PreDiff: Precipitation Nowcasting Based on Latent Diffusion Models
![]()
![]()
![]()
Overview
Traditional weather forecasting techniques rely on complex physical models.These models are not only computationally expensive but also require profound professional knowledge as support. However, in the past decade, with the explosive growth of Earth’s spatiotemporal observation data, deep learning techniques have opened up new avenues for constructing data-driven prediction models. Although these models have demonstrated great potential in various Earth system prediction tasks, they still have deficiencies in managing uncertainties and integrating domain-specific prior knowledge, often leading to ambiguous or physically implausible prediction results.
To overcome these challenges, Gao Zhihan from the Hong Kong University of Science and Technology has implemented the PreDiff model, which is specifically designed to achieve probabilistic spatiotemporal prediction. This process integrates a conditional latent diffusion model with an explicit knowledge alignment mechanism, aiming to generate prediction results that not only conform to the physical constraints of the specific domain but also accurately capture spatiotemporal variations. Through this approach, we expect to significantly improve the accuracy and reliability of Earth system predictions. The model framework diagram is shown below (the image is from the paper PreDiff: Precipitation Nowcasting with Latent Diffusion Models):
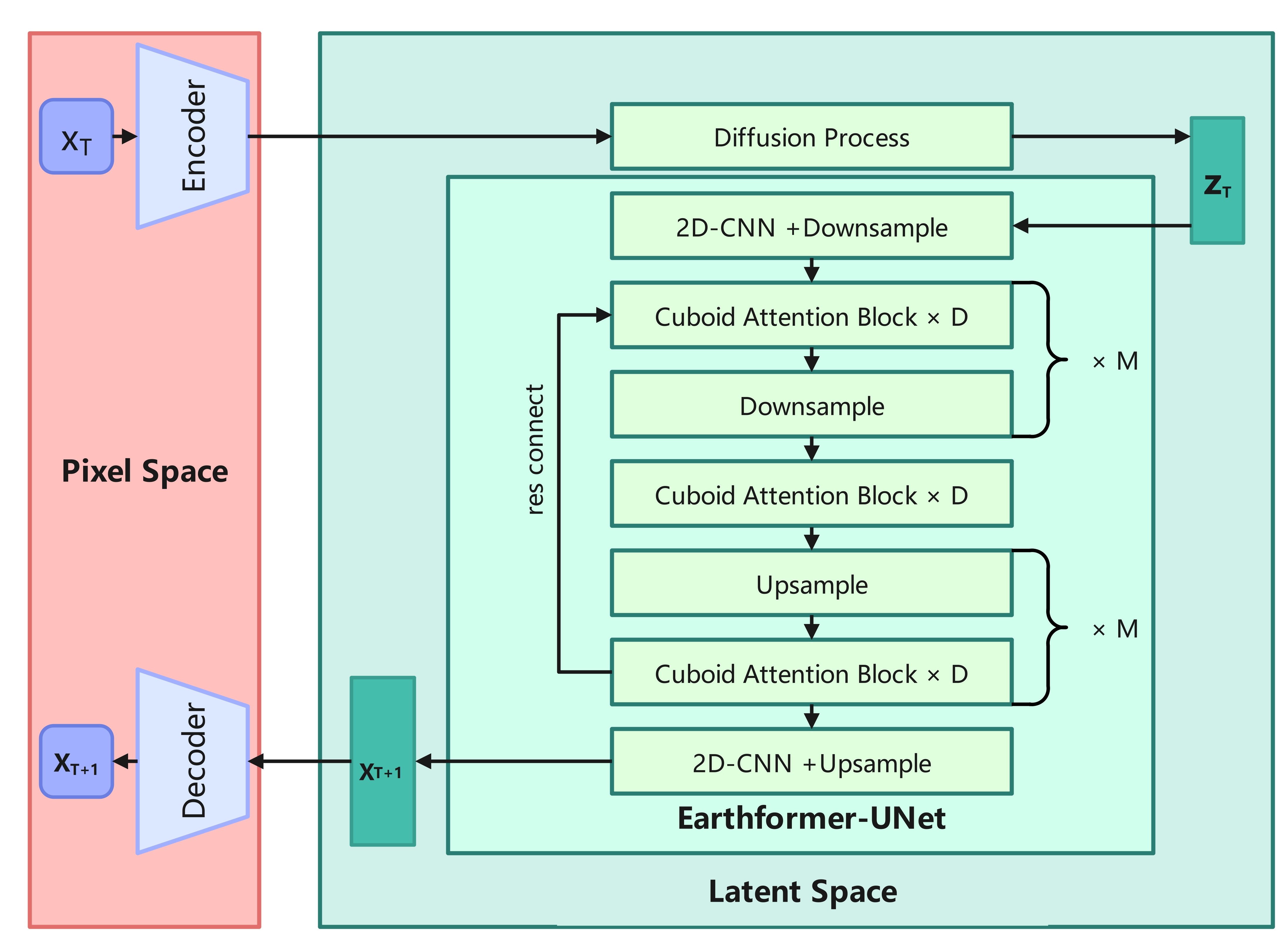
During the training process, the variational auto-encoder extracts key information from the data into the latent space. Then, a time step is randomly selected to generate the corresponding noise for that time step, and the data is then augmented with this noise. Subsequently, the noisy data is fed into the Earthformer-UNet for denoising. The Earthformer-UNet employs the UNet architecture and Cuboid Attention, and removes the Cross Attention structure that connects the Encoder and Decoder in the original Earthformer. Finally, the denoised data is obtained by restoring the results through the variational auto-decoder. The diffusion model learns the data distribution by reversing the pre-defined noise-adding process that corrupts the original data.
Technology Path
The specific process of MindSpore Earth in solving this problem is as follows:
Create a dataset.
Construct the model.
Define the loss function.
Train the model.
Evaluate and visualize the model.
The dataset can be downloaded from PreDiff/dataset and saved.
[1]:
import time
import os
import random
import json
from typing import Sequence, Union
import numpy as np
from einops import rearrange
import mindspore as ms
from mindspore import set_seed, context, ops, nn, mint
from mindspore.experimental import optim
from mindspore.train.serialization import save_checkpoint
The following src can be downloaded from PreDiff/src.
[2]:
from mindearth.utils import load_yaml_config
from src import (
prepare_output_directory,
configure_logging_system,
prepare_dataset,
init_model,
PreDiffModule,
DiffusionTrainer,
DiffusionInferrence
)
from src.sevir_dataset import SEVIRDataset
from src.visual import vis_sevir_seq
from src.utils import warmup_lambda
[3]:
set_seed(0)
np.random.seed(0)
random.seed(0)
The parameters of the model, data, optimizer, etc. can be configured in the configuration file.
[4]:
config = load_yaml_config("./configs/diffusion.yaml")
context.set_context(mode=ms.PYNATIVE_MODE)
ms.set_device(device_target="Ascend", device_id=0)
Model Construction
The model initialization mainly includes the initialization of the variational autoencoder and the earthformer.
[5]:
main_module = PreDiffModule(oc_file="./configs/diffusion.yaml")
main_module = init_model(module=main_module, config=config, mode="train")
output_dir = prepare_output_directory(config, "0")
logger = configure_logging_system(output_dir, config)
2025-04-07 10:32:11,466 - utils.py[line:820] - INFO: Process ID: 2231351
2025-04-07 10:32:11,467 - utils.py[line:821] - INFO: {'summary_dir': './summary/prediff/single_device0', 'eval_interval': 10, 'save_ckpt_epochs': 1, 'keep_ckpt_max': 100, 'ckpt_path': '', 'load_ckpt': False}
NoisyCuboidTransformerEncoder param_not_load: []
Cleared previous output directory: ./summary/prediff/single_device0
Creating a Dataset
Download the sevir-lr dataset to the ./dataset directory.
[6]:
dm, total_num_steps = prepare_dataset(config, PreDiffModule)
Loss Function
During the training of PreDiff, the mean squared error (mse) is used as the loss calculation. Gradient clipping is adopted, and the process is encapsulated in the DiffusionTrainer.
[7]:
class DiffusionTrainer(nn.Cell):
"""
Class managing the training pipeline for diffusion models. Handles dataset processing,
optimizer configuration, gradient clipping, checkpoint saving, and logging.
"""
def __init__(self, main_module, dm, logger, config):
"""
Initialize trainer with model, data module, logger, and configuration.
Args:
main_module: Main diffusion model to be trained
dm: Data module providing training dataset
logger: Logging utility for training progress
config: Configuration dictionary containing hyperparameters
"""
super().__init__()
self.main_module = main_module
self.traindataset = dm.sevir_train
self.logger = logger
self.datasetprocessing = SEVIRDataset(
data_types=["vil"],
layout="NHWT",
rescale_method=config.get("rescale_method", "01"),
)
self.example_save_dir = config["summary"].get("summary_dir", "./summary")
self.fs = config["eval"].get("fs", 20)
self.label_offset = config["eval"].get("label_offset", [-0.5, 0.5])
self.label_avg_int = config["eval"].get("label_avg_int", False)
self.current_epoch = 0
self.learn_logvar = (
config.get("model", {}).get("diffusion", {}).get("learn_logvar", False)
)
self.logvar = main_module.logvar
self.maeloss = nn.MAELoss()
self.optim_config = config["optim"]
self.clip_norm = config.get("clip_norm", 2.0)
self.ckpt_dir = os.path.join(self.example_save_dir, "ckpt")
self.keep_ckpt_max = config["summary"].get("keep_ckpt_max", 100)
self.ckpt_history = []
self.grad_clip_fn = ops.clip_by_global_norm
self.optimizer = nn.Adam(params=self.main_module.main_model.trainable_params(), learning_rate=0.00001)
os.makedirs(self.ckpt_dir, exist_ok=True)
def train(self, total_steps: int):
"""Execute complete training pipeline."""
self.main_module.main_model.set_train(True)
self.logger.info("Initializing training process...")
loss_processor = Trainonestepforward(self.main_module)
grad_func = ms.ops.value_and_grad(loss_processor, None, self.main_module.main_model.trainable_params())
for epoch in range(self.optim_config["max_epochs"]):
epoch_loss = 0.0
epoch_start = time.time()
iterator = self.traindataset.create_dict_iterator()
assert iterator, "dataset is empty"
batch_idx = 0
for batch_idx, batch in enumerate(iterator):
processed_data = self.datasetprocessing.process_data(batch["vil"])
loss_value, gradients = grad_func(processed_data)
clipped_grads = self.grad_clip_fn(gradients, self.clip_norm)
self.optimizer(clipped_grads)
epoch_loss += loss_value.asnumpy()
self.logger.info(
f"epoch: {epoch} step: {batch_idx}, loss: {loss_value}"
)
self._save_ckpt(epoch)
epoch_time = time.time() - epoch_start
self.logger.info(
f"Epoch {epoch} completed in {epoch_time:.2f}s | "
f"Avg Loss: {epoch_loss/(batch_idx+1):.4f}"
)
def _get_optimizer(self, total_steps: int):
"""Configure optimization components"""
trainable_params = list(self.main_module.main_model.trainable_params())
if self.learn_logvar:
self.logger.info("Including log variance parameters")
trainable_params.append(self.logvar)
optimizer = optim.AdamW(
trainable_params,
lr=self.optim_config["lr"],
betas=tuple(self.optim_config["betas"]),
)
warmup_steps = int(self.optim_config["warmup_percentage"] * total_steps)
scheduler = self._create_lr_scheduler(optimizer, total_steps, warmup_steps)
return optimizer, scheduler
def _create_lr_scheduler(self, optimizer, total_steps: int, warmup_steps: int):
"""Build learning rate scheduler"""
warmup_scheduler = optim.lr_scheduler.LambdaLR(
optimizer,
lr_lambda=warmup_lambda(
warmup_steps=warmup_steps,
min_lr_ratio=self.optim_config["warmup_min_lr_ratio"],
),
)
cosine_scheduler = optim.lr_scheduler.CosineAnnealingLR(
optimizer,
T_max=total_steps - warmup_steps,
eta_min=self.optim_config["min_lr_ratio"] * self.optim_config["lr"],
)
return optim.lr_scheduler.SequentialLR(
optimizer,
schedulers=[warmup_scheduler, cosine_scheduler],
milestones=[warmup_steps],
)
def _save_ckpt(self, epoch: int):
"""Save model ckpt with rotation policy"""
ckpt_file = f"diffusion_epoch{epoch}.ckpt"
ckpt_path = os.path.join(self.ckpt_dir, ckpt_file)
save_checkpoint(self.main_module.main_model, ckpt_path)
self.ckpt_history.append(ckpt_path)
if len(self.ckpt_history) > self.keep_ckpt_max:
removed_ckpt = self.ckpt_history.pop(0)
os.remove(removed_ckpt)
self.logger.info(f"Removed outdated ckpt: {removed_ckpt}")
class Trainonestepforward(nn.Cell):
"""A neural network cell that performs one training step forward pass for a diffusion model.
This class encapsulates the forward pass computation for training a diffusion model,
handling the input processing, latent space encoding, conditioning, and loss calculation.
Args:
model (nn.Cell): The main diffusion model containing the necessary submodules
for encoding, conditioning, and loss computation.
"""
def __init__(self, model):
super().__init__()
self.main_module = model
def construct(self, inputs):
"""Perform one forward training step and compute the loss."""
x, condition = self.main_module.get_input(inputs)
x = x.transpose(0, 1, 4, 2, 3)
n, t_, c_, h, w = x.shape
x = x.reshape(n * t_, c_, h, w)
z = self.main_module.encode_first_stage(x)
_, c_z, h_z, w_z = z.shape
z = z.reshape(n, -1, c_z, h_z, w_z)
z = z.transpose(0, 1, 3, 4, 2)
t = ops.randint(0, self.main_module.num_timesteps, (n,)).long()
zc = self.main_module.cond_stage_forward(condition)
loss = self.main_module.p_losses(z, zc, t, noise=None)
return loss
Model Training
In this tutorial, we use the DiffusionTrainer to train the model.
[8]:
trainer = DiffusionTrainer(
main_module=main_module, dm=dm, logger=logger, config=config
)
trainer.train(total_steps=total_num_steps)
2025-04-07 10:32:36,351 - 4106154625.py[line:46] - INFO: Initializing training process...
.........2025-04-07 10:34:09,378 - 4106154625.py[line:64] - INFO: epoch: 0 step: 0, loss: 1.0008465
.2025-04-07 10:34:16,871 - 4106154625.py[line:64] - INFO: epoch: 0 step: 1, loss: 1.0023363
2025-04-07 10:34:18,724 - 4106154625.py[line:64] - INFO: epoch: 0 step: 2, loss: 1.0009086
.2025-04-07 10:34:20,513 - 4106154625.py[line:64] - INFO: epoch: 0 step: 3, loss: 0.99787366
2025-04-07 10:34:22,280 - 4106154625.py[line:64] - INFO: epoch: 0 step: 4, loss: 0.9979043
2025-04-07 10:34:24,072 - 4106154625.py[line:64] - INFO: epoch: 0 step: 5, loss: 0.99897844
2025-04-07 10:34:25,864 - 4106154625.py[line:64] - INFO: epoch: 0 step: 6, loss: 1.0021904
2025-04-07 10:34:27,709 - 4106154625.py[line:64] - INFO: epoch: 0 step: 7, loss: 0.9984627
2025-04-07 10:34:29,578 - 4106154625.py[line:64] - INFO: epoch: 0 step: 8, loss: 0.9952746
.2025-04-07 10:34:31,432 - 4106154625.py[line:64] - INFO: epoch: 0 step: 9, loss: 1.0003254
2025-04-07 10:34:33,402 - 4106154625.py[line:64] - INFO: epoch: 0 step: 10, loss: 1.0020428
2025-04-07 10:34:35,218 - 4106154625.py[line:64] - INFO: epoch: 0 step: 11, loss: 0.99563503
2025-04-07 10:34:37,149 - 4106154625.py[line:64] - INFO: epoch: 0 step: 12, loss: 0.99336195
2025-04-07 10:34:38,949 - 4106154625.py[line:64] - INFO: epoch: 0 step: 13, loss: 1.0023757
......2025-04-07 13:39:55,859 - 4106154625.py[line:64] - INFO: epoch: 4 step: 1247, loss: 0.021378823
2025-04-07 13:39:57,754 - 4106154625.py[line:64] - INFO: epoch: 4 step: 1248, loss: 0.01565772
2025-04-07 13:39:59,606 - 4106154625.py[line:64] - INFO: epoch: 4 step: 1249, loss: 0.012067624
2025-04-07 13:40:01,396 - 4106154625.py[line:64] - INFO: epoch: 4 step: 1250, loss: 0.017700804
2025-04-07 13:40:03,181 - 4106154625.py[line:64] - INFO: epoch: 4 step: 1251, loss: 0.06254268
2025-04-07 13:40:04,945 - 4106154625.py[line:64] - INFO: epoch: 4 step: 1252, loss: 0.013293369
.2025-04-07 13:40:06,770 - 4106154625.py[line:64] - INFO: epoch: 4 step: 1253, loss: 0.026906993
2025-04-07 13:40:08,644 - 4106154625.py[line:64] - INFO: epoch: 4 step: 1254, loss: 0.18210539
2025-04-07 13:40:10,593 - 4106154625.py[line:64] - INFO: epoch: 4 step: 1255, loss: 0.024170894
2025-04-07 13:40:12,430 - 4106154625.py[line:69] - INFO: Epoch 4 completed in 2274.61s | Avg Loss: 0.0517
Model Evaluation and Visualization
After the training is completed, we use the 5th ckpt for inference. The following shows the error between the predicted values and the actual values and various indicators.
[14]:
def get_alignment_kwargs_avg_x(target_seq):
"""Generate alignment parameters for guided sampling"""
batch_size = target_seq.shape[0]
avg_intensity = mint.mean(target_seq.view(batch_size, -1), dim=1, keepdim=True)
return {"avg_x_gt": avg_intensity * 2.0}
class DiffusionInferrence(nn.Cell):
"""
Class managing model inference and evaluation processes. Handles loading checkpoints,
generating predictions, calculating evaluation metrics, and saving visualization results.
"""
def __init__(self, main_module, dm, logger, config):
"""
Initialize inference manager with model, data module, logger, and configuration.
Args:
main_module: Main diffusion model for inference
dm: Data module providing test dataset
logger: Logging utility for evaluation progress
config: Configuration dictionary containing evaluation parameters
"""
super().__init__()
self.num_samples = config["eval"].get("num_samples_per_context", 1)
self.eval_example_only = config["eval"].get("eval_example_only", True)
self.alignment_type = (
config.get("model", {}).get("align", {}).get("alignment_type", "avg_x")
)
self.use_alignment = self.alignment_type is not None
self.eval_aligned = config["eval"].get("eval_aligned", True)
self.eval_unaligned = config["eval"].get("eval_unaligned", True)
self.num_samples_per_context = config["eval"].get("num_samples_per_context", 1)
self.logging_prefix = config["logging"].get("logging_prefix", "PreDiff")
self.test_example_data_idx_list = [48]
self.main_module = main_module
self.testdataset = dm.sevir_test
self.logger = logger
self.datasetprocessing = SEVIRDataset(
data_types=["vil"],
layout="NHWT",
rescale_method=config.get("rescale_method", "01"),
)
self.example_save_dir = config["summary"].get("summary_dir", "./summary")
self.fs = config["eval"].get("fs", 20)
self.label_offset = config["eval"].get("label_offset", [-0.5, 0.5])
self.label_avg_int = config["eval"].get("label_avg_int", False)
self.current_epoch = 0
self.learn_logvar = (
config.get("model", {}).get("diffusion", {}).get("learn_logvar", False)
)
self.logvar = main_module.logvar
self.maeloss = nn.MAELoss()
self.test_metrics = {
"step": 0,
"mse": 0.0,
"mae": 0.0,
"ssim": 0.0,
"mse_kc": 0.0,
"mae_kc": 0.0,
}
def test(self):
"""Execute complete evaluation pipeline."""
self.logger.info("============== Start Test ==============")
self.start_time = time.time()
for batch_idx, item in enumerate(self.testdataset.create_dict_iterator()):
self.test_metrics = self._test_onestep(item, batch_idx, self.test_metrics)
self._finalize_test(self.test_metrics)
def _test_onestep(self, item, batch_idx, metrics):
"""Process one test batch and update evaluation metrics."""
data_idx = int(batch_idx * 2)
if not self._should_test_onestep(data_idx):
return metrics
data = item.get("vil")
data = self.datasetprocessing.process_data(data)
target_seq, cond, context_seq = self._get_model_inputs(data)
aligned_preds, unaligned_preds = self._generate_predictions(
cond, target_seq
)
metrics = self._update_metrics(
aligned_preds, unaligned_preds, target_seq, metrics
)
self._plt_pred(
data_idx,
context_seq,
target_seq,
aligned_preds,
unaligned_preds,
metrics["step"],
)
metrics["step"] += 1
return metrics
def _should_test_onestep(self, data_idx):
"""Determine if evaluation should be performed on current data index."""
return (not self.eval_example_only) or (
data_idx in self.test_example_data_idx_list
)
def _get_model_inputs(self, data):
"""Extract and prepare model inputs from raw data."""
target_seq, cond, context_seq = self.main_module.get_input(
data, return_verbose=True
)
return target_seq, cond, context_seq
def _generate_predictions(self, cond, target_seq):
"""Generate both aligned and unaligned predictions from the model."""
aligned_preds = []
unaligned_preds = []
for _ in range(self.num_samples_per_context):
if self.use_alignment and self.eval_aligned:
aligned_pred = self._sample_with_alignment(
cond, target_seq
)
aligned_preds.append(aligned_pred)
if self.eval_unaligned:
unaligned_pred = self._sample_without_alignment(cond)
unaligned_preds.append(unaligned_pred)
return aligned_preds, unaligned_preds
def _sample_with_alignment(self, cond, target_seq):
"""Generate predictions using alignment mechanism."""
alignment_kwargs = get_alignment_kwargs_avg_x(target_seq)
pred_seq = self.main_module.sample(
cond=cond,
batch_size=cond["y"].shape[0],
return_intermediates=False,
use_alignment=True,
alignment_kwargs=alignment_kwargs,
verbose=False,
)
if pred_seq.dtype != ms.float32:
pred_seq = pred_seq.float()
return pred_seq
def _sample_without_alignment(self, cond):
"""Generate predictions without alignment."""
pred_seq = self.main_module.sample(
cond=cond,
batch_size=cond["y"].shape[0],
return_intermediates=False,
verbose=False,
)
if pred_seq.dtype != ms.float32:
pred_seq = pred_seq.float()
return pred_seq
def _update_metrics(self, aligned_preds, unaligned_preds, target_seq, metrics):
"""Update evaluation metrics with new predictions."""
for pred in aligned_preds:
metrics["mse_kc"] += ops.mse_loss(pred, target_seq)
metrics["mae_kc"] += self.maeloss(pred, target_seq)
self.main_module.test_aligned_score.update(pred, target_seq)
for pred in unaligned_preds:
metrics["mse"] += ops.mse_loss(pred, target_seq)
metrics["mae"] += self.maeloss(pred, target_seq)
self.main_module.test_score.update(pred, target_seq)
pred_bchw = self._convert_to_bchw(pred)
target_bchw = self._convert_to_bchw(target_seq)
metrics["ssim"] += self.main_module.test_ssim(pred_bchw, target_bchw)[0]
return metrics
def _convert_to_bchw(self, tensor):
"""Convert tensor to batch-channel-height-width format for metrics."""
return rearrange(tensor.asnumpy(), "b t h w c -> (b t) c h w")
def _plt_pred(
self, data_idx, context_seq, target_seq, aligned_preds, unaligned_preds, step
):
"""Generate and save visualization of predictions."""
pred_sequences = [pred[0].asnumpy() for pred in aligned_preds + unaligned_preds]
pred_labels = [
f"{self.logging_prefix}_aligned_pred_{i}" for i in range(len(aligned_preds))
] + [f"{self.logging_prefix}_pred_{i}" for i in range(len(unaligned_preds))]
self.save_vis_step_end(
data_idx=data_idx,
context_seq=context_seq[0].asnumpy(),
target_seq=target_seq[0].asnumpy(),
pred_seq=pred_sequences,
pred_label=pred_labels,
mode="test",
suffix=f"_step_{step}",
)
def _finalize_test(self, metrics):
"""Complete test process and log final metrics."""
total_time = (time.time() - self.start_time) * 1000
self.logger.info(f"test cost: {total_time:.2f} ms")
self._compute_total_metrics(metrics)
self.logger.info("============== Test Completed ==============")
def _compute_total_metrics(self, metrics):
"""log_metrics"""
step_count = max(metrics["step"], 1)
if self.eval_unaligned:
self.logger.info(f"MSE: {metrics['mse'] / step_count}")
self.logger.info(f"MAE: {metrics['mae'] / step_count}")
self.logger.info(f"SSIM: {metrics['ssim'] / step_count}")
test_score = self.main_module.test_score.eval()
self.logger.info("SCORE:\n%s", json.dumps(test_score, indent=4))
if self.use_alignment:
self.logger.info(f"KC_MSE: {metrics['mse_kc'] / step_count}")
self.logger.info(f"KC_MAE: {metrics['mae_kc'] / step_count}")
aligned_score = self.main_module.test_aligned_score.eval()
self.logger.info("KC_SCORE:\n%s", json.dumps(aligned_score, indent=4))
def save_vis_step_end(
self,
data_idx: int,
context_seq: np.ndarray,
target_seq: np.ndarray,
pred_seq: Union[np.ndarray, Sequence[np.ndarray]],
pred_label: Union[str, Sequence[str]] = None,
mode: str = "train",
prefix: str = "",
suffix: str = "",
):
"""Save visualization of predictions with context and target."""
example_data_idx_list = self.test_example_data_idx_list
if isinstance(pred_seq, Sequence):
seq_list = [context_seq, target_seq] + list(pred_seq)
label_list = ["context", "target"] + pred_label
else:
seq_list = [context_seq, target_seq, pred_seq]
label_list = ["context", "target", pred_label]
if data_idx in example_data_idx_list:
png_save_name = f"{prefix}{mode}_data_{data_idx}{suffix}.png"
vis_sevir_seq(
save_path=os.path.join(self.example_save_dir, png_save_name),
seq=seq_list,
label=label_list,
interval_real_time=10,
plot_stride=1,
fs=self.fs,
label_offset=self.label_offset,
label_avg_int=self.label_avg_int,
)
[15]:
main_module.main_model.set_train(False)
params = ms.load_checkpoint("/PreDiff/summary/prediff/single_device0/ckpt/diffusion_epoch4.ckpt")
a, b = ms.load_param_into_net(main_module.main_model, params)
print(b)
tester = DiffusionInferrence(
main_module=main_module, dm=dm, logger=logger, config=config
)
tester.test()
2025-04-07 14:04:16,558 - 2610859736.py[line:66] - INFO: ============== Start Test ==============
[]
..2025-04-07 14:10:31,931 - 2610859736.py[line:201] - INFO: test cost: 375371.60 ms
2025-04-07 14:10:31,937 - 2610859736.py[line:215] - INFO: KC_MSE: 0.0036273836
2025-04-07 14:10:31,939 - 2610859736.py[line:216] - INFO: KC_MAE: 0.017427118
2025-04-07 14:10:31,955 - 2610859736.py[line:218] - INFO: KC_SCORE:
{
"16": {
"csi": 0.2715393900871277,
"pod": 0.5063194632530212,
"sucr": 0.369321346282959,
"bias": 3.9119162559509277
},
"74": {
"csi": 0.15696434676647186,
"pod": 0.17386901378631592,
"sucr": 0.6175059080123901,
"bias": 0.16501028835773468
}
}
2025-04-07 14:10:31,956 - 2610859736.py[line:203] - INFO: ============== Test Completed ==============
