优化器并行
![]()
概述
在进行数据并行训练时,模型的参数更新部分在各卡间存在冗余计算。通过优化器并行,将优化器的计算量分散到数据并行维度的卡上,实现在大规模网络上(比如Bert、GPT)有效减少内存消耗并提升网络性能。
在自动并行(AUTO_PARALLEL)或者半自动并行(SEMI_AUTO_PARALLEL)模式下使能优化器并行时,如果经过策略切分后的参数在各卡间存在重复切片,并且shape的最高维可以被重复切片的卡数整除,框架会以最小切片的方式保存参数,并在优化器中更新。该模式下支持所有优化器。
并行模式 |
参数更新方式 |
优化器支持 |
后端支持 |
|---|---|---|---|
自动/半自动并行 |
参数按数据并行度切分成N份,每张卡更新当前卡上的参数 |
所有优化器 |
Ascend、GPU |
无论是哪种模式,优化器并行不会影响原有正反向网络的计算图,只会影响参数更新的计算量和计算逻辑。
优化器并行模型支持的硬件平台包括Ascend、GPU,需要在Graph模式下运行。
相关接口:
mindspore.parallel.auto_parallel.AutoParallel(network, parallel_mode="semi_auto"):通过静态图并行封装指定并行模式,其中network是待封装的顶层Cell或函数,parallel_mode取值semi_auto,表示半自动并行模式。该接口返回封装后包含并行配置的Cell。mindspore.parallel.auto_parallel.AutoParallel.hsdp(shard_size=-1, threshold=64, optimizer_level="level1"):通过该接口设置优化器并行的配置,并开启优化器并行。其中shard_size指定优化器权重切分通信域的大小。threshold表示切分参数时,要求目标参数所占内存的最小值。当目标参数小于该值时,将不会被切分。optimizer_level是优化器切分级别,当级别为level1时,对权重和优化器状态进行切分;当级别为level2时,对权重、优化器状态和梯度进行切分;当级别为level3时,除了对权重、优化器状态和梯度进行切分外,在反向传播前,还会对权重进行all gather通信,以释放前向传播allgather占用的内存。mindspore.nn.Cell.set_comm_fusion(fusion_type=NUM):在自动/半自动模式下,每个参数都会产生一个对应的AllGather操作和ReduceScatter操作。这些通信算子是自动并行框架自动插入的。然而,随着参数量增多,对应的通信算子也会增多,通信操作中的算子调度和启动都会产生更多的开销。因此,可以通过Cell提供的set_comm_fusion方法,手动对每个Cell内参数对应的AllGather和ReduceScatter操作配置融合标记NUM,以提高通信效率。MindSpore将融合相同NUM参数对应的通信算子,以减少通信开销。
基本原理
传统的数据并行模式中,每台设备上都保存了模型参数副本,把训练数据切分,在每次迭代后利用通信算子同步梯度信息,最后通过优化器计算更新参数。这种模式虽然能够有效提升训练吞吐量,但优化器会引入冗余内存和计算,无法最大限度地利用机器资源。因此,我们需重点关注如何消除优化器的冗余内存和计算。
在一个训练迭代中,数据并行为了收集各卡上不同样本产生的参数梯度,在多卡间引入通信操作进行同步。由于不涉及模型并行,每张卡上的优化器运算其实是基于相同的参数、在相同的方向上更新。因此消除优化器冗余的关键就是将这部分内存和计算量分散到各个卡上,实现内存和性能的收益。
对优化器实现并行运算有两种实现思路:参数分组(Weights Grouping)和参数切分(Weights Sharding)。
其中参数分组是将优化器内的参数及梯度做层间划分,大致的训练流程如图1所示。将参数和梯度分组放到不同卡上更新,再通过通信广播操作,在设备间共享更新后的权值。该方案的内存和性能收益取决于参数比例最大的group。当参数均匀划分时,理论上的正收益是N-1/N的优化器运行时间和动态内存,以及N-1/N的优化器状态参数内存大小,其中N表示设备数。而引入的负收益是共享网络权重时带来的通信时间。
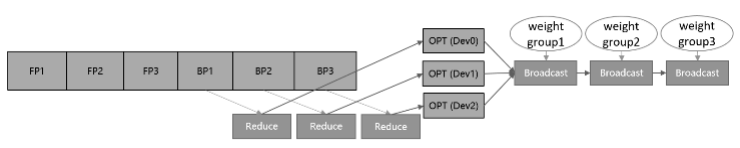
图1:参数分组训练流程示意图
另一种实现方式是参数切分,即对参数做层内划分,据设备号对每一个参数及梯度根取对应切片,各自更新后再调用通信聚合操作,在设备间共享参数。这种方案的优点是天然支持负载均衡,即每张卡上参数量和计算量一致,缺点是对参数形状有整除设备数要求。该方案的理论收益与参数分组一致,为了扩大优势,框架做了如下几点改进:
首先,对网络中的权重做切分,可以进一步减少静态内存。但这也需要将迭代末尾的共享权重操作移动到下一轮迭代的正向启动前执行,保证进入正反向运算的依旧是原始张量形状。
此外,优化器并行运算带来的主要负收益是共享权重的通信时间,如果我们能够将其减少或隐藏,就可以带来性能上的提升。通信跨迭代执行的一个好处就是,可以通过对通信算子适当分组融合,将通信操作与正向网络交叠执行,从而尽可能隐藏通信耗时。通信耗时还与通信量有关,对于涉及混合精度的网络,如果能够使用fp16通信,通信量相比fp32将减少一半。
综合上述特点,参数切分的实现方案如图2所示。
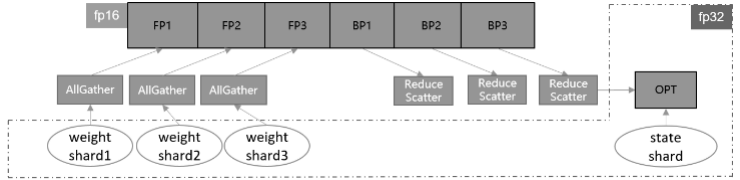
图2:参数切分训练流程示意图
在实际网络训练的测试验证中,我们发现参数切分带来的内存收益是显著的。尤其是对于大规模网络模型而言,通常选择当下流行的Adaptive Moment estimation (Adam)和Layer-wise Adaptive Moments optimizer for Batching training (LAMB)训练网络,优化器自身的参数量和计算量不容忽视。经过参数分组,网络中的权重参数和优化器中的两份状态参数都减少了N-1/N倍,极大节省了静态内存空间。这为增大单轮迭代样本数量、提升整体训练吞吐量提供了可能,有效解决了大规模网络训练的内存压力。
MindSpore实现的优化器参数切分还具有与算子级并行混合使用的优势。当算子级模型并行参数未切满时,可以继续在数据并行的维度上进行优化器参数切分,增大机器资源的利用率,从而提升端到端性能。