 文档反馈
文档反馈数据处理概述
![]()
![]()
![]()
MindSpore Dataset 提供两种数据处理能力:数据处理Pipeline模式和数据处理轻量化模式。
数据处理Pipeline模式:提供基于C++ Runtime的并发数据处理流水线(Pipeline)能力。用户通过定义数据集加载、数据变换、数据批处理(Batch)等流程,实现数据集的高效加载、高效处理、高效Batch。并发度可调、缓存可调等能力,实现为NPU卡训练提供零Bottle Neck的训练数据。
数据处理轻量化模式:支持用户使用数据变换操作(如:Resize、Crop、HWC2CHW等)进行单个样本的数据处理。
本章节后续重点讲述两种数据处理模式。
数据处理Pipeline模式
用户通过API定义的Dataset流水线,运行训练进程后Dataset会从数据集中循环加载数据 -> 处理 -> Batch -> 迭代器,最终用于训练。
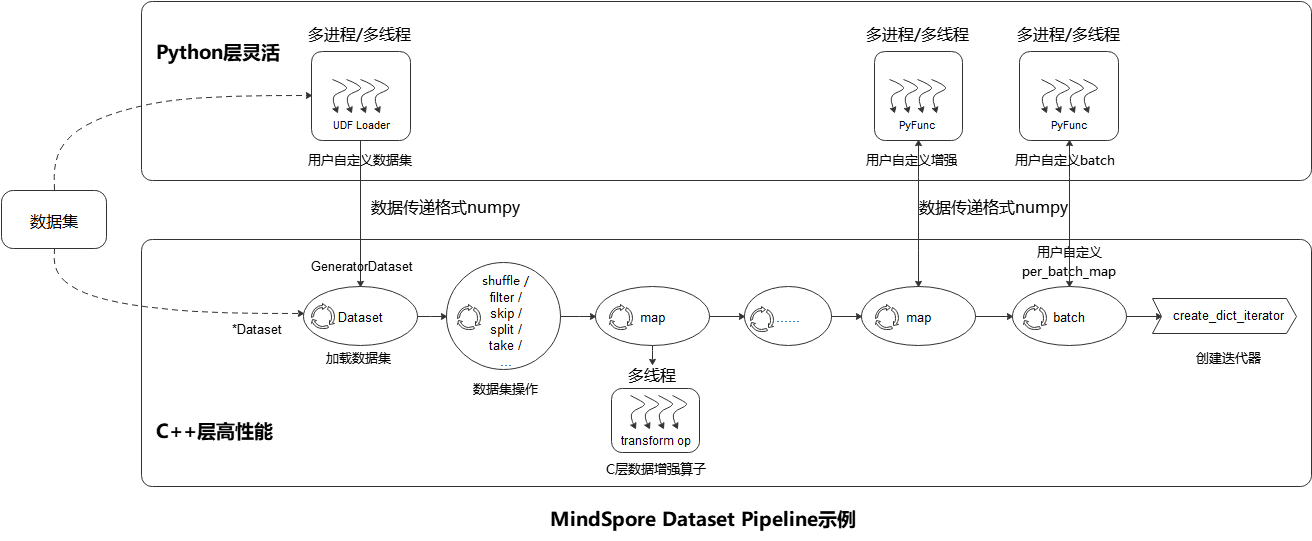
如上图所示,MindSpore Dataset模块使得用户很简便地定义数据预处理Pipeline,并以最高效(多进程/多线程)的方式处理数据集中样本,具体的步骤参考如下:
数据集加载(Dataset):用户可以方便地使用Dataset类 (标准格式数据集、vision数据集、nlp数据集、audio数据集) 来加载已支持的数据集,或者通过 UDF Loader + GeneratorDataset 自定义数据集 实现Python层自定义数据集的加载。加载类方法可以使用多种Sampler、数据分片、数据shuffle等功能;
数据集操作(filter/ skip):用户通过数据集对象方法 .shuffle / .filter / .skip / .split / .take / … 来实现数据集的进一步混洗、过滤、跳过、最多获取条数等操作;
数据集样本变换操作(map):用户可以将数据变换操作 (vision数据变换 , nlp数据变换 , audio数据变换 ) 添加到map操作中执行,数据预处理过程中可以定义多个map操作,用于执行不同变换操作。数据变换操作也可以是用户自定义变换的 PyFunc ;
批(batch):用户在样本完成变换后,使用 .batch 操作将多个样本组织成batch,也可以通过batch的参数 per_batch_map 来自定义batch逻辑;
迭代器(create_dict_iterator):最后用户通过数据集对象方法 .create_dict_iterator / .create_tuple_iterator 来创建迭代器将预处理完成的数据循环输出。
数据集加载
下面主要介绍单个数据集加载、数据集组合、数据集切分、数据集保存等常用数据集加载方式。
单个数据集加载
数据集加载类用于实现本地磁盘、OBS和共享存储上的训练数据集加载,将存储上的数据集Load至内存中。数据集加载接口如下:
数据集接口分类 |
API列表 |
说明 |
|---|---|---|
标准格式数据集 |
其中 MindDataset 依赖 MindSpore 数据格式, 详见: 格式转换 |
|
自定义数据集 |
其中 GeneratorDataset 负责加载用户自定义DataLoader, 详见: 自定义数据集 |
|
常用数据集 |
ImageFolderDataset 、 Cifar10Dataset 、 IWSLT2017Dataset 、 LJSpeechDataset 等 |
用于常用的开源数据集 |
以上数据集加载(示例)中,可以配置不同的参数,以实现不同的加载效果,常用参数举例如下:
columns_list:过滤数据集中指定的列,仅针对部分数据集接口。默认值:None,加载所有数据列。num_parallel_workers:配置数据集的读取并发数。默认值:8。通过参数配置数据集的采样逻辑:
shuffle:开启混洗。默认值:True。num_shards和shard_id:对数据集进行分片。默认值:None,不分片。其他更多的采样逻辑可以参考:数据采样。
数据集组合
数据集组合可以将多个数据集以串联/并朕的方式组合起来,形成一个全新的dataset对象。
串联多个数据集
[27]:
import mindspore.dataset as ds
ds.config.set_seed(1234)
data = [1, 2, 3]
dataset1 = ds.NumpySlicesDataset(data=data, column_names=["column_1"])
data = [4, 5, 6]
dataset2 = ds.NumpySlicesDataset(data=data, column_names=["column_1"])
dataset = dataset1.concat(dataset2)
for item in dataset.create_dict_iterator():
print(item)
{'column_1': Tensor(shape=[], dtype=Int32, value= 3)}
{'column_1': Tensor(shape=[], dtype=Int32, value= 2)}
{'column_1': Tensor(shape=[], dtype=Int32, value= 1)}
{'column_1': Tensor(shape=[], dtype=Int32, value= 6)}
{'column_1': Tensor(shape=[], dtype=Int32, value= 5)}
{'column_1': Tensor(shape=[], dtype=Int32, value= 4)}
并联多个数据集
[28]:
import mindspore.dataset as ds
ds.config.set_seed(1234)
data = [1, 2, 3]
dataset1 = ds.NumpySlicesDataset(data=data, column_names=["column_1"])
data = [4, 5, 6]
dataset2 = ds.NumpySlicesDataset(data=data, column_names=["column_2"])
dataset = dataset1.zip(dataset2)
for item in dataset.create_dict_iterator():
print(item)
{'column_1': Tensor(shape=[], dtype=Int32, value= 3), 'column_2': Tensor(shape=[], dtype=Int32, value= 6)}
{'column_1': Tensor(shape=[], dtype=Int32, value= 2), 'column_2': Tensor(shape=[], dtype=Int32, value= 5)}
{'column_1': Tensor(shape=[], dtype=Int32, value= 1), 'column_2': Tensor(shape=[], dtype=Int32, value= 4)}
数据集切分
将数据集切分成训练数据集和验证数据集,分别用于训练过程和验证过程。
[29]:
import mindspore.dataset as ds
data = [1, 2, 3, 4, 5, 6]
dataset = ds.NumpySlicesDataset(data=data, column_names=["column_1"], shuffle=False)
train_dataset, eval_dataset = dataset.split([4, 2])
print(">>>> train dataset >>>>")
for item in train_dataset.create_dict_iterator():
print(item)
>>>> train dataset >>>>
{'column_1': Tensor(shape=[], dtype=Int32, value= 5)}
{'column_1': Tensor(shape=[], dtype=Int32, value= 2)}
{'column_1': Tensor(shape=[], dtype=Int32, value= 6)}
{'column_1': Tensor(shape=[], dtype=Int32, value= 1)}
[30]:
print(">>>> eval dataset >>>>")
for item in eval_dataset.create_dict_iterator():
print(item)
>>>> eval dataset >>>>
{'column_1': Tensor(shape=[], dtype=Int32, value= 3)}
{'column_1': Tensor(shape=[], dtype=Int32, value= 4)}
数据集保存
将数据集重新保存到MindRecord数据格式。
[31]:
import os
import mindspore.dataset as ds
ds.config.set_seed(1234)
data = [1, 2, 3, 4, 5, 6]
dataset = ds.NumpySlicesDataset(data=data, column_names=["column_1"])
if os.path.exists("./train_dataset.mindrecord"):
os.remove("./train_dataset.mindrecord")
if os.path.exists("./train_dataset.mindrecord.db"):
os.remove("./train_dataset.mindrecord.db")
dataset.save("./train_dataset.mindrecord")
数据变换
普通数据变换
用户可以使用多种数据变换操作:
.map(...):变换操作。.filter(...):过滤操作。.project(...):对多列进行排序和过滤。.rename(...)对指定列重命名。.shuffle(...)对数据进行缓存区大小的混洗。.skip(...)跳过数据集的前 n 条。.take(...)只读数据集的前 n 条样本。
下面重点说明 .map(...) 的使用方法:
在
.map(...)中使用Dataset提供的数据变换操作Dataset提供了丰富的数据变换操作,这些数据变换操作可以直接放在
.map(...)中使用。具体使用方法参考 map变换操作。在
.map(...)中使用自定义数据变换操作Dataset也支持用户自定义的数据变换操作,仅需将用户自定义函数传递给
.map(...)退可。具体使用方法参考:自定义map变换操作。在
.map(...)中返回Dict数据结构数据Dataset也支持在用户自定义的数据变换操作中返回Dict数据结构,使得定义的数据变换更加灵活。具体使用方法参考:自定义map变换操作处理字典对象。
自动数据增强
除了以上的普通数据变换,Dataset 还提供了一种自动数据变换方式,可以基于特定策略自动对图像进行数据变换处理。详细说明见:自动数据增强。
数据batch
Dataset提供 .batch(...) 操作,可以很方便的将数据变换操作后的样本组织成batch。有两种使用方式:
默认
.batch(...)操作,将batch_size个样本组织成shape为 (batch_size, …)的数据,详细用法请参考 batch操作;自定义
.batch(..., per_batch_map, ...)操作,支持用户将 [np.ndarray, nd.ndarray, …] 多条数据按照自定义逻辑组织batch,详细用法请参考 自定义batch操作。
数据集迭代器
用户在定义完成 数据集加载(xxDataset)-> 数据处理(.map)-> 数据batch(.batch) Dataset流水线(Pipeline)后,可以通过创建迭代器方法 .create_dict_iterator(...) / .create_tuple_iterator(...) 循环将数据输出。具体的使用方法参考:数据集迭代器。
性能优化
数据处理性能优化
针对数据处理Pipeline性能不足的场景,可以参考数据处理性能优化来进一步优化性能,以满足训练端到端性能要求。
单节点数据缓存
另外,对于推理场景,为了追求极致的性能,可以使用 单节点数据缓存 将数据集缓存于本地内存中,以加速数据集的读取和预处理。
数据处理轻量化模式
用户可以直接使用数据变换操作处理一条数据,返回值即是数据变换的结果。
数据变换操作(vision数据变换 , nlp数据变换 , audio数据变换 )可以像调用普通函数一样直接来使用。常见用法是:先初始化数据变换对象,然后调用数据变换操作方法,传入需要处理的数据,最后得到处理的结果。
[32]:
from download import download
from PIL import Image
import mindspore.dataset.vision as vision
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/banana.jpg"
download(url, './banana.jpg', replace=True)
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/banana.jpg (17 kB)
file_sizes: 100%|██████████████████████████| 17.1k/17.1k [00:00<00:00, 8.55MB/s]
Successfully downloaded file to ./banana.jpg
[32]:
'./banana.jpg'
[33]:
img_ori = Image.open("banana.jpg").convert("RGB")
print("Image.type: {}, Image.shape: {}".format(type(img_ori), img_ori.size))
Image.type: <class 'PIL.Image.Image'>, Image.shape: (356, 200)
[34]:
# Apply Resize to input immediately
resize_op = vision.Resize(size=(320))
img = resize_op(img_ori)
print("Image.type: {}, Image.shape: {}".format(type(img), img.size))
Image.type: <class 'PIL.Image.Image'>, Image.shape: (569, 320)
更多的示例请参考:轻量化数据处理
