Communication Subgraph Extraction and Reuse
![]()
Overview
In order to improve the accuracy of the model, it is a common means to continuously expand the model size, and it is not uncommon to see large models with more than 100 million parameters at present. However, as the scale of large models such as Pangu increases, the number of communication operators required for distributed training also rises dramatically. It will increase the communication time consumption for model compilation, and consume a large amount of stream resources. When the number of required streams exceeds the hardware limit, the model size cannot continue to scale up, thus becoming a bottleneck in the development of large models.
By extracting communication subgraphs by categorizing communication operators and reducing the number of communication operators in graph compilation, on the one hand, communication time consumption and model compilation time consumption can be reduced; on the other hand, the stream occupancy is reduced, making the model further scalable. For example, micro size can be further increased in pipeline parallel mode.
This feature currently only supports Ascend backend graph mode.
Related environment variables:
MS_COMM_COMPILER_OPT: Users can turn on the feature switch and configure the maximum number of multiplexing communication operators through the environment variable MS_COMM_COMPILER_OPT. MS_COMM_COMPILER_OPT can be set to -1 or a positive integer to turn on the feature, and will not be turned on if the environment variable is not set or is set to any other value. Please refer to the following table for details. When this feature is enabled, the INFO log will print “MAX_COMM_OP_REUSE_NUM: xxx”, which indicates the upper limit of multiplexing communication operators used by the framework.
MS_COMM_COMPILER_OPT |
Descriptions |
|---|---|
-1 |
Turn on this feature and use default communication operator reuse limit of the framework: 1000 |
Positive Integer |
Turn on this feature, and use a positive integer set by the user as the upper limit of communication operator reuse |
Not setting/Others |
Turn off this feature |
Since the root graph will generate a large number of labels by calling the communication subgraph multiple times, when the MS_COMM_COMPILER_OPT value set by the user is too large and exceeds the limit of the number of labels of the hardware, it will trigger the framework error. Users can search the following logs to reduce the value of MS_COMM_COMPILER_OPT appropriately:
Label list size: # Indicates the total number of labels used for graph compilation
Reuse comm op reused_comm_sub_graphs_ size: # denotes the number of communication operators that are eventually multiplexed
Start reuse # The number of logs indicates the number of communication subgraphs generated
Basic Principle
With this feature turned on, the MindSpore framework will perform the following steps:
Check if it is a graph mode and if this feature is turned on, otherwise it does not enter the optimization step of this feature.
Identify all reusable communication operators in the computational graph.
Group communication operators of the same type, the same shape, the same dtype and the same group in the same group. If the number of communication operators in a group exceeds the upper limit of communication operators that can be carried on a stream, the communication operator subgraph is created according to the operator type, shape, and dtype of the group.
Replace the communication operator in the original computational graph with the Call node and call the corresponding communication subgraph.
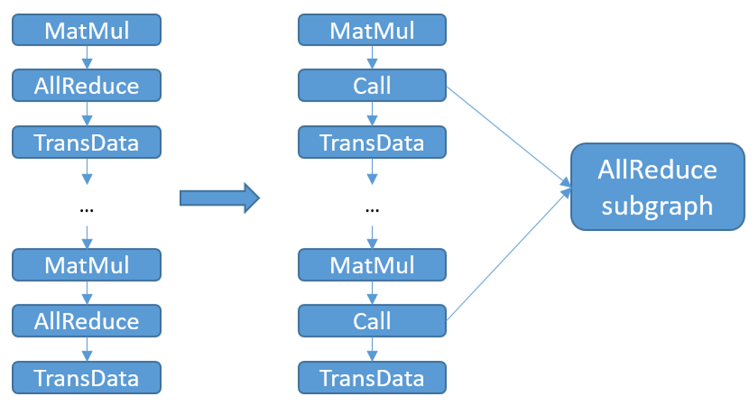
Since the communication operator in the communication subgraph occupies only one communication stream, the number of communication streams actually used will drop to 1 after replacing the communication operator in the original computational graph with a call to the communication subgraph. For example, if there are 30 AllReduce operators that can be grouped in the same group, and each communication stream can carry up to 3 communication operators, 10 communication streams are required before this feature can be turned on. With this feature turned on, the AllReduce subgraph occupies only 1 communication stream, thus saving 9 communication streams. Also, the time consumed by graph compilation for communication will be reduced due to the reduced number of communication operators processed in the compilation phase.
Operation Practice
The following is an illustration of the communication subgraph extraction and multiplexing operation using the Ascend 8-card as an example:
Example Code Description
Download the complete example code: comm_subgraph
The directory structure is as follows:
└─ sample_code
├─ comm_subgraph
├── train.py
└── run.sh
...
train.py is the script that defines the network structure and the training process. run.sh is the execution script.
Configuring a Distributed Environment
Specify the run mode, run device, run card number via the context interface, and the parallel mode as semi-parallel mode. The sample uses optimizer parallel and initializes HCCL or NCCL communication via init. The device_target is automatically specified as the backend hardware device corresponding to the MindSpore package.
import mindspore as ms
from mindspore.communication import init
ms.set_context(mode=ms.GRAPH_MODE)
ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.SEMI_AUTO_PARALLEL, enable_parallel_optimizer=True)
init()
ms.set_seed(1)
Dataset Loading, Defining the Network, and Training the Network
The dataset is loaded, the network is defined and the network is trained in the same way as the single card model, with the following code:
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.layer1 = nn.Dense(28*28, 512)
self.layer2 = nn.Dense(512, 512)
self.layer3 = nn.Dense(512, 10)
self.relu = nn.ReLU()
def construct(self, x):
x = self.flatten(x)
x = self.layer1(x)
x = self.relu(x)
x = self.layer2(x)
x = self.relu(x)
logits = self.layer3(x)
return logits
net = Network()
for item in net.trainable_params():
print(f"The parameter {item.name}'s fusion id is {item.comm_fusion}")
def create_dataset(batch_size):
dataset_path = os.getenv("DATA_PATH")
dataset = ds.MnistDataset(dataset_path)
image_transforms = [
ds.vision.Rescale(1.0 / 255.0, 0),
ds.vision.Normalize(mean=(0.1307,), std=(0.3081,)),
ds.vision.HWC2CHW()
]
label_transform = ds.transforms.TypeCast(ms.int32)
dataset = dataset.map(image_transforms, 'image')
dataset = dataset.map(label_transform, 'label')
dataset = dataset.batch(batch_size)
return dataset
data_set = create_dataset(32)
optimizer = nn.SGD(net.trainable_params(), 1e-2)
loss_fn = nn.CrossEntropyLoss()
def forward_fn(data, target):
logits = net(data)
loss = loss_fn(logits, target)
return loss, logits
grad_fn = ms.value_and_grad(forward_fn, None, net.trainable_params(), has_aux=True)
@ms.jit
def train_step(inputs, targets):
(loss_value, _), grads = grad_fn(inputs, targets)
optimizer(grads)
return loss_value
for epoch in range(2):
i = 0
for image, label in data_set:
loss_output = train_step(image, label)
if i % 10 == 0:
print("epoch: %s, step: %s, loss is %s" % (epoch, i, loss_output))
i += 1
Running Stand-alone 8-card Script
Next, the corresponding script is called by the command. Take the mpirun startup method, the 8-card distributed inference script as an example, and perform the distributed inference:
bash run.sh
After the training, the log results are saved in log_output/1/rank.*/stdout, as below:
...
The parameter layer1.weight's fusion id is 1
The parameter layer1.bias's fusion id is 1
The parameter layer2.weight's fusion id is 1
The parameter layer2.bias's fusion id is 1
The parameter layer3.weight's fusion id is 1
The parameter layer3.bias's fusion id is 1
...
epoch: 0, step: 0, loss is 2.3190787
epoch: 0, step: 10, loss is 1.9131156
epoch: 0, step: 20, loss is 1.546958
epoch: 0, step: 30, loss is 0.87771374
epoch: 0, step: 40, loss is 0.8577032
epoch: 0, step: 50, loss is 0.65985847
epoch: 0, step: 60, loss is 0.7244837
...
The first part indicates the fusion index of each parameter, and the parameters with the same index will be fused when communicating. The second part is the result of Loss.
If INFO logging is turned on via export GLOG_v=1, the following is printed:
...
MAX_COMM_OP_REUSE_NUM: 3
...
It denotes an upper bound of 3 on the number of communication operators that can be reused.