MindRecord Format Conversion
![]()
In MindSpore, the dataset used to train the network model can be converted into MindSpore-specific data format (MindSpore Record), making it easier to save and load data. The goal is to normalize the user’s dataset and further enable the reading of the data through the mindspore.dataset.MindDataset interface and use it during the training process.

In addition, the performance of MindSpore in some scenarios is optimized, and using the MindSpore Record data format can reduce disk IO and network IO overhead, which results in a better user experience.
The MindSpore data format has the following features:
Unified storage and access of user data are implemented: simplifying training data loading.
Aggregated data storage and efficient readout: makes data easy to manage and move during training.
Efficient data encoding and decoding: transparent to users.
The partition size is flexibly controlled: implement distributed training.
Record File Structure
As shown in the following figure, a MindSpore Record file consists of a data file and an index file.
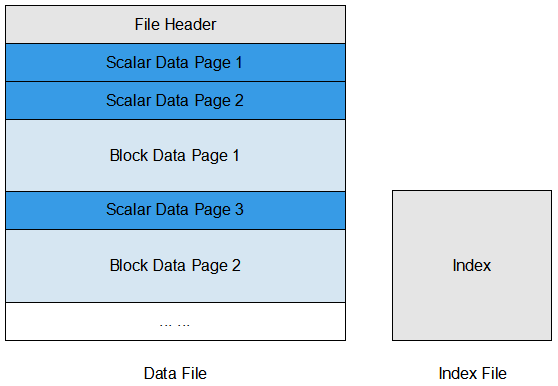
The data file contains file headers, scalar data pages, and block data pages, which are used to store the training data after user normalization. The specific purposes are as follows:
File header: the meta information of MindSpore Record file, which is mainly used to store file header size, scalar data page size, block data page size, Schema information, index field, statistics, file segment information, the correspondence between scalar data and block data, etc.
Scalar data page: mainly used to store integer, string, floating-point data, such as the Label of the image, the file name of the image, the length and width of the image, that is, the information suitable for storing with scalars will be saved here.
Block data page: mainly used to store binary strings, NumPy arrays and other data, such as binary image files themselves, dictionaries converted into text, etc.
The index file contains index information generated based on scalar data (such as image Label, image file name) for convenient retrieval and statistical dataset information.
A single MindSpore Record file is recommended to be less than 20G. Users can slice and dice large data sets to store them as multiple MindSpore Record files.
It should be noted that neither the data files nor the index files can support renaming operations at this time.
Converting Dataset to Record Format
The following mainly describes how to convert CV class data and NLP class data to MindSpore Record file format and how to read MindSpore Record file through the MindDataset interface.
Converting CV Class Data
This example mainly uses a CV dataset containing 100 records and converts it to MindSpore Record format as an example, and describes how to convert a CV class dataset to the MindSpore Record file format and read it through the MindDataset interface.
Specifically, you need to create a dataset of 100 pictures and save it, whose sample contains three fields: file_name (string), label (integer), and data (binary), and then use the MindDataset interface to read the MindSpore Record file.
Generate 100 images and convert them to MindSpore Record format file.
[1]:
from PIL import Image
from io import BytesIO
from mindspore.mindrecord import FileWriter
file_name = "test_vision.mindrecord"
# Define the contained fields
cv_schema = {"file_name": {"type": "string"},
"label": {"type": "int32"},
"data": {"type": "bytes"}}
# Declare the MindSpore Record file format
writer = FileWriter(file_name, shard_num=1, overwrite=True)
writer.add_schema(cv_schema, "it is a cv dataset")
writer.add_index(["file_name", "label"])
# Building a dataset
data = []
for i in range(100):
sample = {}
white_io = BytesIO()
Image.new('RGB', ((i+1)*10, (i+1)*10), (255, 255, 255)).save(white_io, 'JPEG')
image_bytes = white_io.getvalue()
sample['file_name'] = str(i+1) + ".jpg"
sample['label'] = i+1
sample['data'] = white_io.getvalue()
data.append(sample)
if i % 10 == 0:
writer.write_raw_data(data)
data = []
if data:
writer.write_raw_data(data)
writer.commit()
If there is no error reported, the dataset conversion was successful.
Read the MindSpore Record file format via the
MindDatasetinterface.
[2]:
from mindspore.dataset import MindDataset
from mindspore.dataset.vision import Decode
# Read the MindSpore Record file format
data_set = MindDataset(dataset_files=file_name)
decode_op = Decode()
data_set = data_set.map(operations=decode_op, input_columns=["data"], num_parallel_workers=2)
# Count the number of samples
print("Got {} samples".format(data_set.get_dataset_size()))
Got 100 samples
Converting NLP Class Dataset
This example first creates a text data containing 100 records and then converts it to MindSpore Record file format. Its sample contains eight fields, all of which are integer arrays, and then uses the MindDataset interface to read the MindSpore Record file.
For ease of presentation, the preprocessing process of converting text to lexicographic order is omitted here.
Generate 100 images and convert them to MindSpore Record format file.
[ ]:
import numpy as np
from mindspore.mindrecord import FileWriter
# The full path of the output MindSpore Record file
file_name = "test_text.mindrecord"
# Defines the fields that the sample data contains
nlp_schema = {"source_sos_ids": {"type": "int64", "shape": [-1]},
"source_sos_mask": {"type": "int64", "shape": [-1]},
"source_eos_ids": {"type": "int64", "shape": [-1]},
"source_eos_mask": {"type": "int64", "shape": [-1]},
"target_sos_ids": {"type": "int64", "shape": [-1]},
"target_sos_mask": {"type": "int64", "shape": [-1]},
"target_eos_ids": {"type": "int64", "shape": [-1]},
"target_eos_mask": {"type": "int64", "shape": [-1]}}
# Declare the MindSpore Record file format
writer = FileWriter(file_name, shard_num=1, overwrite=True)
writer.add_schema(nlp_schema, "Preprocessed nlp dataset.")
# Build a virtual dataset
data = []
for i in range(100):
sample = {"source_sos_ids": np.array([i, i + 1, i + 2, i + 3, i + 4], dtype=np.int64),
"source_sos_mask": np.array([i * 1, i * 2, i * 3, i * 4, i * 5, i * 6, i * 7], dtype=np.int64),
"source_eos_ids": np.array([i + 5, i + 6, i + 7, i + 8, i + 9, i + 10], dtype=np.int64),
"source_eos_mask": np.array([19, 20, 21, 22, 23, 24, 25, 26, 27], dtype=np.int64),
"target_sos_ids": np.array([28, 29, 30, 31, 32], dtype=np.int64),
"target_sos_mask": np.array([33, 34, 35, 36, 37, 38], dtype=np.int64),
"target_eos_ids": np.array([39, 40, 41, 42, 43, 44, 45, 46, 47], dtype=np.int64),
"target_eos_mask": np.array([48, 49, 50, 51], dtype=np.int64)}
data.append(sample)
if i % 10 == 0:
writer.write_raw_data(data)
data = []
if data:
writer.write_raw_data(data)
writer.commit()
Read the MindSpore Record format file through the MindDataset interface.
[4]:
from mindspore.dataset import MindDataset
# Read MindSpore Record file format
data_set = MindDataset(dataset_files=file_name, shuffle=False)
# Count the number of samples
print("Got {} samples".format(data_set.get_dataset_size()))
# Print the part of data
count = 0
for item in data_set.create_dict_iterator(output_numpy=True):
print("source_sos_ids:", item["source_sos_ids"])
count += 1
if count == 10:
break
Got 100 samples
source_sos_ids: [0 1 2 3 4]
source_sos_ids: [1 2 3 4 5]
source_sos_ids: [2 3 4 5 6]
source_sos_ids: [3 4 5 6 7]
source_sos_ids: [4 5 6 7 8]
source_sos_ids: [5 6 7 8 9]
source_sos_ids: [ 6 7 8 9 10]
source_sos_ids: [ 7 8 9 10 11]
source_sos_ids: [ 8 9 10 11 12]
source_sos_ids: [ 9 10 11 12 13]
Dumping Dataset to MindRecord
MindSpore provides a tool class for converting commonly used datasets, capable of converting commonly used datasets to the MindSpore Record file format.
For more detailed descriptions of dataset transformations, refer to API Documentation.
Dumping the CIFAR-10 Dataset
Users can convert CIFAR-10 raw data to MindSpore Record and read it using the MindDataset interface via the mindspore.dataset.Dataset.save method.
Download the CIFAR-10 Dataset and use
Cifar10Datasetto load.
[ ]:
from download import download
from mindspore.dataset import Cifar10Dataset
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/cifar-10-binary.tar.gz"
path = download(url, "./", kind="tar.gz", replace=True)
dataset = Cifar10Dataset("./cifar-10-batches-bin/") # load data
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/cifar-10-binary.tar.gz (162.2 MB)
file_sizes: 100%|████████████████████████████| 170M/170M [00:18<00:00, 9.34MB/s]
Extracting tar.gz file...
Successfully downloaded / unzipped to ./
Call the
Dataset.saveinterface to dump the CIFAR-10 dataset into the MindSpore Record file format.
[ ]:
dataset.save("cifar10.mindrecord")
Read the MindSpore Record format file through the
MindDatasetinterface.
[ ]:
import os
from mindspore.dataset import MindDataset
# Read MindSpore Record file format
data_set = MindDataset(dataset_files="cifar10.mindrecord")
# Count the number of samples
print("Got {} samples".format(data_set.get_dataset_size()))
if os.path.exists("cifar10.mindrecord") and os.path.exists("cifar10.mindrecord.db"):
os.remove("cifar10.mindrecord")
os.remove("cifar10.mindrecord.db")
Got 60000 samples