网络迁移调试实例
![]()
本章将结合用例来介绍网络迁移的基本步骤、常用工具、定位问题的思路及解决方法。
这里以经典网络 ResNet50 为例,结合代码来详细介绍网络迁移方法。
对标网络分析与复现
确定迁移目标
网络迁移的第一步是确定迁移目标,即先找到一个合适的、可达成的标准,通常一个深度神经网络的交付目标包括以下四个部分:
网络实现:这是迁移目标中最基本的部分,有时同一个神经网络有不同的版本、同一个版本有不同的实现方式或者在相同的神经网络下使用不同的超参,这些差别会对最终的收敛精度和性能造成一定影响。通常,我们以神经网络作者本身的实现为准,也可以参考不同框架(例如TensorFlow、PyTorch等)的官方实现或其他主流开源工具箱(例如 MMDetection)。
数据集:相同的神经网络和参数,在不同的数据集上往往差别很大,因此我们需要确认迁移网络所使用的数据集。一些数据集的数据内容会频繁更新,确定数据集时需要注意数据集的版本、训练数据和测试数据划分比例等问题。
收敛精度:不同的框架、不同的GPU型号、是否为分布式训练等因素会对精度有所影响,在确定迁移目标时需要分析清楚对标的框架、硬件等信息。
训练性能:和收敛精度相同,训练性能主要受网络脚本、框架性能、GPU硬件本身和是否为分布式训练等因素影响。
ResNet50 迁移示例
ResNet50 是 CV 中经典的深度神经网络,有较多开发者关注和复现,而 PyTorch 的语法和 MindSpore 较为相似,因此,我们选择 PyTorch 作为对标框架。
PyTorch 官方实现脚本可参考 torchvision model 或者 英伟达 PyTorch 实现脚本,其中包括了主流 ResNet 系列网络的实现(ResNet18、ResNet34、ResNet50、ResNet101、ResNet152)。ResNet50 所使用的数据集为 ImageNet2012,收敛精度可参考 PyTorch Hub。
开发者可以基于 PyTorch 的 ResNet50 脚本直接在对标的硬件环境下运行,然后计算出性能数据,也可以参考同硬件环境下的官方数据。例如,当我们对标 Nvidia DGX-1 32GB(8x V100 32GB) 硬件时,可参考 Nvidia 官方发布的 ResNet50 性能数据。
复现迁移目标
网络迁移目标确定完成后,接下来要做的就是复现指标。复现标杆数据对后续精度和性能调优十分重要,当我们在 MindSpore 开发的网络和对标脚本有精度/性能差距时,很多时候都是以标杆数据作为基准,一步一步地分析迁移脚本和对标脚本的差别,如果对标脚本无法复现指标,那我们以此为基准开发的 MindSpore 脚本就很难达到迁移目标。复现迁移指标时,不仅要复现训练阶段,推理阶段也同样重要。
需要注意的是,对于部分网络,使用相同的硬件环境和脚本,最终达到的收敛精度和性能也可能与原作者提出的结果有细微差别,这属于正常的波动范围,我们在迁移网络时要把这种波动考虑在内。
复现单Step结果
复现单 Step 结果主要是为了接下来的脚本开发和网络调优。对于复杂的神经网络,完整的训练需要耗时几天甚至几个月,如果仅以最终的训练精度和结果做参考,会极大地降低开发效率。因此,我们需要提前复现单 Step 的运行结果,即获取只执行第一个 Step 后网络的状态(该状态是经历了数据预处理、权重初始化、正向计算、loss 计算、反向梯度计算和优化器更新之后的结果,覆盖了网络训练的全部环节),并以此为对照展开后续的开发工作。
脚本开发
脚本开发前分析
在开始真正的开发脚本前,需要进行对标脚本分析。脚本分析的目的是识别出 MindSpore 与对标框架相比缺失的算子或功能。具体方法可以参考脚本评估教程。
MindSpore 已支持绝大多数常用 功能 和 算子。MindSpore 既支持动态图(PyNative)模式,又支持静态图(Graph)模式,动态图模式灵活、易于调试,因此动态图模式主要用于网络调试,静态图模式性能好,主要用于整网训练,在分析缺失算子和功能时,要分别分析这两种模式。
如果发现有缺失的算子和功能,首先可考虑基于当前算子或功能来组合出缺失的算子和功能,对于主流的 CV 和 NLP 类网络,新的缺失算子一般都可以通过组合已有算子的方式来解决。
组合的算子可以通过 Cell 的方式实现,在 MindSpore 中,nn类算子 就是通过这种方式实现的。例如下面的 ReduceSumExp 算子,它是由已有的Exp、ReduceSum、Log小算子组合而成:
class ReduceLogSumExp(Cell):
def __init__(self, axis, keep_dims=False):
super(ReduceLogSumExp, self).__init__()
validator.check_value_type('axis', axis, [int, list, tuple], self.cls_name)
validator.check_value_type('keep_dims', keep_dims, [bool], self.cls_name)
self.axis = axis
self.exp = ops.Exp()
self.sum = ops.ReduceSum(keep_dims)
self.log = ops.Log()
def construct(self, x):
exp = self.exp(x)
sumexp = self.sum(exp, self.axis)
logsumexp = self.log(sumexp)
return logsumexp
如果缺失的功能和算子无法规避,或者组合算子性能较差,严重影响网络的训练和推理,可联系 MindSpore社区 反馈,我们会有专门的工作人员为您解决。
ResNet50 迁移示例
以下为 ResNet 系列网络结构:
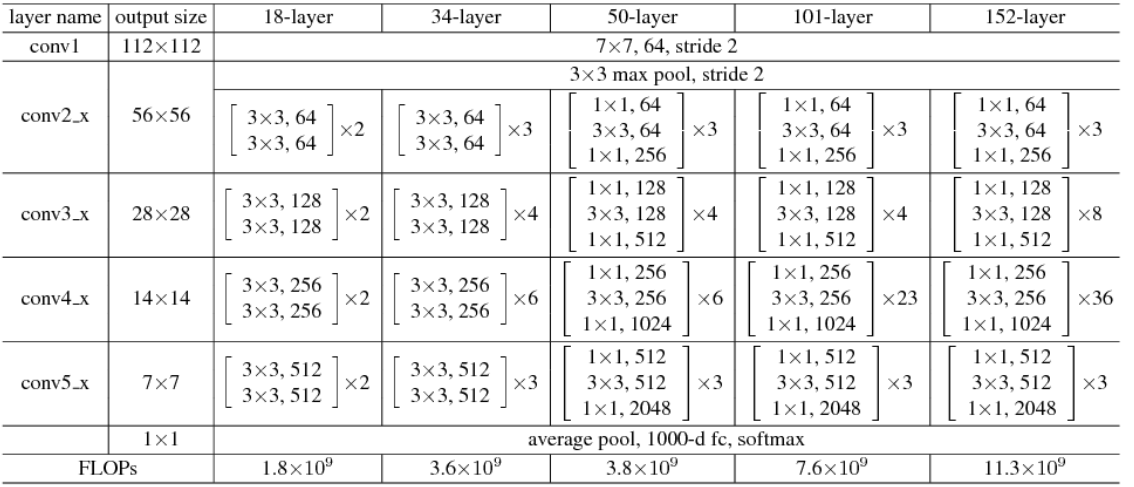
PyTorch 实现的 ResNet50 脚本参考 torchvision model。
我们可以基于算子和功能两个方面分析:
算子分析
PyTorch 使用算子 |
MindSpore 对应算子 |
是否支持该算子所需功能 |
|---|---|---|
|
|
是 |
|
|
是 |
|
|
是 |
|
|
是 |
|
无 |
不支持 |
|
|
是 |
|
|
是 |
注:对于 PyTorch 脚本,MindSpore 提供了 PyTorch 算子映射,可直接查询该算子是否支持。
功能分析
Pytorch 使用功能 |
MindSpore 对应功能 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
(由于MindSpore 和 PyTorch 在接口设计上不完全一致,这里仅列出关键功能的比对)
经过算子和功能分析,我们发现,相比 PyTorch,MindSpore 功能上没有缺失,但算子上缺失 nn.AdaptiveAvgPool ,这时我们需要更一步的分析,该缺失算子是否有可替代方案。在 ResNet50 网络中,输入的图片 shape 是固定的,统一为 N,3,224,224,其中 N 为 batch size,3 为通道的数量,224 和 224 分别为图片的宽和高,网络中改变图片大小的算子有 Conv2d 和 Maxpool2d,这两个算子对shape 的影响是固定的,因此,nn.AdaptiveAvgPool2D 的输入和输出 shape 是可以提前确定的,只要我们计算出 nn.AdaptiveAvgPool2D 的输入和输出 shape,就可以通过 nn.AvgPool 或 nn.ReduceMean 来实现,所以该算子的缺失是可替代的,并不影响网络的训练。
数据预处理
要理解一个神经网络的实现,首先要清楚网络的输入数据,因此,数据预处理是脚本开发的第一个环节。MindSpore 设计了一个专门进行数据处理的模块 - MindData,使用 MindData 进行数据预处理主要包括以下几个步骤:
传入数据路径,读取数据文件。
解析数据。
数据处理(如常见数据切分、shuffle、数据增强等操作)。
数据分发(以 batch_size 为单位分发数据,分布式训练涉及多机分发)。
在读取和解析数据过程中,MindSpore 提供了一种更友好的数据格式 - MindRecord。用户可以将常规格式的数据集转换为 MindSpore数据格式,即 MindRecord,从而方便地加载到 MindSpore 中进行训练。同时,MindSpore 在部分场景做了性能优化,使用 MindRecord 数据格式可以获得更好的性能。
数据处理通常是数据准备中最耗时的阶段,大部分对数据的操作都被包含在这一步骤里,例如 CV 类网络中的Resize、Rescale、Crop 等操作。MindSpore 提供了一套常用的数据处理集成接口,用户可以不用自己实现而直接调用这些接口,这些集成接口不仅可以提升用户的易用性,还可以提升数据预处理的性能,减少训练过程中数据准备的耗时。具体可以参考数据预处理教程。
在数据分发环节,MindData 提供了极为简洁的 API,可以通过直接调用 batch、repeat 等操作完成数据的 batch 组合、重复等操作。
当完成以上4个步骤后,我们理论上使用 MindSpore 脚本和对标脚本处理数据集后,可以得到完全相同的数据(如果有引入随机情况的操作需要去除)。
ResNet50 迁移示例
ResNet50 网络使用的是 ImageNet2012 数据集,其数据预处理的 PyTorch 代码如下:
# sample execution (requires torchvision)
from PIL import Image
from torchvision import transforms
input_image = Image.open(filename)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
通过观察以上代码,我们发现 ResNet50 的数据预处理主要做了 Resize、CenterCrop、Normalize 操作,在 MindSpore 中实现这些操作有两种方式,一是使用 MindSpore 的数据处理模块 MindData 来调用已封装好的数据预处理接口,二是通过 自定义数据集 进行加载。这里更建议开发者选择第一种方式,这样不仅可以减少重复代码的开发,减少错误的引入,还可以得到更好的数据处理性能。更多关于MindData数据处理的介绍,可参考 数据处理。
以下是基于 MindData 开发的数据处理函数:
import os
import mindspore as ms
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
import mindspore.dataset.transforms as transforms
def create_dataset(dataset_path, batch_size=32, rank_size=1, rank_id=0, do_train=True):
"""
create a train or eval imagenet2012 dataset for resnet50
Args:
dataset_path(string): the path of dataset.
batch_size(int): the batch size of dataset. Default: 32
rank_size(int): total num of devices for training. Default: 1,
greater than 1 in distributed training
rank_id(int): logical sequence in all devices. Default: 1,
can be greater than i in distributed training
Returns:
dataset
"""
data_set = ds.ImageFolderDataset(dataset_path, num_parallel_workers=8, shuffle=do_train,
num_shards=rank_size, shard_id=rank_id)
mean = [0.485 * 255, 0.456 * 255, 0.406 * 255]
std = [0.229 * 255, 0.224 * 255, 0.225 * 255]
# define map operations
trans = [
vision.Decode(),
vision.Resize(256),
vision.CenterCrop(224),
vision.Normalize(mean=mean, std=std),
vision.HWC2CHW()
]
type_cast_op = transforms.TypeCast(ms.int32)
data_set = data_set.map(operations=trans, input_columns="image", num_parallel_workers=8)
data_set = data_set.map(operations=type_cast_op, input_columns="label", num_parallel_workers=8)
# apply batch operations
data_set = data_set.batch(batch_size, drop_remainder=do_train)
return data_set
在以上代码中我们可以发现,针对常用的经典数据集(如 ImageNet2012),MindData 也为我们提供了 ImageFolderDataset 接口直接读取原始数据,省去了手写代码读取文件的工作量。需要注意的是,单机训练和多机分布式训练时 MindData 创建数据集的参数是不一样的,分布式训练需要额外指定 num_shard 和 shard_id 两个参数。
子网开发
通常子网开发包含两个部分:训练子网和 loss 子网,其中训练子网可根据网络的复杂程度决定是否继续划分。直接开发一个大型的神经网络脚本可能会让我们无从下手,因此,我们可以将网络中不同模块或子模块作为一个个子网抽离出来单独开发,这样可以保证各个子网并行开发,互相不受干扰。子网开发完成后,还可以固定子网输入和权重,与对标脚本的子网代码形成对比,作为后续网络开发的测试用例。
在精度调优阶段,我们常常会遇到精度不达标的情况,这时我们会重新审视已开发的脚本并逐行排查。而使用子网方式开发脚本并形成测试用例可以高效地帮助我们排除怀疑点,从几十个算子里寻找可疑点,要比从成百上千个算子中找可疑点轻松得多,尤其是在很多时候,同一个子网会被重复调用多次,当我们以子网为单位排查时,可以减少很多工作量。
ResNet50 迁移示例
分析 ResNet50 网络代码,主要可以分成以下几个子网:
conv1x1、conv3x3:定义了不同 kernel_size 的卷积。
BasicBlock:ResNet 系列网络中 ResNet18 和 ResNet34 的最小子网,由 Conv、BN、ReLU 和 残差组成。
BottleNeck:ResNet 系列网络中 ResNet50、ResNet101 和 ResNet152 的最小子网,相比 BasicBlock 多了一层 Conv、BN 和 ReLU的结构,下采样的卷积位置也做了改变。
ResNet:封装了 BasiclBlock、BottleNeck 和 Layer 结构的网络,传入不同的参数即可构造不同的ResNet系列网络。在该结构中,也使用了一些 PyTorch 自定义的初始化功能。
基于以上子网划分,我们结合 MindSpore 语法,重新完成上述开发。
权重初始化可参考 MindSpore 已定义的权重初始化方法:
重新开发 conv3x3 和 conv1x1
import mindspore.nn as nn
def _conv3x3(in_channel, out_channel, stride=1):
return nn.Conv2d(in_channel, out_channel, kernel_size=3, stride=stride,
padding=0, pad_mode='same')
def _conv1x1(in_channel, out_channel, stride=1):
return nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=stride,
padding=0, pad_mode='same')
重新开发 BasicBlock 和 BottleNeck:
class ResidualBlockBase(nn.Cell):
def __init__(self,
in_channel,
out_channel,
stride=1):
super(ResidualBlockBase, self).__init__()
self.conv1 = _conv3x3(in_channel, out_channel, stride=stride)
self.bn1d = _bn(out_channel)
self.conv2 = _conv3x3(out_channel, out_channel, stride=1)
self.bn2d = _bn(out_channel)
self.relu = nn.ReLU()
self.down_sample = False
if stride != 1 or in_channel != out_channel:
self.down_sample = True
self.down_sample_layer = None
if self.down_sample:
self.down_sample_layer = nn.SequentialCell([_conv1x1(in_channel, out_channel, stride),
_bn(out_channel)])
def construct(self, x):
identity = x
out = self.conv1(x)
out = self.bn1d(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2d(out)
if self.down_sample:
identity = self.down_sample_layer(identity)
out = out + identity
out = self.relu(out)
return out
class ResidualBlock(nn.Cell):
expansion = 4
def __init__(self,
in_channel,
out_channel,
stride=1):
super(ResidualBlock, self).__init__()
self.stride = stride
channel = out_channel // self.expansion
self.conv1 = _conv1x1(in_channel, channel, stride=1)
self.bn1 = _bn(channel)
if self.stride != 1:
self.e2 = nn.SequentialCell([_conv3x3(channel, channel, stride=1), _bn(channel),
nn.ReLU(), nn.MaxPool2d(kernel_size=2, stride=2, pad_mode='same')])
else:
self.conv2 = _conv3x3(channel, channel, stride=stride)
self.bn2 = _bn(channel)
self.conv3 = _conv1x1(channel, out_channel, stride=1)
self.bn3 = _bn_last(out_channel)
self.relu = nn.ReLU()
self.down_sample = False
if stride != 1 or in_channel != out_channel:
self.down_sample = True
self.down_sample_layer = None
if self.down_sample:
self.down_sample_layer = nn.SequentialCell([_conv1x1(in_channel, out_channel, stride), _bn(out_channel)])
def construct(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
if self.stride != 1:
out = self.e2(out)
else:
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.down_sample:
identity = self.down_sample_layer(identity)
out = out + identity
out = self.relu(out)
return out
重新开发 ResNet 系列整网:
class ResNet(nn.Cell):
"""
ResNet architecture.
Args:
block (Cell): Block for network.
layer_nums (list): Numbers of block in different layers.
in_channels (list): Input channel in each layer.
out_channels (list): Output channel in each layer.
strides (list): Stride size in each layer.
num_classes (int): The number of classes that the training images are belonging to.
Returns:
Tensor, output tensor.
Examples:
>>> ResNet(ResidualBlock,
>>> [3, 4, 6, 3],
>>> [64, 256, 512, 1024],
>>> [256, 512, 1024, 2048],
>>> [1, 2, 2, 2],
>>> 10)
"""
def __init__(self,
block,
layer_nums,
in_channels,
out_channels,
strides,
num_classes):
super(ResNet, self).__init__()
if not len(layer_nums) == len(in_channels) == len(out_channels) == 4:
raise ValueError("the length of layer_num, in_channels, out_channels list must be 4!")
self.conv1 = _conv7x7(3, 64, stride=2)
self.bn1 = _bn(64)
self.relu = ops.ReLU()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode="same")
self.layer1 = self._make_layer(block,
layer_nums[0],
in_channel=in_channels[0],
out_channel=out_channels[0],
stride=strides[0])
self.layer2 = self._make_layer(block,
layer_nums[1],
in_channel=in_channels[1],
out_channel=out_channels[1],
stride=strides[1])
self.layer3 = self._make_layer(block,
layer_nums[2],
in_channel=in_channels[2],
out_channel=out_channels[2],
stride=strides[2])
self.layer4 = self._make_layer(block,
layer_nums[3],
in_channel=in_channels[3],
out_channel=out_channels[3],
stride=strides[3])
self.mean = ops.ReduceMean(keep_dims=True)
self.flatten = nn.Flatten()
self.end_point = _fc(out_channels[3], num_classes)
def _make_layer(self, block, layer_num, in_channel, out_channel, stride):
"""
Make stage network of ResNet.
Args:
block (Cell): Resnet block.
layer_num (int): Layer number.
in_channel (int): Input channel.
out_channel (int): Output channel.
stride (int): Stride size for the first convolutional layer.
Returns:
SequentialCell, the output layer.
Examples:
>>> _make_layer(ResidualBlock, 3, 128, 256, 2)
"""
layers = []
resnet_block = block(in_channel, out_channel, stride=stride)
layers.append(resnet_block)
for _ in range(1, layer_num):
resnet_block = block(out_channel, out_channel, stride=1)
layers.append(resnet_block)
return nn.SequentialCell(layers)
def construct(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
c1 = self.maxpool(x)
c2 = self.layer1(c1)
c3 = self.layer2(c2)
c4 = self.layer3(c3)
c5 = self.layer4(c4)
out = self.mean(c5, (2, 3))
out = self.flatten(out)
out = self.end_point(out)
return out
传入 ResNet50 层数信息,构造 ResNet50 整网:
def resnet50(class_num=10):
"""
Get ResNet50 neural network.
Args:
class_num (int): Class number.
Returns:
Cell, cell instance of ResNet50 neural network.
Examples:
>>> net = resnet50(10)
"""
return ResNet(ResidualBlock,
[3, 4, 6, 3],
[64, 256, 512, 1024],
[256, 512, 1024, 2048],
[1, 2, 2, 2],
class_num)
经过以上步骤,基于 MindSpore 的 ResNet50 整网结构和各子网结构已经开发完成,接下来就是开发其他模块。
其他模块
其他模块通常包括:反向构造、梯度裁剪、优化器、学习率生成等,这些模块要么本身结构单一,要么依赖已开发完成的子网结果才能和对标脚本形成对比。相比子网开发,这些模块的脚本开发难度更小一些。
ResNet50 迁移示例
关于其他训练配置,可以参考 英伟达训练 ResNet50 的配置信息,ResNet50 的训练主要涉及以下几项:
使用了 SGD + Momentum 优化器
使用了 WeightDecay 功能(但 BatchNorm 的 gamma 和 bias 没有使用)
使用了 cosine LR schedule
使用了 Label Smoothing
实现带 Momentum 的 SGD 优化器,除 BN 的 gamma 和 bias 外,其他权重应用 WeightDecay :
# define opt
decayed_params = []
no_decayed_params = []
for param in net.trainable_params():
if 'beta' not in param.name and 'gamma' not in param.name and 'bias' not in param.name:
decayed_params.append(param)
else:
no_decayed_params.append(param)
group_params = [{'params': decayed_params, 'weight_decay': weight_decay},
{'params': no_decayed_params},
{'order_params': net.trainable_params()}]
opt = Momentum(group_params, lr, momentum)
实现 cosine LR schedule,可以参考 MindSpore Cosine Decay LR
定义 Loss 函数和实现 Label Smoothing:
import mindspore.nn as nn
import mindspore as ms
from mindspore.nn import LossBase
import mindspore.ops as ops
# define cross entropy loss
class CrossEntropySmooth(LossBase):
"""CrossEntropy"""
def __init__(self, sparse=True, reduction='mean', smooth_factor=0., num_classes=1000):
super(CrossEntropySmooth, self).__init__()
self.onehot = ops.OneHot()
self.sparse = sparse
self.on_value = ms.Tensor(1.0 - smooth_factor, ms.float32)
self.off_value = ms.Tensor(1.0 * smooth_factor / (num_classes - 1), ms.float32)
self.ce = nn.SoftmaxCrossEntropyWithLogits(reduction=reduction)
def construct(self, logit, label):
if self.sparse:
label = self.onehot(label, ops.shape(logit)[1], self.on_value, self.off_value)
loss = self.ce(logit, label)
return loss
# define loss with label smooth
label_smooth_factor = 0.1
loss = CrossEntropySmooth(sparse=True, reduction="mean",smooth_factor=label_smooth_factor, num_classes=1000)
超参对比
当各子网已经打通,最后一步要做的是和对标脚本对齐超参,保证网络结构一致。需要注意的是,在不同的框架上,同一套超参可能有不同的精度表现,在迁移网络时不一定要严格按照对标脚本的超参进行设置,可在不改变网络结构的情况下进行微调。
ResNet50 迁移示例
在 ResNet50 的训练中,主要涉及以下超参:
momentum =0.875
batch_size = 256
learning rate = 0.256
learing rate schedule = cosine
weight_decay = 1/32768
label_smooth = 0.1
epoch size = 90
流程打通
经过以上步骤后,我们已经开发完了网络迁移的必备脚本,接下来就是打通单机训练、分布式训练、推理流程。
单机训练
ResNet50 迁移示例
为了更好的阅读代码,建议按照以下结构组织脚本:
.
├── scripts
│ ├── run_distribute_train.sh # 启动Ascend分布式训练(8卡)
│ ├── run_eval.sh # 启动Ascend评估
│ └── run_standalone_train.sh # 启动Ascend单机训练(单卡)
├── src
│ ├── config.py # 配置文件
│ ├── cross_entropy_smooth.py # 损失定义
│ ├── dataset.py # 数据预处理
│ └── resnet.py # 网络结构
├── eval.py # 推理流程
└── train.py # 训练流程
2 directories, 9 files
其中 train.py 定义如下:
"""train resnet."""
import os
import argparse
import ast
import mindspore as ms
from mindspore.nn import Momentum
from mindspore.communication import init
from mindspore.common import initializer
import mindspore.nn as nn
from src.config import config
from src.dataset import create_dataset
from src.resnet import resnet50
from src.cross_entropy_smooth import CrossEntropySmooth
ms.set_seed(1)
parser = argparse.ArgumentParser(description='Image classification')
parser.add_argument('--run_distribute', type=ast.literal_eval, default=False, help='Run distribute')
parser.add_argument('--dataset_path', type=str, default=None, help='Dataset path')
args_opt = parser.parse_args()
if __name__ == '__main__':
device_id = int(os.getenv('DEVICE_ID', '0'))
rank_size = int(os.getenv('RANK_SIZE', '1'))
rank_id = int(os.getenv('RANK_ID', '0'))
# init context
ms.set_context(mode=ms.GRAPH_MODE, device_target='Ascend', device_id=device_id)
if rank_size > 1:
ms.set_auto_parallel_context(device_num=rank_size, parallel_mode=ms.ParallelMode.DATA_PARALLEL,
gradients_mean=True)
ms.set_auto_parallel_context(all_reduce_fusion_config=[85, 160])
init()
# create dataset
dataset = create_dataset(args_opt.dataset_path, config.batch_size, rank_size, rank_id)
step_size = dataset.get_dataset_size()
# define net
net = resnet50(class_num=config.class_num)
# init weight
for _, cell in net.cells_and_names():
if isinstance(cell, nn.Conv2d):
cell.weight.set_data(initializer.initializer(initializer.XavierUniform(),
cell.weight.shape,
cell.weight.dtype))
if isinstance(cell, nn.Dense):
cell.weight.set_data(initializer.initializer(initializer.TruncatedNormal(),
cell.weight.shape,
cell.weight.dtype))
lr = nn.dynamic_lr.cosine_decay_lr(config.lr_end, config.lr, config.epoch_size * step_size,
step_size, config.warmup)
# define opt
decayed_params = []
no_decayed_params = []
for param in net.trainable_params():
if 'beta' not in param.name and 'gamma' not in param.name and 'bias' not in param.name:
decayed_params.append(param)
else:
no_decayed_params.append(param)
group_params = [{'params': decayed_params, 'weight_decay': config.weight_decay},
{'params': no_decayed_params},
{'order_params': net.trainable_params()}]
opt = Momentum(group_params, lr, config.momentum)
# define loss
loss = CrossEntropySmooth(sparse=True, reduction="mean", smooth_factor=config.label_smooth_factor,
num_classes=config.class_num)
# define model
model = ms.Model(net, loss_fn=loss, optimizer=opt, metrics={'acc'})
# define callbacks
time_cb = ms.TimeMonitor(data_size=step_size)
loss_cb = ms.LossMonitor()
cb = [time_cb, loss_cb]
if config.save_checkpoint:
#config_ck = CheckpointConfig(save_checkpoint_steps=config.save_checkpoint_epochs * step_size,
config_ck = ms.CheckpointConfig(save_checkpoint_steps=5,
keep_checkpoint_max=config.keep_checkpoint_max)
ckpt_cb = ms.ModelCheckpoint(prefix="resnet", directory=config.save_checkpoint_path, config=config_ck)
cb += [ckpt_cb]
model.train(config.epoch_size, dataset, callbacks=cb, sink_size=step_size, dataset_sink_mode=False)
注意:关于目录中其他文件的代码,可以参考 MindSpore ModelZoo 的 ResNet50 实现(该脚本融合了其他 ResNet 系列网络及ResNet-SE 网络,具体实现可能和对标脚本有差异)。
分布式训练
分布式训练相比单机训练对网络结构没有影响,可以通过调用 MindSpore 提供的分布式训练接口改造单机脚本即可完成分布式训练,具体可参考 分布式训练教程。
ResNet50 迁移示例
对单机训练脚本添加以下接口:
import os
import mindspore as ms
from mindspore.communication import init
device_id = int(os.getenv('DEVICE_ID', '0'))
rank_size = int(os.getenv('RANK_SIZE', '1'))
rank_id = int(os.getenv('RANK_ID', '0'))
# init context
ms.set_context(mode=ms.GRAPH_MODE, device_target='Ascend', device_id=device_id)
if rank_size > 1:
ms.set_auto_parallel_context(device_num=rank_size, parallel_mode=ms.ParallelMode.DATA_PARALLEL,
gradients_mean=True)
ms.set_auto_parallel_context(all_reduce_fusion_config=[85, 160])
# init distribute training
init()
修改 create_dataset 接口,使数据加载时对数据进行 shard 操作以支持分布式训练:
import os
import mindspore.dataset as ds
device_id = int(os.getenv('DEVICE_ID', '0'))
rank_size = int(os.getenv('RANK_SIZE', '1'))
rank_id = int(os.getenv('RANK_ID', '0'))
# rank_size is greater than 1 for distributed training
dataset = create_dataset(args_opt.dataset_path, config.batch_size, rank_size, rank_id)
# ...
推理
推理流程与训练相比有以下不同:
无需定义优化器
无需进行权重初始化
网络定义后需要加载已训练好的 CheckPoint
定义计算推理精度的 metric
ResNet50 迁移示例
修改后的推理脚本:
"""train resnet."""
import os
import argparse
import mindspore as ms
from mindspore.nn import SoftmaxCrossEntropyWithLogits
from src.config import config
from src.dataset import create_dataset
from src.resnet import resnet50
from src.cross_entropy_smooth import CrossEntropySmooth
parser = argparse.ArgumentParser(description='Image classification')
parser.add_argument('--checkpoint_path', type=str, default=None, help='Checkpoint file path')
parser.add_argument('--dataset_path', type=str, default=None, help='Dataset path')
args_opt = parser.parse_args()
ms.set_seed(1)
if __name__ == '__main__':
device_id = int(os.getenv('DEVICE_ID', '0'))
# init context
ms.set_context(mode=ms.GRAPH_MODE, device_target='Ascend', device_id=device_id)
# create dataset
dataset = create_dataset(args_opt.dataset_path, config.batch_size, do_train=False)
step_size = dataset.get_dataset_size()
# define net
net = resnet50(class_num=config.class_num)
# load checkpoint
param_dict = ms.load_checkpoint(args_opt.checkpoint_path)
ms.load_param_into_net(net, param_dict)
net.set_train(False)
# define loss, model
loss = CrossEntropySmooth(sparse=True, reduction='mean', smooth_factor=config.label_smooth_factor,
num_classes=config.class_num)
# define model
model = ms.Model(net, loss_fn=loss, metrics={'top_1_accuracy', 'top_5_accuracy'})
# eval model
res = model.eval(dataset)
print("result:", res, "ckpt=", args_opt.checkpoint_path)
问题定位
在流程打通中可能会遇到一些中断训练的问题,可以参考 网络训练调试教程 定位和解决。
完整示例
完整示例请参考链接:https://gitee.com/mindspore/docs/tree/r1.8/docs/sample_code/migration_sample
精度调优
在打通流程后,就可以通过训练和推理两个步骤获得网络训练的精度。通常情况下,我们很难一次就复现对标脚本的精度,需要通过精度调优来逐渐提高精度,精度调优相比性能调优不够直观,效率低,工作量大。
性能调优
通常我们所指的性能调优是在固定数据集、网络规模和硬件数量的情况下提高训练性能,而通过改变数据集大小、网络规模、硬件数量来提高性能是显然的,不在本文的讨论范围内。
除非性能问题已严重阻碍了精度调试,否则性能调优一定要放在精度达标以后进行,这其中主要有两个原因:一是在定位精度问题时很多修改会影响性能,使得已经调优过的性能再次未达标,可能浪费工作量;二是性能调优时有可能引入新的精度问题,如果没有已经达标的精度作为看护,后面再定位这次引入的精度问题难度会极大的增加。
分析Profiling数据
分析Profiling数据是性能调优阶段必不可少的步骤,MindSpore 的性能和精度调优工具 MindInsight 提供了丰富的性能和精度调优方法,对于性能调优,最重要的信息就是Profiling数据。Profiling可以收集整网训练过程中端到端的详细性能数据,包含数据准备和迭代轨迹。在迭代轨迹中,你可以看到每个算子的起始运行时间、结束运行时间、调用次数和调用顺序等非常详细的信息,这对我们性能调优非常有帮助。生成Profiling数据的方式如下:
import mindspore as ms
from mindspore import nn
# init context
ms.set_context(mode=ms.GRAPH_MODE, device_target='Ascend', device_id=int(os.environ["DEVICE_ID"]))
# init profiler, profiling data will be stored under folder ./data by default
profiler = ms.Profiler()
# ...
# start training
ms.Model.train()
# end training, parse profiling data to readable text
profiler.analyse()
关于Profiling更详细的使用方法,可以参考 Profiling 性能分析方法。
获取到 Profiling 数据后,我们需要分析出性能瓶颈的阶段和算子,然后对其进行优化,分析的过程可以参考 性能调优指导。
常见问题及相应优化方法
MindData 性能问题
单Step性能抖动、数据队列一段时间内持续为空的情况都是由于数据预处理部分性能较差,使得数据处理速度跟不上单Step迭代速度导致,这两个现象通常成对出现。
当数据处理速度较慢时,队列从最开始的满队列情况逐渐消耗为空队列,训练进程会开始等待空队列填入数据,一旦有新的数据填入,网络才会继续进行单Step训练。由于数据处理没有队列作为缓冲,数据处理的性能抖动直接体现在单Step的性能上,因此还会造成单Step性能抖动。
关于MindData的性能问题,可以参考 MindInsight 组件的 数据准备性能分析,其给出了MindData 性能的常见问题及解决方法。
多机同步性能问题
当进行分布式训练时,在一个Step的训练过程中,完成前向传播和梯度计算后,各个机器开始进行AllReduce梯度同步,AllReduce同步时间主要受权重数量、机器数量影响,对于越复杂、机器规模越大的网络,其 AllReduce 梯度更新时间也越久,此时我们可以进行AllReduce 切分来优化这部分耗时。
正常情况下,AllReduce 梯度同步会等所有反向算子执行结束,也就是对所有权重都计算出梯度后再一次性同步所有机器的梯度,而使用AllReduce切分后,我们可以在计算出一部分权重的梯度后,就立刻进行这部分权重的梯度同步,这样梯度同步和剩余算子的梯度计算可以并行执行,也就隐藏了这部分 AllReduce 梯度同步时间。切分策略通常是手动尝试,寻找一个最优的方案(支持切分大于两段)。 以 ResNet50网络 为例,该网络共有 160 个 权重, [85, 160] 表示第 0 至 85个权重计算完梯度后立刻进行梯度同步,第 86 至 160 个 权重计算完后再进行梯度同步,这里共切分两段,因此需要进行两次梯度同步。代码实现如下:
device_id = int(os.getenv('DEVICE_ID', '0'))
rank_size = int(os.getenv('RANK_SIZE', '1'))
rank_id = int(os.getenv('RANK_ID', '0'))
# init context
ms.set_context(mode=ms.GRAPH_MODE, device_target='Ascend', device_id=device_id)
if rank_size > 1:
ms.set_auto_parallel_context(device_num=rank_size, parallel_mode=ms.ParallelMode.DATA_PARALLEL,
gradients_mean=True)
ms.set_auto_parallel_context(all_reduce_fusion_config=[85, 160])
init()
算子性能问题
单算子耗时久、对于同一种算子在不同shape或者不同 datatype 下性能差异较大的情况主要是由算子性能问题引起,通常有以下两个解决思路:
使用计算量更小的数据类型。例如,同一个算子在 float16 和 float32 下精度无明显差别,可使用计算量更小的 float16 格式。
使用算法相同的其他算子规避。
如果您发现有性能较差的算子时,建议联系 MindSpore社区 反馈,我们确认为性能问题后会及时优化。
框架性能问题
转换算子过多(TransData、Cast类算子)且耗时明显时,如果是我们手动加入的Cast算子,可分析其必要性,如果对精度没有影响,可去掉冗余的Cast、TransData算子。
如果是MindSpore自动生成的转换算子过多,可能是MindSpore框架针对某些特殊情况没有充分优化,可联系 MindSpore社区 反馈。
其他通用优化方法
使用自动混合精度
混合精度训练方法是通过混合使用单精度和半精度数据格式来加速深度神经网络训练的过程,同时保持了单精度训练所能达到的网络精度。混合精度训练能够加速计算过程,同时减少内存使用和存取,并使得在特定的硬件上可以训练更大的模型或 batch size。
具体可参考 混合精度教程。
使能图算融合
图算融合是 MindSpore 特有的网络性能优化技术。它可以通过自动分析和优化现有网络计算图逻辑,并结合目标硬件能力,对计算图进行计算化简和替代、算子拆分和融合、算子特例化编译等优化,以提升设备计算资源利用率,实现对网络性能的整体优化。相比传统优化技术,图算融合具有多算子跨边界联合优化、与算子编译跨层协同、基于Polyhedral的算子即时编译等独特优势。另外,图算融合只需要用户打开对应配置后,整个优化过程即可自动完成,不需要网络开发人员进行其它额外感知,使得用户可以聚焦网络算法实现。
图算融合的适用场景包括:对网络执行时间具有较高性能要求的场景;通过拼接基本算子实现自定义组合算子,并希望对这些基本算子进行自动融合,以提升自定义组合算子性能的场景。
具体可参考 图算融合教程。