 文档反馈
文档反馈构图
![]()
![]()
![]()
MindSpore提供JIT(just-in-time)技术来进行性能优化。JIT模式会通过AST树解析、Python字节码解析或追踪代码执行的方式,将代码解析为一张中间表示图(IR,intermediate representation)。IR图作为该代码的唯一表示,编译器通过对该IR图的优化,来达到对代码的优化,提高运行性能。与动态图模式相对应,这种JIT的编译模式被称为静态图模式。
基于JIT技术,MindSpore提供了动静结合的方法来提高用户的网络的运行效率。动静结合,即在整体运行为动态图的情况下,指定某些代码块以静态图的方式运行。按照静态图方式运行的代码块会采取先编译后执行的运行模式,在编译期对代码进行全局优化,来获取执行期的性能收益。用户可以通过@jit装饰器修饰函数,来指定其按照静态图的模式执行。有关@jit装饰器的相关文档请见jit API文档。
MindSpore提供了三种JIT编译方式,分别通过ast、bytecode和trace的方式来构图。ast是通过AST树解析的方式,将用户手工标识需要按照ast方式执行的函数转换成静态图。bytecode则是通过对Python字节码的解析,在动态图中尽可能的构建静态图,无法转换为静态图的部分则会按照动态图进行执行,来达到动静结合的目的。trace是通过追踪Python代码执行的轨迹来构建静态图,当前属于实验性质的特性。后续介绍会详细说明三者原理的不同以及各自的特点。
Ast
在动态图模式下,用户可以通过@jit(capture_mode="ast")装饰器修饰函数来让该函数以ast方式来执行。用ast方式修饰的函数,其内部使用的语法以及数据结构需要遵守静态图语法规范静态图语法规范。ast方式通过源到源的方式来编译Python代码,先把模型定义的Python源码解析成抽象语法树,然后把抽象语法树解析为MindIR。例如下面的Python代码:
@jit
def foo(x, y):
z = x + y
return z
它对应的抽象语法树如下:
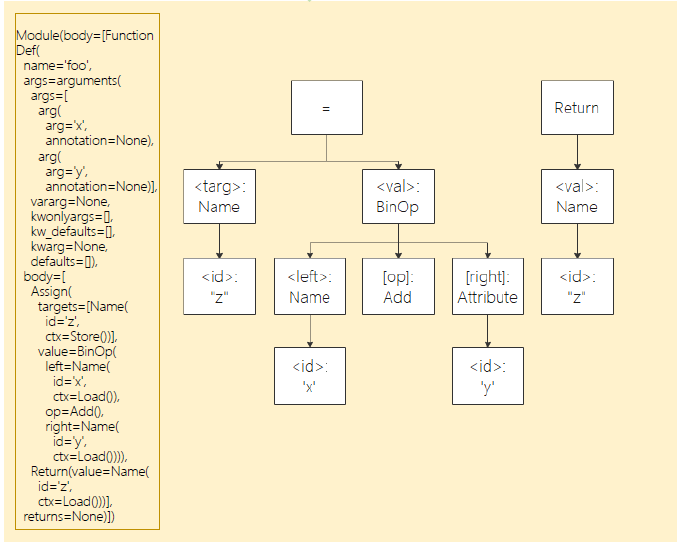
通过解析上面的抽象语法树,我们得到下面的MindIR:
%para1_x: <Tensor[Int64], ()>
%para2_y: <Tensor[Int64], ()>
subgraph instance: foo
subgraph @foo() {
%0(CNode_17) = PrimFunc_Add(%para1_x, %para2_y)
: (<Tensor[Int64], ()>, <Tensor[Int64], ()>) -> (<Tensor[Int64], ()>)
Return(%0)
: (<Tensor[Int64], ()>)
}
ast的使用方法:
用户可以通过@jit装饰器来指定函数以静态图的方式来执行,例如:
[1]:
import numpy as np
import mindspore as ms
from mindspore import ops
from mindspore import jit
from mindspore import Tensor
@jit
def tensor_cal(x, y, z):
return ops.matmul(x, y) + z
x = Tensor(np.ones(shape=[2, 3]), ms.float32)
y = Tensor(np.ones(shape=[3, 4]), ms.float32)
z = Tensor(np.ones(shape=[2, 4]), ms.float32)
ret = tensor_cal(x, y, z)
print(ret)
[[4. 4. 4. 4.]
[4. 4. 4. 4.]]
上述用例中,tensor_cal函数被@jit装饰器修饰,该函数被调用时就会按照静态图的模式进行执行,以获取该函数执行期的性能收益。
ast的优点:
使用ast模式,用户的编程自主性更强,性能优化更精准,可以根据函数特征以及使用经验将网络的性能调至最优。
ast的限制:
ast修饰的函数,其内部的语法必须严格遵守静态图语法来进行编程。
ast模式的使用建议:
相比于动态图执行,被
@jit修饰的函数,在第一次调用时需要先消耗一定的时间进行静态图的编译。在该函数的后续调用时,若原有的编译结果可以复用,则会直接使用原有的编译结果进行执行。因此,使用@jit装饰器修饰会多次执行的函数通常会获得更多的性能收益。静态图模式的运行效率优势体现在其会将被@jit修饰函数进行全局上的编译优化,函数内含有的操作越多,优化的上限也就越高。因此
@jit装饰器修饰的函数最好是内含操作很多的大代码块,而不应将很多细碎的、仅含有少量操作的函数分别打上jit标签。否则,则可能会导致性能没有收益甚至劣化。MindSpore静态图绝大部分计算以及优化都是基于对Tensor计算的优化,因此我们建议被修饰的函数应该是那种用来进行真正的数据计算的函数,而不是一些简单的标量计算或者数据结构的变换。
被
@jit修饰的函数,若其输入存在常量,那么该函数每次输入值的变化都会导致重新编译,关于变量常量的概念请见即时编译下的常量与变量。因此,建议被修饰的函数以Tensor或者被Mutable修饰的数据作为输入。避免因多次编译导致的额外性能损耗。
Bytecode
除了ast,MindSpore提供另外一种静态化加速机制bytecode,用户可以通过@jit(capture_mode="bytecode")装饰器修饰函数来让该函数以bytecode模式来执行。当bytecode识别到不支持进入静态图的语法时,会回退到Python执行而非直接编译报错。该功能同时兼顾性能和易用性,减少编译报错的发生。它基于Python字节码的分析,对Python的执行流进行图捕获,让可以以静态图方式运行的子图以静态图方式运行,并让Python语法不支持的子图以动态图方式运行,同时通过修改调整字节码的方式链接动静态图,达到动静混合执行。在满足易用性的前提下,尽可能地提高性能。
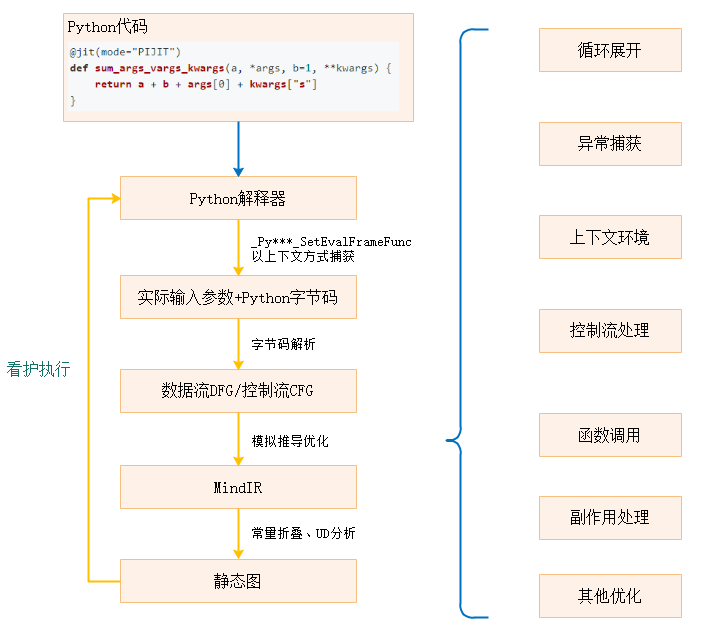
bytecode的运行原理:
基于Python虚拟机_PyInterpreterState_SetEvalFrameFunc捕获Python函数的执行,采用上下文管理的方式捕获执行区域内的所有Python函数执行。
按照当前的运行时输入参数结合函数字节码进行分析,构造控制流图(CFG)以及数据流图(DFG)。
模拟进栈出栈操作,跟踪逐个字节码,根据栈输入,推导输出。Python3.7~Python3.10每条字节码都有对应的模拟实现,注意是推导输出的类型尺寸,而不是真正执行得到值,除非常量折叠。
在模拟执行字节码的过程中,将推导结果和操作翻译成MindIR,最后,通过常量折叠,UD分析(删除无用的输入输出参数)等方式,优化静态图。
在执行等效的静态图之前,对输入参数和优化过程中产生的看护Guard条件进行比对,根据运行时信息,选择匹配的静态图执行。
动态管理看护Guard和静态图缓冲的匹配关系,对不常用的静态图缓冲进行回收,通过Symbolic Shape和Dynamic Shape优化静态图缓冲。
bytecode的编译流程如下图所示
bytecode的使用方式:
将jit的capture_mode参数设置为bytecode,即可将修饰函数的运行模式切换为bytecode,例如:
[1]:
import numpy as np
import mindspore as ms
from mindspore import ops
from mindspore import jit
from mindspore import Tensor
@jit(capture_mode="bytecode")
def tensor_cal(x, y, z):
return ops.matmul(x, y) + z
x = Tensor(np.ones(shape=[2, 3]), ms.float32)
y = Tensor(np.ones(shape=[3, 4]), ms.float32)
z = Tensor(np.ones(shape=[2, 4]), ms.float32)
ret = tensor_cal(x, y, z)
print(ret)
[[4. 4. 4. 4.]
[4. 4. 4. 4.]]
bytecode的优点:
用户体验好,无需人工介入,用户编写的网络代码总是能够正常运行,静态图不能执行的代码会自动采用动态图运行。
bytecode可以通过对字节码的变换,使得更多的语句进入静态图。用户无需感知或修改代码。
bytecode的限制:
用户无法明确对某些代码做性能加速,对于裂图较多的场景,性能加速的效果可能会不明显。
Trace
MindSpore也提供另外一种静态化加速机制trace,用户可以通过@jit(capture_mode="trace")装饰器修饰函数来让该函数以trace模式来执行。在该模式下,代码会先以PyNative模式运行,在运行时调用的算子会被记录,并被捕获到计算图中。在后续执行该装饰器修饰的代码时,会直接执行第一次执行所构造出的计算图。该功能不会解析语法,只会捕获运行时调用的算子,因此不会有语法不支持报错的发生。它基于捕获运行PyNative模式时调用的算子,对Python的执行流进行图捕获,将捕获到的算子编入计算图中。没有对应算子的操作将无法生成节点,trace流程将只捕获该操作的返回值,在计算图中作为常量。生成的计算图以静态图的运行方式运行。
trace的使用方式:
将jit的capture_mode参数设置为trace,即可将修饰函数的运行模式切换为Trace,例如:
[1]:
import numpy as np
import mindspore as ms
from mindspore import ops
from mindspore import jit
from mindspore import Tensor
@jit(capture_mode="trace")
def tensor_cal(x, y, z):
return ops.matmul(x, y) + z
x = Tensor(np.ones(shape=[2, 3]), ms.float32)
y = Tensor(np.ones(shape=[3, 4]), ms.float32)
z = Tensor(np.ones(shape=[2, 4]), ms.float32)
ret = tensor_cal(x, y, z)
print(ret)
[[4. 4. 4. 4.]
[4. 4. 4. 4.]]
trace的优点:
构图能力强,只要代码有对应算子就能够入图,不需要额外适配。构建静态图时不会有语法不支持报错。
用户体验好,无需人工介入,用户编写的网络代码总是能够正常运行。
trace的限制:
无法感知控制流,多次运行时控制流会进入不同分支的场景无法保证正确性。
没有定义为算子的操作,如第三方库会在计算图中被固定为常量,多次运行无法保证正确性。
