GraphCast: Medium-range Global Weather Forecasting Based on GNN
![]()
![]()
![]()
Overview
GraphCast is a data-driven global weather forecast model developed by researchers from DeepMind and Google. It provides medium-term forecasts of key global weather indicators with a resolution of 0.25°. Equivalent to a spatial resolution of approximately 25 km x 25 km near the equator and a global grid of 721 x 1440 pixels in size. Compared with the previous MachineLearning-based weather forecast model, this model improves the accuarcy to 99.2% of the 252 targets.
This tutorial introduces the research background and technical path of GraphCast, and shows how to train and fast infer the model through MindSpore Earth. More information can be found in paper. A partial dataset with a resolution of 1.4° is used in this tutorial and the results are shown below.
GraphCast
In order to achieve high resolution prediction, GraphCast uses GNNs as backbone network in an “encode-process-decode” model. The GNN-based leanred network architecture is designed for complex physical dynamics of input, uses message-passing allowing arbitrary patterns of spatial interactions over any range. The model uses the multi-mesh representation allows long-range interactions within few steps.
The following figure shows the GraphCast network architecture.

Input weather state: The high-resolution latitude-longitude-pressure-level grid represented surfarce variables(yellow layers) and atmospheric variables(blue layers) in Figure (a).
Predict the next state: GraphCast model predicted next step weather state by the current time state and previous time state. The format is as follows:
Roll out a forecast: GraphCast iteratively generates a T-step forecast. The format is as follows:
Encoder-Processor-Decoder: The GraphCast model contains encoder layer, processor layer and decoder layer.
In the encoder layer, all input features were embedded into latent space using multi-layer perceptrons(MLP). The model used message passing step to transfer the original latitude-longitude grid to the multi-mesh.
In the processor layer, a 16-layer deep GNN to learn the long-range edges on the multi-mesh that contain all multi-mesh edges. For each GNN layer, the adjacent nodes were used to update mesh edges. Then, it updates mesh nodes by aggregating information from all edges connected that node. Then, added a residual connection to updated edges and nodes.
In the decoder layer, it mapped the multi-mesh information back to the original latitude-longitude grid, which updated grid to mesh edges by aggregating information. Then, added a residual connection to updated edges and nodes.
Simultaneous multi-mesh message-passing: The key of GraphCast is the muti-mesh representation. The multi-mesh is a set of R-refined icosahedral mesh
Technology Path
MindSpore Earth solves the problem as follows:
Data Construction.
Model Construction.
Loss function.
Model Training.
Model Evaluation and Visualization.
Download the training and test dataset: graphcast/dataset.
[1]:
import os
import random
import matplotlib.pyplot as plt
import numpy as np
from mindspore import set_seed, load_checkpoint, load_param_into_net, context, Model
from mindspore.amp import DynamicLossScaleManager
The following src can be downloaded in graphcast/src.
[2]:
from mindearth.utils import load_yaml_config, create_logger, plt_global_field_data, make_dir
from mindearth.module import Trainer
from mindearth.data import Dataset, Era5Data
from mindearth.cell import GraphCastNet
from src import get_coe, GridMeshInfo
from src import EvaluateCallBack, LossNet, CustomWithLossCell, InferenceModule
[3]:
set_seed(0)
np.random.seed(0)
random.seed(0)
You can get parameters of model, data and optimizer from config.
[4]:
# set context for training: using graph mode for high performance training with Ascend acceleration
config = load_yaml_config("GraphCast_1.4.yaml")
context.set_context(mode=context.GRAPH_MODE, device_target="Ascend", device_id=0)
Data Construction
Download the statistic, training and validation dataset from dataset to ./dataset.
Modify the parameter of root_dir in the GraphCast_1.4.yaml, which set the directory for dataset.
The ./dataset is hosted with the following directory structure:
.
├── statistic
│ ├── mean.npy
│ ├── mean_s.npy
│ ├── std.npy
│ └── std_s.npy
├── train
│ └── 2015
├── train_static
│ └── 2015
├── train_surface
│ └── 2015
├── train_surface_static
│ └── 2015
├── valid
│ └── 2016
├── valid_static
│ └── 2016
├── valid_surface
│ └── 2016
├── valid_surface_static
│ └── 2016
Model Construction
The initialization of the model includes:
Load the mesh and grid information.
Load the per-variable-level inverse variance of time differences.
[5]:
config['data']['data_sink'] = True # set the data sink feature
config['data']['h_size'], config['data']['w_size'] = 128, 256 # set number of grid points in latitude and longitude directions
config['optimizer']['epochs'] = 100 # set the training epochs
config['optimizer']['initial_lr'] = 0.00025 # set the initial learning rate
config['summary']["eval_interval"] = 10 # set the frequency of validation
config['summary']['plt_key_info'] = False # whether to plot key information
config['summary']["summary_dir"] = './summary' # set the directory of model's checkpoint
make_dir(os.path.join(config['summary']["summary_dir"], "image"))
logger = create_logger(os.path.join(os.path.abspath(config['summary']["summary_dir"]), "results.log"))
[6]:
data_params = config.get("data")
model_params = config.get("model")
grid_mesh_info = GridMeshInfo(data_params)
model = GraphCastNet(vg_in_channels=data_params.get('feature_dims') * data_params.get('t_in'),
vg_out_channels=data_params.get('feature_dims'),
vm_in_channels=model_params.get('vm_in_channels'),
em_in_channels=model_params.get('em_in_channels'),
eg2m_in_channels=model_params.get('eg2m_in_channels'),
em2g_in_channels=model_params.get('em2g_in_channels'),
latent_dims=model_params.get('latent_dims'),
processing_steps=model_params.get('processing_steps'),
g2m_src_idx=grid_mesh_info.g2m_src_idx,
g2m_dst_idx=grid_mesh_info.g2m_dst_idx,
m2m_src_idx=grid_mesh_info.m2m_src_idx,
m2m_dst_idx=grid_mesh_info.m2m_dst_idx,
m2g_src_idx=grid_mesh_info.m2g_src_idx,
m2g_dst_idx=grid_mesh_info.m2g_dst_idx,
mesh_node_feats=grid_mesh_info.mesh_node_feats,
mesh_edge_feats=grid_mesh_info.mesh_edge_feats,
g2m_edge_feats=grid_mesh_info.g2m_edge_feats,
m2g_edge_feats=grid_mesh_info.m2g_edge_feats,
per_variable_level_mean=grid_mesh_info.sj_mean,
per_variable_level_std=grid_mesh_info.sj_std,
recompute=model_params.get('recompute', False))
Loss Function
GraphCast uses custom mean squared error for model training. The function was:

[7]:
sj_std, wj, ai = get_coe(config)
loss_fn = LossNet(ai, wj, sj_std, config.get('data').get('feature_dims'))
loss_cell = CustomWithLossCell(backbone=model, loss_fn=loss_fn, data_params=config.get('data'))
Model Training
In this tutorial, we inherite the Trainer and override the get_solver member function to build custom loss function, and override get_callback member function to perform inference on the test dataset during the training process.
MindSpore Earth provides training and inference interface for model training with MindSpore version >= 1.8.1.
[8]:
class GraphCastTrainer(Trainer):
def __init__(self, config, model, loss_fn, logger):
super().__init__(config, model, loss_fn, logger)
self.train_dataset, self.valid_dataset = self.get_dataset()
self.pred_cb = self.get_callback()
self.solver = self.get_solver()
def get_solver(self):
loss_scale = DynamicLossScaleManager()
solver = Model(network=self.loss_fn,
optimizer=self.optimizer,
loss_scale_manager=loss_scale,
amp_level=self.train_params.get('amp_level'),
)
return solver
def get_callback(self):
pred_cb = EvaluateCallBack(self.model, self.valid_dataset, self.config, self.logger)
return pred_cb
[9]:
trainer = GraphCastTrainer(config, model, loss_cell, logger)
trainer.train()
2023-08-18 08:31:11,242 - pretrain.py[line:211] - INFO: steps_per_epoch: 403
epoch: 1 step: 403, loss is 0.003921998
Train epoch time: 77295.547 ms, per step time: 191.800 ms
epoch: 2 step: 403, loss is 0.003456553
Train epoch time: 48287.290 ms, per step time: 119.820 ms
epoch: 3 step: 403, loss is 0.0028922241
Train epoch time: 48298.168 ms, per step time: 119.847 ms
epoch: 4 step: 403, loss is 0.0028646633
Train epoch time: 48293.240 ms, per step time: 119.834 ms
epoch: 5 step: 403, loss is 0.00251652
Train epoch time: 48303.110 ms, per step time: 119.859 ms
epoch: 6 step: 403, loss is 0.0024913677
Train epoch time: 48301.862 ms, per step time: 119.856 ms
epoch: 7 step: 403, loss is 0.0023838188
Train epoch time: 48326.265 ms, per step time: 119.916 ms
epoch: 8 step: 403, loss is 0.0021626246
Train epoch time: 48325.142 ms, per step time: 119.914 ms
epoch: 9 step: 403, loss is 0.002123243
Train epoch time: 48321.305 ms, per step time: 119.904 ms
epoch: 10 step: 403, loss is 0.002461584
Train epoch time: 49511.084 ms, per step time: 122.856 ms
2023-08-18 08:39:45,287 - forecast.py[line:204] - INFO: ================================Start Evaluation================================
2023-08-18 08:40:41,617 - forecast.py[line:222] - INFO: test dataset size: 8
2023-08-18 08:40:41,621 - forecast.py[line:173] - INFO: t = 6 hour:
2023-08-18 08:40:41,622 - forecast.py[line:183] - INFO: RMSE of Z500: 99.63094225503905, T2m: 1.7807282244821678, T850: 1.1389199313716583, U10: 1.3300655484052706
2023-08-18 08:40:41,623 - forecast.py[line:184] - INFO: ACC of Z500: 0.9995030164718628, T2m: 0.9949086904525757, T850: 0.9965617656707764, U10: 0.9709641933441162
2023-08-18 08:40:41,624 - forecast.py[line:173] - INFO: t = 72 hour:
2023-08-18 08:40:41,625 - forecast.py[line:183] - INFO: RMSE of Z500: 846.2669541832905, T2m: 5.095069601461138, T850: 4.291456435667611, U10: 5.033789250954006
2023-08-18 08:40:41,627 - forecast.py[line:184] - INFO: ACC of Z500: 0.9656049013137817, T2m: 0.9600029587745667, T850: 0.9581822752952576, U10: 0.5923701524734497
2023-08-18 08:40:41,628 - forecast.py[line:173] - INFO: t = 120 hour:
2023-08-18 08:40:41,629 - forecast.py[line:183] - INFO: RMSE of Z500: 1289.3497973601945, T2m: 7.078691998772932, T850: 5.762323874978418, U10: 6.205910397891656
2023-08-18 08:40:41,629 - forecast.py[line:184] - INFO: ACC of Z500: 0.9226452112197876, T2m: 0.9238687753677368, T850: 0.9285233020782471, U10: 0.366882860660553
2023-08-18 08:40:41,630 - forecast.py[line:232] - INFO: ================================End Evaluation================================
......epoch: 91 step: 403, loss is 0.00090005953
Train epoch time: 48299.581 ms, per step time: 119.850 ms
epoch: 92 step: 403, loss is 0.0009103894
Train epoch time: 48302.468 ms, per step time: 119.857 ms
epoch: 93 step: 403, loss is 0.00090527127
Train epoch time: 48296.220 ms, per step time: 119.842 ms
epoch: 94 step: 403, loss is 0.0009113429
Train epoch time: 48314.221 ms, per step time: 119.886 ms
epoch: 95 step: 403, loss is 0.0008906296
Train epoch time: 48332.578 ms, per step time: 119.932 ms
epoch: 96 step: 403, loss is 0.0009023069
Train epoch time: 48344.677 ms, per step time: 119.962 ms
epoch: 97 step: 403, loss is 0.00088527385
Train epoch time: 48319.437 ms, per step time: 119.899 ms
epoch: 98 step: 403, loss is 0.00087669905
Train epoch time: 48319.398 ms, per step time: 119.899 ms
epoch: 99 step: 403, loss is 0.00088527397
Train epoch time: 48305.233 ms, per step time: 119.864 ms
epoch: 100 step: 403, loss is 0.00093020557
Train epoch time: 49486.354 ms, per step time: 122.795 ms
2023-08-18 09:57:55,343 - forecast.py[line:204] - INFO: ================================Start Evaluation================================
2023-08-18 09:58:29,557 - forecast.py[line:222] - INFO: test dataset size: 8
2023-08-18 09:58:29,562 - forecast.py[line:173] - INFO: t = 6 hour:
2023-08-18 09:58:29,563 - forecast.py[line:183] - INFO: RMSE of Z500: 71.52867536392974, T2m: 1.1144296184615285, T850: 0.950450431058116, U10: 1.2159413055648252
2023-08-18 09:58:29,564 - forecast.py[line:184] - INFO: ACC of Z500: 0.9997411966323853, T2m: 0.9980063438415527, T850: 0.9975705146789551, U10: 0.9757701754570007
2023-08-18 09:58:29,566 - forecast.py[line:173] - INFO: t = 72 hour:
2023-08-18 09:58:29,567 - forecast.py[line:183] - INFO: RMSE of Z500: 564.955831718179, T2m: 3.2896556874900664, T850: 2.986913832820727, U10: 3.7879051445350314
2023-08-18 09:58:29,568 - forecast.py[line:184] - INFO: ACC of Z500: 0.9842368364334106, T2m: 0.9827487468719482, T850: 0.9765684008598328, U10: 0.7727301120758057
2023-08-18 09:58:29,569 - forecast.py[line:173] - INFO: t = 120 hour:
2023-08-18 09:58:29,570 - forecast.py[line:183] - INFO: RMSE of Z500: 849.0613208500506, T2m: 4.170533718752165, T850: 3.9617528334139918, U10: 4.781800252738846
2023-08-18 09:58:29,571 - forecast.py[line:184] - INFO: ACC of Z500: 0.9645607471466064, T2m: 0.9728373289108276, T850: 0.9592517018318176, U10: 0.6396898031234741
2023-08-18 09:58:29,572 - forecast.py[line:232] - INFO: ================================End Evaluation================================
Model Evaluation and Visualization
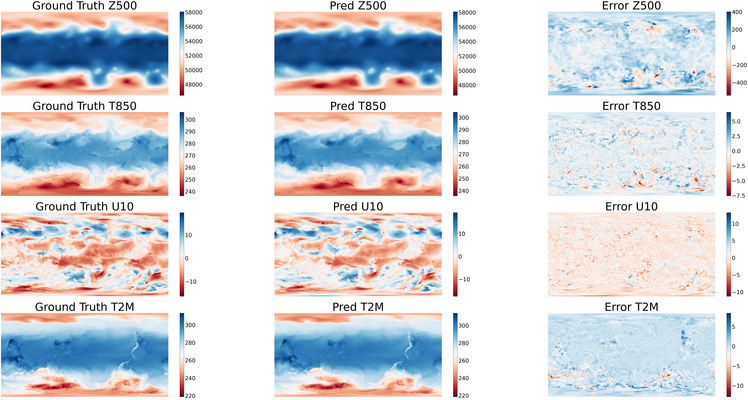
After training, we use the 100th checkpoint for inference. The visualization of predictions, ground truth and their error is shown below.
[12]:
params = load_checkpoint('./summary/ckpt/step_1/GraphCast-100_403.ckpt')
load_param_into_net(model, params)
inference_module = InferenceModule(model, config, logger)
[13]:
data_params = config.get("data")
test_dataset_generator = Era5Data(data_params=data_params, run_mode='test')
test_dataset = Dataset(test_dataset_generator, distribute=False,
num_workers=data_params.get('num_workers'), shuffle=False)
test_dataset = test_dataset.create_dataset(data_params.get('batch_size'))
data = next(test_dataset.create_dict_iterator())
inputs = data['inputs']
labels = data['labels']
[14]:
labels = labels[..., 0, :, :]
labels = labels.transpose(0, 2, 1)
labels = labels.reshape(labels.shape[0], labels.shape[1], data_params.get("h_size"), data_params.get("w_size")).asnumpy()
pred = inference_module.forecast(inputs)
pred = pred[0].transpose(1, 0)
pred = pred.reshape(pred.shape[0], data_params.get("h_size"), data_params.get("w_size")).asnumpy()
pred = np.expand_dims(pred, axis=0)
[15]:
def plt_key_info_comparison(pred, label, root_dir):
""" Visualize the comparison of forecast results """
std = np.load(os.path.join(root_dir, 'statistic/std.npy'))
mean = np.load(os.path.join(root_dir, 'statistic/mean.npy'))
std_s = np.load(os.path.join(root_dir, 'statistic/std_s.npy'))
mean_s = np.load(os.path.join(root_dir, 'statistic/mean_s.npy'))
plt.figure(num='e_imshow', figsize=(100, 50))
plt.subplot(4, 3, 1)
plt_global_field_data(label, 'Z500', std, mean, 'Ground Truth') # Z500
plt.subplot(4, 3, 2)
plt_global_field_data(pred, 'Z500', std, mean, 'Pred') # Z500
plt.subplot(4, 3, 3)
plt_global_field_data(label - pred, 'Z500', std, mean, 'Error', is_error=True) # Z500
plt.subplot(4, 3, 4)
plt_global_field_data(label, 'T850', std, mean, 'Ground Truth') # T850
plt.subplot(4, 3, 5)
plt_global_field_data(pred, 'T850', std, mean, 'Pred') # T850
plt.subplot(4, 3, 6)
plt_global_field_data(label - pred, 'T850', std, mean, 'Error', is_error=True) # T850
plt.subplot(4, 3, 7)
plt_global_field_data(label, 'U10', std_s, mean_s, 'Ground Truth', is_surface=True) # U10
plt.subplot(4, 3, 8)
plt_global_field_data(pred, 'U10', std_s, mean_s, 'Pred', is_surface=True) # U10
plt.subplot(4, 3, 9)
plt_global_field_data(label - pred, 'U10', std_s, mean_s, 'Error', is_surface=True, is_error=True) # U10
plt.subplot(4, 3, 10)
plt_global_field_data(label, 'T2M', std_s, mean_s, 'Ground Truth', is_surface=True) # T2M
plt.subplot(4, 3, 11)
plt_global_field_data(pred, 'T2M', std_s, mean_s, 'Pred', is_surface=True) # T2M
plt.subplot(4, 3, 12)
plt_global_field_data(label - pred, 'T2M', std_s, mean_s, 'Error', is_surface=True, is_error=True) # T2M
plt.savefig(f'key_info_comparison.png', bbox_inches='tight')
plt.show()
[16]:
plt_key_info_comparison(pred, labels, data_params.get('root_dir'))