mindspore.dataset
该模块提供了加载和处理各种通用数据集的API,如MNIST、CIFAR-10、CIFAR-100、VOC、COCO、ImageNet、CelebA、CLUE等, 也支持加载业界标准格式的数据集,包括MindRecord、TFRecord、Manifest等。此外,用户还可以使用此模块定义和加载自己的数据集。
该模块还提供了在加载时进行数据采样的API,如SequentialSample、RandomSampler、DistributedSampler等。
大多数数据集可以通过指定参数 cache 启用缓存服务,以提升整体数据处理效率。 请注意Windows平台上还不支持缓存服务,因此在Windows上加载和处理数据时,请勿使用。更多介绍和限制, 请参考 Single-Node Tensor Cache 。
在API示例中,常用的模块导入方法如下:
import mindspore.dataset as ds
import mindspore.dataset.transforms as transforms
import mindspore.dataset.vision as vision
常用数据集术语说明如下:
Dataset,所有数据集的基类,提供了数据处理方法来帮助预处理数据。
SourceDataset,一个抽象类,表示数据集管道的来源,从文件和数据库等数据源生成数据。
MappableDataset,一个抽象类,表示支持随机访问的源数据集。
Iterator,用于枚举元素的数据集迭代器的基类。
数据处理Pipeline介绍
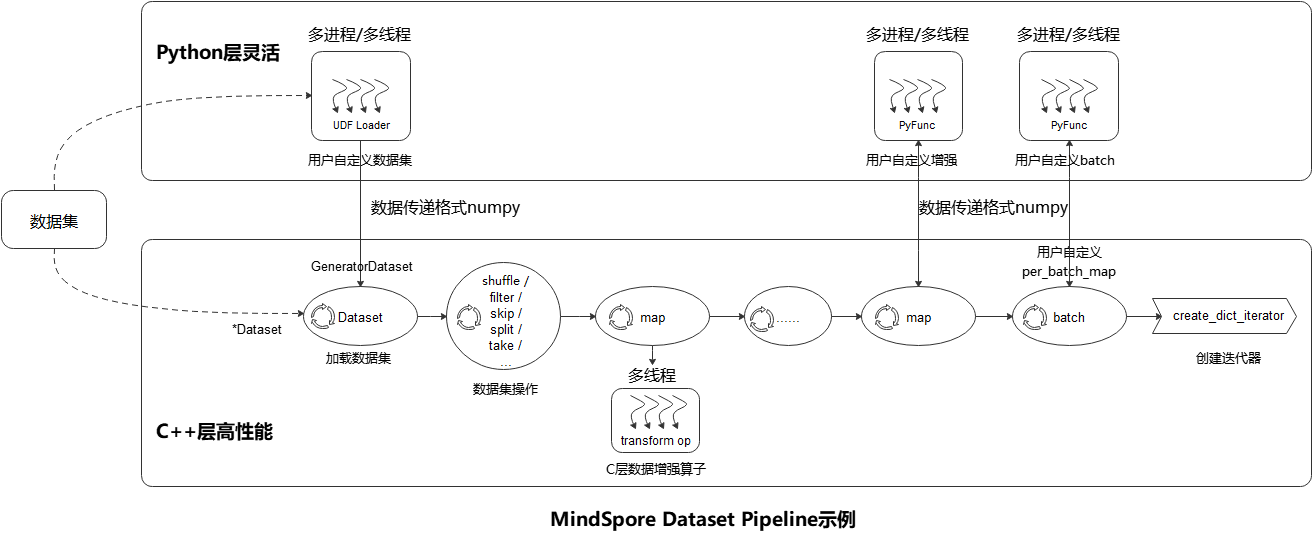
如上图所示,MindSpore Dataset模块使得用户很简便地定义数据预处理Pipeline,并以最高效(多进程/多线程)的方式处理 数据集中样本,具体的步骤参考如下:
加载数据集(Dataset):用户可以方便地使用 *Dataset 类来加载已支持的数据集,或者通过 UDF Loader + GeneratorDataset 实现Python层自定义数据集的加载,同时加载类方法可以使用多种Sampler、数据分片、数据shuffle等功能;
数据集操作(filter/ skip):用户通过数据集对象方法 .shuffle / .filter / .skip / .split / .take / … 来实现数据集的进一步混洗、过滤、跳过、最多获取条数等操作;
数据集样本增强操作(map):用户可以将数据增强操作 (vision类 , nlp类 , audio类 ) 添加到map操作中执行,数据预处理过程中可以定义多个map操作,用于执行不同增强操作,数据增强操作也可以是 用户自定义增强的 PyFunc ;
批(batch):用户在样本完成增强后,使用 .batch 操作将多个样本组织成batch,也可以通过batch的参数 per_batch_map 来自定义batch逻辑;
迭代器(create_dict_iterator):最后用户通过数据集对象方法 create_dict_iterator 来创建迭代器, 可以将预处理完成的数据循环输出。
数据处理Pipeline示例如下,完整示例请参考 datasets_example.py :
import numpy as np
import mindspore as ms
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
import mindspore.dataset.transforms as transforms
# 构造图像和标签
data1 = np.array(np.random.sample(size=(300, 300, 3)) * 255, dtype=np.uint8)
data2 = np.array(np.random.sample(size=(300, 300, 3)) * 255, dtype=np.uint8)
data3 = np.array(np.random.sample(size=(300, 300, 3)) * 255, dtype=np.uint8)
data4 = np.array(np.random.sample(size=(300, 300, 3)) * 255, dtype=np.uint8)
label = [1, 2, 3, 4]
# 加载数据集
dataset = ds.NumpySlicesDataset(([data1, data2, data3, data4], label), ["data", "label"])
# 对data数据增强
dataset = dataset.map(operations=vision.RandomCrop(size=(250, 250)), input_columns="data")
dataset = dataset.map(operations=vision.Resize(size=(224, 224)), input_columns="data")
dataset = dataset.map(operations=vision.Normalize(mean=[0.485 * 255, 0.456 * 255, 0.406 * 255],
std=[0.229 * 255, 0.224 * 255, 0.225 * 255]),
input_columns="data")
dataset = dataset.map(operations=vision.HWC2CHW(), input_columns="data")
# 对label变换类型
dataset = dataset.map(operations=transforms.TypeCast(ms.int32), input_columns="label")
# batch操作
dataset = dataset.batch(batch_size=2)
# 创建迭代器
epochs = 2
ds_iter = dataset.create_dict_iterator(output_numpy=True, num_epochs=epochs)
for _ in range(epochs):
for item in ds_iter:
print("item: {}".format(item), flush=True)
视觉
Caltech 101数据集。 |
|
Caltech 256数据集。 |
|
CelebA(CelebFaces Attributes)数据集。 |
|
CIFAR-10数据集。 |
|
CIFAR-100数据集。 |
|
Cityscapes数据集。 |
|
COCO(Common Objects in Context)数据集。 |
|
DIV2K(DIVerse 2K resolution image)数据集。 |
|
EMNIST(Extended MNIST)数据集。 |
|
生成虚假图像构建数据集。 |
|
Fashion-MNIST数据集。 |
|
Flickr8k和Flickr30k数据集。 |
|
Oxfird 102 Flower数据集。 |
|
Food101数据集。 |
|
从树状结构的文件目录中读取图片构建源数据集。 |
|
KITTI数据集。 |
|
KMNIST(Kuzushiji-MNIST)数据集。 |
|
LFW(Labeled Faces in the Wild)数据集。 |
|
LSUN(Large-scale Scene UNderstarding)数据集。 |
|
读取和解析Manifest数据文件构建数据集。 |
|
MNIST数据集。 |
|
Omniglot数据集。 |
|
PhotoTour数据集。 |
|
Places365数据集。 |
|
QMNIST数据集。 |
|
RenderedSST2(Rendered Stanford Sentiment Treebank v2)数据集。 |
|
SB(Semantic Boundaries)数据集。 |
|
SBU(SBU Captioned Photo)数据集。 |
|
Semeion数据集。 |
|
STL-10数据集。 |
|
SUN397(Scene UNderstanding)数据集。 |
|
SVHN(Street View House Numbers)数据集。 |
|
USPS(U.S. Postal Service)数据集。 |
|
VOC(Visual Object Classes)数据集。 |
|
WIDERFace数据集。 |
文本
AG News数据集。 |
|
Amazon Review Full和Amazon Review Polarity数据集。 |
|
CLUE(Chinese Language Understanding Evaluation)数据集。 |
|
CoNLL-2000(Conference on Computational Natural Language Learning)分块数据集。 |
|
DBpedia数据集。 |
|
EnWik9数据集。 |
|
IMDb(Internet Movie Database)数据集。 |
|
IWSLT2016(International Workshop on Spoken Language Translation)数据集。 |
|
IWSLT2017(International Workshop on Spoken Language Translation)数据集。 |
|
Multi30k数据集。 |
|
PennTreebank数据集。 |
|
Sogou New数据集。 |
|
SQuAD 1.1和SQuAD 2.0数据集。 |
|
SST2(Stanford Sentiment Treebank v2)数据集。 |
|
读取和解析文本文件构建数据集。 |
|
UDPOS(Universal Dependencies dataset for Part of Speech)数据集。 |
|
WikiText2和WikiText103数据集。 |
|
YahooAnswers数据集。 |
|
Yelp Review Full和Yelp Review Polarity数据集。 |
音频
CMU Arctic数据集。 |
|
GTZAN数据集。 |
|
LibriTTS数据集。 |
|
LJSpeech数据集。 |
|
Speech Commands数据集。 |
|
Tedlium数据集。 |
|
YesNo数据集。 |
标准格式
CSV(Comma-Separated Values)文件数据集。 |
|
读取和解析MindRecord数据文件构建数据集。 |
|
读取和解析存放在华为云OBS、Minio以及AWS S3等云存储上的MindRecord格式数据集。 |
|
读取和解析TFData格式的数据文件构建数据集。 |
用户自定义
自定义Python数据源,通过迭代该数据源构造数据集。 |
|
由Python数据构建数据集。 |
|
由用户提供的填充数据构建数据集。 |
|
生成随机数据的源数据集。 |
图
加载argoverse数据集并进行图(Graph)初始化。 |
|
主要用于存储图的结构信息和图特征属性,并提供图采样等能力。 |
|
从共享文件或数据库中读取用于GNN训练的图数据集。 |
|
用于将图数据加载到内存中的Dataset基类。 |
采样器
分布式采样器,将数据集进行分片用于分布式训练。 |
|
为数据集中每P个类别各采样K个样本。 |
|
随机采样器。 |
|
按数据集的读取顺序采样数据集样本,相当于不使用采样器。 |
|
给定样本的索引序列,从序列中随机获取索引对数据集进行采样。 |
|
给定样本的索引序列,对数据集采样指定索引的样本。 |
|
给定样本的权重列表,根据权重决定样本的采样概率,随机采样[0,len(weights) - 1]中的样本。 |
配置
config模块能够设置或获取数据处理的全局配置参数。
在昇腾设备中使用sink_mode=True进行训练时,设置默认的发送批次。 |
|
根据文件内容加载项目配置文件。 |
|
设置随机种子,产生固定的随机数来达到确定的结果。 |
|
获取随机数的种子。 |
|
设置管道中线程的队列容量。 |
|
获取数据处理管道的输出缓存队列长度。 |
|
为并行工作线程数量设置新的全局配置默认值。 |
|
获取并行工作线程数量的全局配置。 |
|
设置NUMA的默认状态为启动状态。 |
|
获取NUMA的启动/禁用状态。 |
|
设置监测采样的默认间隔时间(毫秒)。 |
|
获取性能监控采样时间间隔的全局配置。 |
|
为 |
|
获取 |
|
自动为每个数据集操作设置并行线程数量(默认情况下,此功能关闭)。 |
|
获取当前是否开启自动线程调整。 |
|
设置共享内存标志的是否启用。 |
|
获取当前是否开启共享内存。 |
|
设置是否开启自动数据加速。 |
|
获取当前是否开启自动数据加速。 |
|
设置自动数据加速的配置调整step间隔。 |
|
获取当前自动数据加速的配置调整step间隔。 |
|
设置是否开启数据异构加速。 |
|
获取当前是否开启数据异构加速。 |
|
设置watchdog Python线程是否启用。 |
|
获取当前是否开启watchdog Python线程。 |
|
在数据集管道故障恢复时,是否开启快速恢复模式(快速恢复模式下,无法保证随机性的数据增强操作得到与故障之前相同的结果)。 |
|
获取当前数据管道是否开启快速恢复模式。 |
|
|
设置在多进程/多线程下,主进程/主线程获取数据超时时,告警日志打印的默认时间间隔(秒)。 |
|
获取在多进程/多线程下,主进程/主线程获取数据超时时,告警日志打印的时间间隔的全局配置。 |
设置在数据管道中处理错误样本的策略。 |
|
获取当前数据管道中处理错误样本的策略配置。 |
|
指定数据管道中处理错误样本的策略。 |
其他
此类提供了两种方法获取数据集的批处理数量(batch size)和迭代数(epoch)属性,这些属性可以用于 batch 操作中的输入参数 batch_size 和 per_batch_map。 |
|
创建数据缓存客户端实例。 |
|
数据处理回调类的抽象基类,用户可以基于此类实现自己的回调操作。 |
|
指定图数据采样策略的枚举类。 |
|
用于解析和存储数据列属性的类。 |
|
指定混洗模式的枚举类。 |
|
阻塞式数据处理回调类的抽象基类,用于与训练回调类 mindspore.train.Callback 的同步。 |
|
通过API get_all_neighbors 获取所有相邻节点时,指定节点的存储格式。 |
|
比较两个数据处理管道是否相同。 |
|
数据处理管道反序列化,支持输入Python字典或使用 mindspore.dataset.serialize() 接口生成的JSON文件。 |
|
将数据处理管道序列化成JSON文件。 |
|
将数据处理管道图写入logger.info文件。 |
|
等待所有的卡需要的数据集文件下载完成。 |
|
使用给定的边界框和类别置信度绘制图像。 |