config["train_epochs"], input_data=inputs, label=label)
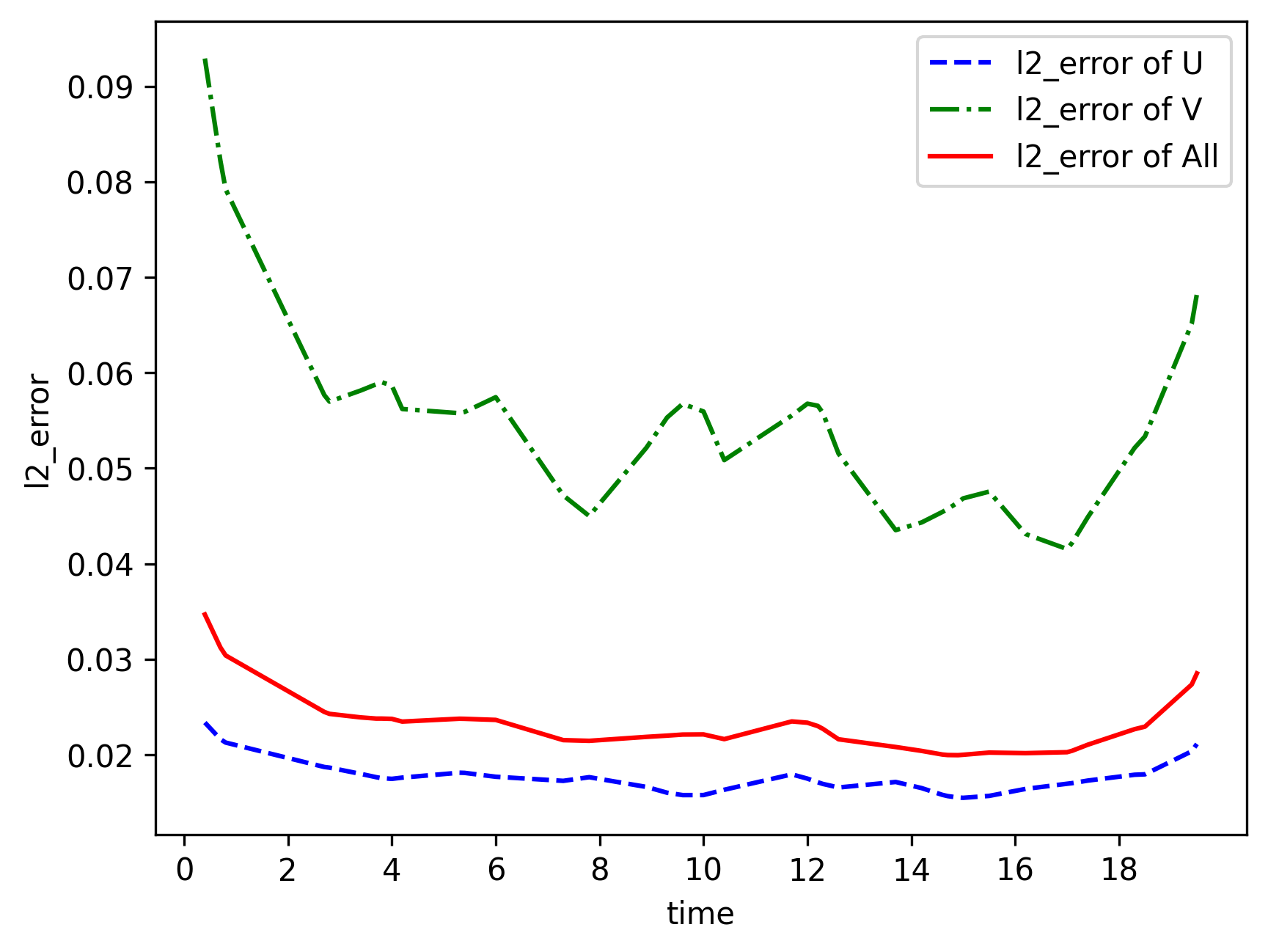
[1]:
from src import plot_params
plot_params(param1_hist, param2_hist)
[1]:
Text(0, 0.5, 'value')
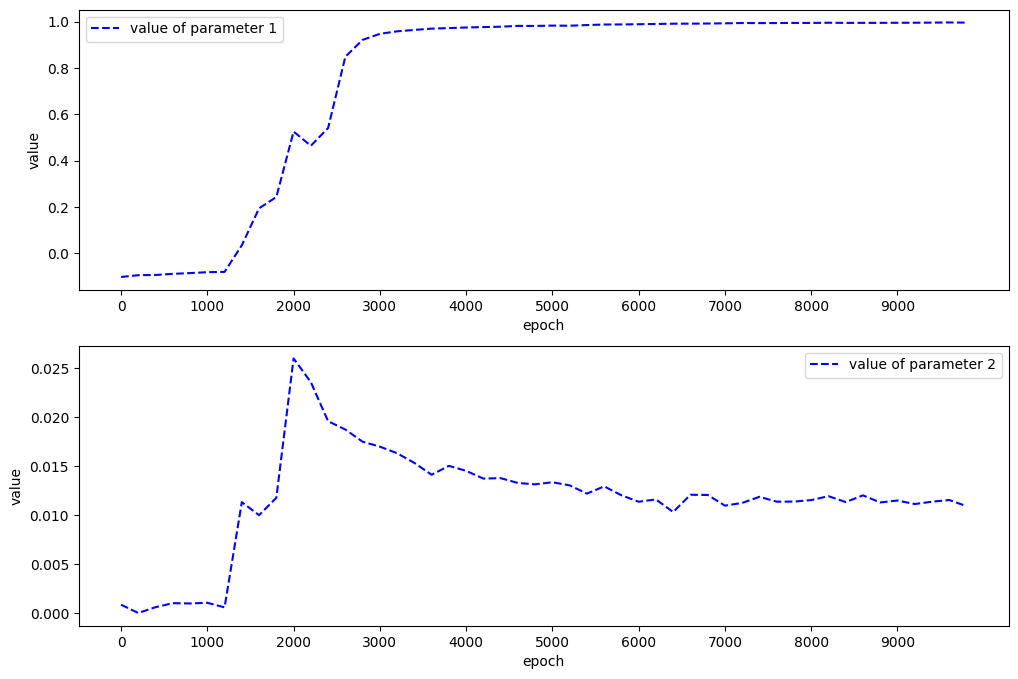
In this case, the standard value for
Correct PDE:
Identified PDE:
