mindspore.dataset.audio.TimeMasking
- class mindspore.dataset.audio.TimeMasking(iid_masks=False, time_mask_param=0, mask_start=0, mask_value=0.0)[源代码]
给音频波形施加时域掩码。
Note
待处理音频维度需为(…, freq, time)。
参数:
iid_masks (bool, 可选) - 是否施加随机掩码,默认值:False。
time_mask_param (int, 可选): 当 iid_masks 为True时,掩码长度将从[0, time_mask_param]中均匀采样;当 iid_masks 为False时,直接使用该值作为掩码的长度。取值范围为[0, time_length],其中 time_length 为音频波形在时域的长度,默认值:0。
mask_start (int, 可选) - 添加掩码的起始位置,只有当 iid_masks 为True时,该值才会生效。取值范围为[0, time_length - time_mask_param],其中 time_length 为音频波形在时域的长度,默认值:0。
mask_value (float, 可选) - 掩码填充值,默认值:0.0。
异常:
TypeError - 当 iid_masks 的类型不为bool。
TypeError - 当 time_mask_param 的类型不为int。
ValueError - 当 time_mask_param 大于音频时域长度。
TypeError - 当 mask_start 的类型不为int。
ValueError - 当 mask_start 为负数。
TypeError - 当 mask_value 的类型不为float。
ValueError - 当 mask_value 为负数。
RuntimeError - 当输入音频的shape不为<…, freq, time>。
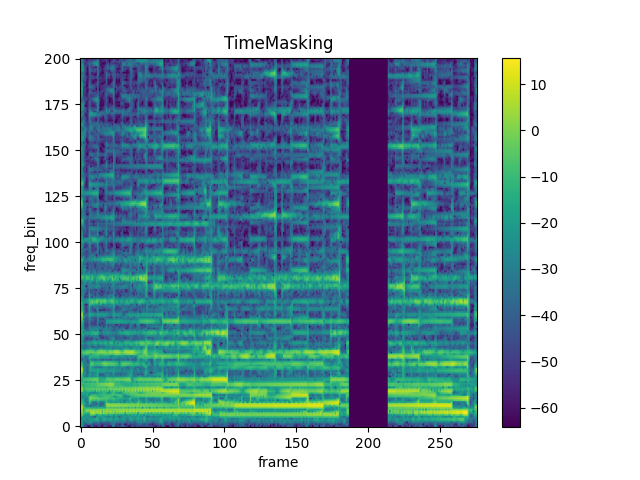
- 支持平台:
CPU
样例:
>>> import numpy as np >>> >>> waveform = np.random.random([4, 3, 2]) >>> numpy_slices_dataset = ds.NumpySlicesDataset(data=waveform, column_names=["audio"]) >>> transforms = [audio.TimeMasking(time_mask_param=1)] >>> numpy_slices_dataset = numpy_slices_dataset.map(operations=transforms, input_columns=["audio"])