Recomputation
![]()
Overview
The automatic differential of MindSpore is in reverse-mode, which derives the backward pass according to the forward pass. Before some backward operators are computed, the results of some forward operators should be ready. It leads to the problem that the memory occupied by these results of the forward operators, can not be reused until the computation of the backward operators are completed. This problem can drive up the peak of memory, which is particularly significant in the large model.
In order to solve this problem, MindSpore provides the recomputation function. This tutorial takes the model ResNet-50 for example to explain how to configure recomputation to train your model in MindSpore.
Basic Principle
In order to reduce memory peaks, the recompute technique can not save the compute results of the forward activation layer, so that the memory can be reused, and then when calculating the reverse part, recompute the results of the forward activation layer. MindSpore provides the ability to recompute.
The recompute function is implemented as a forward operator that is recomputed according to the user's specified needs, copies the same operator, outputs it to the reverse operator, and deletes the continuous edge relationship between the original forward operator and the reverse operator. In addition, we need to ensure that the copied operator only begins to be evaluated when the corresponding inverse part is computed, so we need to insert control dependencies to ensure the order in which the operators are executed. As shown in the following figure:

Figure: Forward and reverse diagram before and after the recompute function is enabled
For user convenience, MindSpore currently provides not only a recompute interface for individual operators, but also a recompute interface for Cell. When the user calls The Cell's recompute interface, all forward operators in the Cell are set to recomputed.
Taking the GPT-3 model as an example, the policy is set to recalculate the cell corresponding to the each layer, and then the output operator of the layer is set to non-recompute. The effect of recompute on the 72-layer GPT-3 network is shown in the following figure:
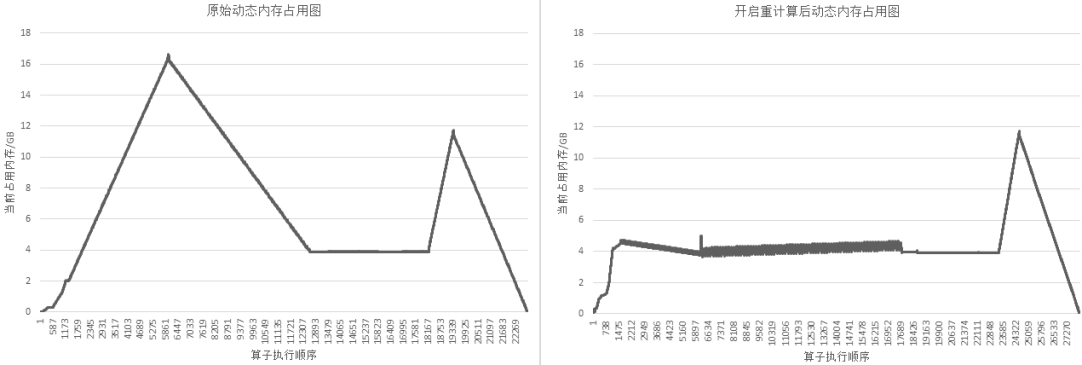
Figure: Comparison of GPT-3 memory usage before and after recalculation function is enabled
Operation Practice
The following is an illustration of the recomputation operation using an Ascend as an example:
Sample Code Description
Download the complete sample code: recompute.
The directory structure is as follows:
└─ sample_code
├─ recompute
└── example.py
...
example.py is the script that defines the network structure and execution flow. In order to emphasize the difference between before and after recomputation, recomputation is not enabled by default in this sample. If you need to enable it, please refer to the following configuration.
Network Definition
The network Net is formed by connecting the 10 sub-networks Block in nn.CellList in sequence, and Grad is used to derive Net to get the derivative with respect to the inputs of the network.
import numpy as np
from mindspore.nn import Cell
from mindspore.common import Tensor, Parameter
from mindspore import ops, nn
from mindspore.parallel.auto_parallel import AutoParallel
from mindspore.nn.utils import no_init_parameters
from mindspore.common.initializer import initializer, One
from mindspore import Parameter
class Block(Cell):
def __init__(self):
super(Block, self).__init__()
self.transpose1 = ops.Transpose()
self.transpose2 = ops.Transpose()
self.transpose3 = ops.Transpose()
self.transpose4 = ops.Transpose()
self.real_div1 = ops.RealDiv()
self.real_div2 = ops.RealDiv()
self.batch_matmul1 = ops.BatchMatMul()
self.batch_matmul2 = ops.BatchMatMul()
self.add = ops.Add()
self.softmax = ops.Softmax(-1)
self.dropout = ops.Dropout(0.9)
self.expand_dims = ops.ExpandDims()
self.sub = ops.Sub()
self.mul = ops.Mul()
self.y = Parameter(initializer(One(), [8, 128, 128], mindspore.float32))
def construct(self, x):
transpose1 = self.transpose1(x, (0, 2, 1, 3))
real_div1 = self.real_div1(transpose1, Tensor(2.37891))
transpose2 = self.transpose2(x, (0, 2, 3, 1))
real_div2 = self.real_div2(transpose2, Tensor(2.37891))
batch_matmul1 = self.batch_matmul1(real_div1, real_div2)
expand_dims = self.expand_dims(self.y, 1)
sub = self.sub(Tensor([1.0]), expand_dims)
mul = self.mul(sub, Tensor([-0.0001]))
add = self.add(mul, batch_matmul1)
soft_max = self.softmax(add)
dropout = self.dropout(soft_max)
transpose3 = self.transpose3(x, (0, 2, 1, 3))
batch_matmul2 = self.batch_matmul2(dropout[0], transpose3)
transpose4 = self.transpose4(batch_matmul2, (0, 2, 1, 3))
return transpose4
class Net(Cell):
def __init__(self):
super(Net, self).__init__()
self.blocks = nn.CellList()
for _ in range(10):
b = Block()
self.blocks.append(b)
def construct(self, x):
out = x
for i in range(10):
out = self.blocks[i](out)
return out
class Grad(Cell):
def __init__(self, net):
super(Grad, self).__init__()
self.grad = ops.GradOperation()
self.net = net
def construct(self, x):
grad_net = self.grad(self.net)
return grad_net(x)
Executing the Network
In this step, we need to define the network inputs, defer initialization of the network parameters and optimizer parameters through the no_init_parameters interface, and then call Grad in order to obtain the derivatives. Set the parallel mode to semi-automatic parallel mode through the top-level AutoParallel interface, with the following code:
import numpy as np
from mindspore.common import Tensor
from mindspore.nn.utils import no_init_parameters
from mindspore.parallel.auto_parallel import AutoParallel
input_x = Tensor(np.ones((8, 128, 16, 32)).astype(np.float32))
with no_init_parameters():
network = Net()
grad_network = Grad(network)
grad_network = AutoParallel(grad_network, parallel_mode="semi_auto")
output = grad_network(input_x)
print(output)
Running Script
The next command calls the corresponding script as follows:
export GLOG_v=1
python example.py
With the GLOG_v=1 command, we can print out the INFO level logs to see the network execution memory footprint as follows:
Device MOC memory size: 62420M
MindSpore Used memory size: 58196M
Used peak memory usage (without fragments): 245M
Actual peak memory usage (with fragments): 260M
You can see that the size of the dynamic memory footprint for executing this network is 167 MB. If we set the environment variable export MS_DEV_SAVE_GRAPHS=1 before executing the script, you can see that the xx_validate_xxx.ir file is generated in the directory where the script is executed. Open the xx_validate_xxx.ir file as follows, we can see that the calculation result of node %38 is needed for the calculation of node %41 (forward propagation operator) and node %291 (backward propagation operator), so the memory occupied by the calculation result of node %38 needs to wait until the calculation of node %291 is completed before it is released (here the % followed by the sequence number is related to the operator execution sequence). The reason for the long memory footprint of the node %38 computation result is that the order of the backpropagation is reversed from the forward propagation, and the backpropagation function corresponding to the first Block inside the 10 Blocks in the forward propagation is the last to be executed instead.
%38(equiv_11_real_div1) = PrimFunc_RealDiv(%37, Tensor(shape=[], dtype=Float32, value=2.37891)) {instance name: real_div2}cnode_attrs: {checkpoint: Bool(1)} cnode_primal_attrs: {unique_id: "10842"}
: (<Tensor[Float32], (8, 16, 128, 32)>, <Tensor[Float32], (), value=...>) -> (<Tensor[Float32], (8, 16, 128, 32)>)
# Fullname with scope: (Default/network-Grad/net-Net/blocks-CellList/0-Block/RealDiv-op0)
...
%41(equiv_8_batch_matmul1) = PrimFunc_BatchMatMul(%38, %40, Bool(0), Bool(0)) cnode_attrs: {checkpoint: Bool(1)}cnode_primal_attrs: {unique_id: "10839"}
: (<Tensor[Float32], (8, 16, 128, 32)>, <Tensor[Float32], (8, 16, 32, 128)>, <Bool, NoShape>, <Bool, NoShape>) -> (<Tensor[Float32], (8, 16, 128, 128)>)
# Fullname with scope: (Default/network-Grad/net-Net/blocks-CellList/0-Block/BatchMatMul-op0)
...
%291(CNode_549) = PrimFunc_BatchMatMul(%38, %287, Bool(1), Bool(0)) cnode_attrs: {checkpoint: Bool(1)} cnode_primal_attrs:{forward_node_name: "BatchMatMul_10839", forward_unique_id: "10839"}
: (<Tensor[Float32], (8, 16, 128, 32)>, <Tensor[Float32], (8, 16, 128, 128)>, <Bool, NoShape>, <Bool, NoShape>) -> (<Tensor[Float32], (8, 16, 32, 128)>)
# Fullname with scope: (Gradients/Default/network-Grad/net-Net/blocks-CellList/0-Block/Grad_BatchMatMul/BatchMatMul-op38)
If we do recomputation of the first Block, we can make the first Block to be released immediately after the forward part of the calculation is finished, and go for recomputation only at the time of reverse propagation, thus we can significantly shorten the time of memory occupancy and reduce the memory spikes. The code for using recomputation is as follows:
class Net(Cell):
def __init__(self):
super(Net, self).__init__()
self.blocks = nn.CellList()
for _ in range(10):
b = Block()
# Call the recompute interface on each Block to turn on recomputation
b.recompute()
self.blocks.append(b)
def construct(self, x):
out = x
for i in range(10):
out = self.blocks[i](out)
return out
After using recomputation, we then run the script as follows:
GLOG_v=1 python example.py
Checking the network execution memory footprint size again, as shown below, the dynamic memory footprint for executing this network is reduced to 65 MB.
Device MOC memory size: 62420M
MindSpore Used memory size: 58188M
Used peak memory usage (without fragments): 65M
Actual peak memory usage (with fragments): 76M
Open the xx_validate_xxx.ir file again, as shown below, and you can see that the first input to the backpropagation node %429 is node %416, which is copied based on the forward propagation node %38, and the memory occupied by the computation results of node %38 can be released after the computation of node %41, thus improving the memory reuse rate.
%38(equiv_183_real_div1) = PrimFunc_RealDiv(%37, Tensor(shape=[], dtype=Float32, value=2.37891)) {instance name: real_div2} cnode_attrs: {recompute_sub_graph: U64(0), recompute_id: I64(5), recompute: Bool(1), need_cse_after_recompute: Bool(1)} cnode_primal_attrs: {unique_id: "12172"}
: (<Tensor[Float32], (8, 16, 128, 32)>, <Tensor[Float32], (), value=...>) -> (<Tensor[Float32], (8, 16, 128, 32)>)
# Fullname with scope: (recompute_Default/network-Grad/net-Net/blocks-CellList/0-Block/RealDiv-op0)
...
%41(equiv_180_batch_matmul1) = PrimFunc_BatchMatMul(%38, %40, Bool(0), Bool(0)) cnode_attrs: {recompute_sub_graph: U64(0), recompute_id: I64(8), recompute: Bool(1), need_cse_after_recompute: Bool(1)} cnode_primal_attrs: {unique_id: "12169"}
: (<Tensor[Float32], (8, 16, 128, 32)>, <Tensor[Float32], (8, 16, 32, 128)>, <Bool, NoShape>, <Bool, NoShape>) -> (<Tensor[Float32], (8, 16, 128, 128)>)
# Fullname with scope: (recompute_Default/network-Grad/net-Net/blocks-CellList/0-Block/BatchMatMul-op0)
...
%416(CNode_820) = PrimFunc_RealDiv(%410, Tensor(shape=[], dtype=Float32, value=2.37891)) {instance name: real_div2} cnode_attrs: {recompute_sub_graph: U64(0), recompute_id: I64(5), duplicated: Bool(1), need_cse_after_recompute: Bool(1)}
: (<Tensor[Float32], (8, 16, 128, 32)>, <Tensor[Float32], (), value=...>) -> (<Tensor[Float32], (8, 16, 128, 32)>)
# Fullname with scope: (recompute_Default/network-Grad/net-Net/blocks-CellList/0-Block/RealDiv-op2)
...
%429(CNode_833) = PrimFunc_BatchMatMul(%416, %425, Bool(1), Bool(0)) cnode_attrs: {recompute_sub_graph: U64(0), target_grad: Bool(1), checkpoint: Bool(1)} cnode_primal_attrs: {forward_node_name: "BatchMatMul_12169", forward_unique_id: "12169"}
: (<Tensor[Float32], (8, 16, 128, 32)>, <Tensor[Float32], (8, 16, 128, 128)>, <Bool, NoShape>, <Bool, NoShape>) -> (<Tensor[Float32], (8, 16, 32, 128)>)
# Fullname with scope: (Gradients/recompute_Default/network-Grad/net-Net/blocks-CellList/9-Block/Grad_BatchMatMul/BatchMatMul-op38)