同步训练和验证模型
Ascend GPU CPU 初级 中级 高级 模型导出 模型训练
![]()
![]()
概述
在面对复杂网络时,往往需要进行几十甚至几百次的epoch训练。在训练之前,很难掌握在训练到第几个epoch时,模型的精度能达到满足要求的程度,所以经常会采用一边训练的同时,在相隔固定epoch的位置对模型进行精度验证,并保存相应的模型,等训练完毕后,通过查看对应模型精度的变化就能迅速地挑选出相对最优的模型,本文将采用这种方法,以LeNet网络为样本,进行示例。
流程如下:
定义回调函数EvalCallBack,实现同步进行训练和验证。
定义训练网络并执行。
将不同epoch下的模型精度绘制出折线图并挑选最优模型。
完整示例请参考notebook。
定义回调函数EvalCallBack
实现思想:每隔n个epoch验证一次模型精度,由于在自定义函数中实现,如需了解详细用法,请参考API说明;
核心实现:回调函数的epoch_end内设置验证点,如下:
cur_epoch % eval_per_epoch == 0:即每eval_per_epoch个epoch结束时,验证一次模型精度。
cur_epoch:当前训练过程的epoch数值。eval_per_epoch:用户自定义数值,即验证频次。
其他参数解释:
model:即是MindSpore中的Model函数。eval_dataset:验证数据集。epoch_per_eval:记录验证模型的精度和相应的epoch数,其数据形式为{"epoch": [], "acc": []}。
from mindspore.train.callback import Callback
class EvalCallBack(Callback):
def __init__(self, model, eval_dataset, eval_per_epoch, epoch_per_eval):
self.model = model
self.eval_dataset = eval_dataset
self.eval_per_epoch = eval_per_epoch
self.epoch_per_eval = epoch_per_eval
def epoch_end(self, run_context):
cb_param = run_context.original_args()
cur_epoch = cb_param.cur_epoch_num
if cur_epoch % self.eval_per_epoch == 0:
acc = self.model.eval(self.eval_dataset, dataset_sink_mode=True)
self.epoch_per_eval["epoch"].append(cur_epoch)
self.epoch_per_eval["acc"].append(acc["Accuracy"])
print(acc)
定义训练网络并执行
在保存模型的参数CheckpointConfig中,需计算好单个epoch中的step数,再根据需要进行验证模型精度的频次对应,本次示例为1875个step/epoch,按照每两个epoch验证一次的思想,这里设置save_checkpoint_steps=eval_per_epoch*1875,其中变量eval_per_epoch等于2。
参数解释:
config_ck:定义保存模型信息。save_checkpoint_steps:每多少个step保存一次模型。keep_checkpoint_max:设置保存模型数量的上限。
ckpoint_cb:定义模型保存的名称及路径信息。model:定义模型。model.train:模型训练函数。epoch_per_eval:定义收集epoch数和对应模型精度信息的字典。
from mindspore.train.callback import ModelCheckpoint, CheckpointConfig, LossMonitor
from mindspore.train import Model
from mindspore import context
from mindspore.nn.metrics import Accuracy
if __name__ == "__main__":
context.set_context(mode=context.GRAPH_MODE, device_target="GPU")
ckpt_save_dir = "./lenet_ckpt"
eval_per_epoch = 2
... ...
# need to calculate how many steps are in each epoch,in this example, 1875 steps per epoch
config_ck = CheckpointConfig(save_checkpoint_steps=eval_per_epoch*1875, keep_checkpoint_max=15)
ckpoint_cb = ModelCheckpoint(prefix="checkpoint_lenet",directory=ckpt_save_dir, config=config_ck)
model = Model(network, net_loss, net_opt, metrics={"Accuracy": Accuracy()})
epoch_per_eval = {"epoch": [], "acc": []}
eval_cb = EvalCallBack(model, eval_data, eval_per_epoch, epoch_per_eval)
model.train(epoch_size, train_data, callbacks=[ckpoint_cb, LossMonitor(375), eval_cb],
dataset_sink_mode=True)
输出结果:
epoch: 1 step: 375, loss is 2.298612
epoch: 1 step: 750, loss is 2.075152
epoch: 1 step: 1125, loss is 0.39205977
epoch: 1 step: 1500, loss is 0.12368304
epoch: 1 step: 1875, loss is 0.20988345
epoch: 2 step: 375, loss is 0.20582482
epoch: 2 step: 750, loss is 0.029070046
epoch: 2 step: 1125, loss is 0.041760832
epoch: 2 step: 1500, loss is 0.067035824
epoch: 2 step: 1875, loss is 0.0050643035
{'Accuracy': 0.9763621794871795}
... ...
epoch: 9 step: 375, loss is 0.021227183
epoch: 9 step: 750, loss is 0.005586236
epoch: 9 step: 1125, loss is 0.029125651
epoch: 9 step: 1500, loss is 0.00045874066
epoch: 9 step: 1875, loss is 0.023556218
epoch: 10 step: 375, loss is 0.0005807788
epoch: 10 step: 750, loss is 0.02574059
epoch: 10 step: 1125, loss is 0.108463734
epoch: 10 step: 1500, loss is 0.01950589
epoch: 10 step: 1875, loss is 0.10563098
{'Accuracy': 0.979667467948718}
在同一目录找到lenet_ckpt文件夹,文件夹中保存了5个模型,和一个计算图相关数据,其结构如下:
lenet_ckpt
├── checkpoint_lenet-10_1875.ckpt
├── checkpoint_lenet-2_1875.ckpt
├── checkpoint_lenet-4_1875.ckpt
├── checkpoint_lenet-6_1875.ckpt
├── checkpoint_lenet-8_1875.ckpt
└── checkpoint_lenet-graph.meta
定义函数绘制不同epoch下模型的精度
定义绘图函数eval_show,将epoch_per_eval载入到eval_show中,绘制出不同epoch下模型的验证精度折线图。
import matplotlib.pyplot as plt
def eval_show(epoch_per_eval):
plt.xlabel("epoch number")
plt.ylabel("Model accuracy")
plt.title("Model accuracy variation chart")
plt.plot(epoch_per_eval["epoch"], epoch_per_eval["acc"], "red")
plt.show()
eval_show(epoch_per_eval)
输出结果:
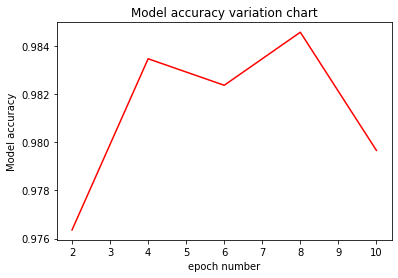
从上图可以一目了然地挑选出需要的最优模型。
总结
本次使用MNIST数据集通过卷积神经网络LeNet5进行训练,着重介绍了在进行模型训练的同时进行模型的验证,保存对应epoch的模型,并从中挑选出最优模型的方法。