Ascend Performance Tuning
![]()
Overview
This tutorial introduces how to use MindSpore Profiler for performance tuning on Ascend AI processors. MindSpore Profiler can provide operators execution time analysis, memory usage analysis, AI Core metrics analysis, Timeline display, etc., to help users analyze performance bottlenecks and optimize training efficiency.
Operation Process
Prepare the training script;
Call the performance debugging interface in the training script, such as mindspore.Profiler and mindspore.profiler.DynamicProfilerMonitor interfaces;
Run the training script;
View the performance data through MindStudio Insight.
Usage
There are three ways to collect training performance data, users can use the Profiler enabling method according to different scenarios. The following will introduce the usage of different scenarios.
Method 1: mindspore.Profiler Interface Enabling
Add the MindSpore Profiler related interfaces in the training script, see MindSpore Profiler parameter details for details.
Graph mode collection example:
In Graph mode, users can enable Profiler through Callback.
import mindspore as ms
from mindspore import Profiler
class StopAtStep(ms.Callback):
def __init__(self, start_step, stop_step):
super(StopAtStep, self).__init__()
self.start_step = start_step
self.stop_step = stop_step
self.profiler = Profiler(start_profile=False, output_path='./profiler_data')
def on_train_step_begin(self, run_context):
cb_params = run_context.original_args()
step_num = cb_params.cur_step_num
if step_num == self.start_step:
self.profiler.start()
def on_train_step_end(self, run_context):
cb_params = run_context.original_args()
step_num = cb_params.cur_step_num
if step_num == self.stop_step:
self.profiler.stop()
self.profiler.analyse()
For the complete case, refer to graph mode collection complete code example
PyNative mode collection example:
In PyNative mode, users can enable Profiler through setting schedule and on_trace_ready parameters.
For example, if you want to collect the performance data of the first two steps, you can use the following configuration to collect.
Sample as follows:
from mindspore import Profiler
from mindspore.profiler import schedule, tensor_board_trace_handler
STEP_NUM = 15
# Define the training model network
net = Net()
with Profiler(schedule=schedule(wait=0, warmup=0, active=2, repeat=1, skip_first=0),
on_trace_ready=tensor_board_trace_handler) as prof:
for _ in range(STEP_NUM):
train(net)
# Call step to collect
prof.step()
After enabling, the Step ID column information is included in the kernel_details.csv file, and the Step ID is 0,1, indicating that the data collected is the 0th and 1st step data.
For the complete case, refer to PyNative mode collection complete code example
Method 2: Dynamic Profiler Enabling
Users can use the mindspore.profiler.DynamicProfilerMonitor interface to enable Profiler without interrupting the training process, modify the configuration file, and complete the collection task under the new configuration. This interface requires a JSON configuration file, if not configured, a JSON file with a default configuration will be generated. This interface requires a JSON configuration file, if not configured, a JSON file with a default configuration will be generated.
JSON configuration example as follows:
{
"start_step": 2,
"stop_step": 5,
"aicore_metrics": -1,
"profiler_level": 0,
"activities": 0,
"analyse_mode": -1,
"parallel_strategy": false,
"with_stack": false,
"data_simplification": true
}
Users need to configure the above JSON configuration file before instantiating DynamicProfilerMonitor, see DynamicProfilerMonitor parameter details for details, and save the configuration file to cfg_path;
Call the step interface of DynamicProfilerMonitor after the model training to collect data;
If users want to change the collection and analysis tasks during training, they can modify the JSON configuration file, such as changing the start_step in the above JSON configuration to 8, stop_step to 10, save it, and DynamicProfilerMonitor will automatically identify that the configuration file has changed to the new collection and analysis tasks.
Sample as follows:
from mindspore.profiler import DynamicProfilerMonitor
# cfg_path includes the path of the above JSON configuration file, output_path is the output path
dp = DynamicProfilerMonitor(cfg_path="./cfg_path", output_path="./output_path")
STEP_NUM = 15
# Define the training model network
net = Net()
for _ in range(STEP_NUM):
train(net)
# Call step to collect
dp.step()
At this point, the results include two folders: rank0_start2_stop5 and rank0_start8_stop10, representing the collection of steps 2-5 and 8-10 respectively.
For the complete case, refer to dynamic profiler enabling method case.
Method 3: Environment Variable Enabling
Users can use the environment variable enabling method to enable Profiler most simply, this method only needs to configure the parameters to the environment variables, and the performance data will be automatically collected during the model training, but this method does not support the schedule parameter collection data, other parameters can be used. See environment variable enabling method parameter details for details.
Environment variable enabling method related configuration items, sample as follows:
export MS_PROFILER_OPTIONS='
{"start": true,
"output_path": "/XXX",
"activities": ["CPU", "NPU"],
"with_stack": true,
"aicore_metrics": "AicoreNone",
"l2_cache": false,
"profiler_level": "Level0"}'
After loading the environment variable, start the training script directly to complete the collection. Note that in this configuration, start must be true to achieve the enabling effect, otherwise the enabling will not take effect.
Performance Data
Users can collect, parse, and analyze performance data through MindSpore Profiler, including raw performance data from the framework side, CANN side, and device side, as well as parsed performance data.
When using MindSpore to train a model, in order to analyze performance bottlenecks and optimize training efficiency, we need to collect and analyze performance data. MindSpore Profiler provides complete performance data collection and analysis capabilities, this article will detail the storage structure and content meaning of the collected performance data.
After collecting performance data, the original data will be stored according to the following directory structure:
The following data files are not required to be opened and viewed by users. Users can refer to the MindStudio Insight user guide for viewing and analyzing performance data.
The following is the full set of result files, the actual file number and content depend on the user's parameter configuration and the actual training scenario, if the user does not configure the related parameters or does not involve the related scenarios in the training, the corresponding data files will not be generated.
└── localhost.localdomain_*_ascend_ms // Analysis result directory, named format: {worker_name}_{timestamp}_ascend_ms, by default {worker_name} is {hostname}_{pid}
├── profiler_info.json // For multi-card or cluster scenarios, the naming rule is profiler_info_{Rank_ID}.json, used to record Profiler related metadata
├── profiler_metadata.json
├── ASCEND_PROFILER_OUTPUT // MindSpore Profiler interface collects performance data
│ ├── api_statistic.csv // Generated when profiler_level=ProfilerLevel.Level1 or profiler_level=ProfilerLevel.Level2
│ ├── communication.json // Provides visualization data for performance analysis in multi-card or cluster scenarios, generated when profiler_level=ProfilerLevel.Level1 or profiler_level=ProfilerLevel.Level2
│ ├── communication_matrix.json // Communication small operator basic information file, generated when profiler_level=ProfilerLevel.Level1 or profiler_level=ProfilerLevel.Level2
│ ├── dataset.csv // Generated when activities contains ProfilerActivity.CPU
│ ├── data_preprocess.csv // Generated when profiler_level=ProfilerLevel.Level2
│ ├── kernel_details.csv // Generated when activities contains ProfilerActivity.NPU
│ ├── l2_cache.csv // Generated when l2_cache=True
│ ├── memory_record.csv // Generated when profile_memory=True
│ ├── minddata_pipeline_raw_*.csv // Generated when data_process=True and call mindspore.dataset
│ ├── minddata_pipeline_summary_*.csv // Generated when data_process=True and call mindspore.dataset
│ ├── minddata_pipeline_summary_*.json // Generated when data_process=True and call mindspore.dataset
│ ├── npu_module_mem.csv // Generated when profile_memory=True
│ ├── operator_memory.csv // Generated when profile_memory=True
│ ├── op_statistic.csv // AI Core and AI CPU operator call count and time data
│ ├── step_trace_time.csv // Iteration calculation and communication time statistics
│ └── trace_view.json
├── FRAMEWORK // Framework side performance raw data, no need to pay attention to it, delete this directory when data_simplification=True
└── PROF_000001_20230628101435646_FKFLNPEPPRRCFCBA // CANN layer performance data, named format: PROF_{number}_{timestamp}_{string}, delete other data when data_simplification=True, only retain the original performance data in this directory
├── analyze // Generated when profiler_level=ProfilerLevel.Level1 or profiler_level=ProfilerLevel.Level2
├── device_*
├── host
├── mindstudio_profiler_log
└── mindstudio_profiler_output
MindSpore Profiler interface will associate and integrate the framework side data and CANN Profling data to form trace, kernel, and memory performance data files. The detailed description of each file is as follows.
FRAMEWORK is the performance raw data of the framework side, no need to pay attention to it; PROF directory is the performance data collected by CANN Profling, mainly saved in the mindstudio_profiler_output directory.
communication.json
The information of this performance data file is as follows:
hcom_allGather_*@group
Communication Time Info
Start Timestamp(μs)
Elapse Time(ms)
Transit Time(ms)
Wait Time(ms)
Synchronization Time(ms)
Idel Time(ms)
Wait Time Ratio
Synchronization Time Ratio
Communication Bandwidth Info
RDMA
Transit Size(MB)
Transit Time(ms)
Bandwidth(GB/s)
Large Packet Ratio
Size Distribution
"Package Size(MB)": [count, dur]
HCCS
Transit Size(MB)
Transit Time(ms)
Bandwidth(GB/s)
Large Packet Ratio
Size Distribution
"Package Size(MB)": [count, dur]
PCIE
Transit Size(MB)
Transit Time(ms)
Bandwidth(GB/s)
Large Packet Ratio
Size Distribution
"Package Size(MB)": [count, dur]
SDMA
Transit Size(MB)
Transit Time(ms)
Bandwidth(GB/s)
Large Packet Ratio
Size Distribution
"Package Size(MB)": [count, dur]
SIO
Transit Size(MB)
Transit Time(ms)
Bandwidth(GB/s)
Large Packet Ratio
Size Distribution
"Package Size(MB)": [count, dur]
communication_matrix.json
The information of this performance data file is as follows:
allgather-top1@*
src_rank-dst_rank
Transport Type
Transit Size(MB)
Transit Time(ms)
Bandwidth(GB/s)
op_name
dataset.csv
dataset.csv file records the information of the dataset operator.
Field Name |
Field Explanation |
|---|---|
Operation |
Corresponding dataset operation name |
Stage |
Operation stage |
Occurrences |
Operation occurrence times |
Avg. time(us) |
Operation average time (microseconds) |
Custom Info |
Custom information |
kernel_details.csv
kernel_details.csv file is controlled by the ProfilerActivity.NPU switch, the file contains the information of all operators executed on NPU. If the user calls schedule in the front end to collect step data, the Step Id field will be added.
The difference from the data collected by the Ascend PyTorch Profiler interface is that when the with_stack switch is turned on, MindSpore Profiler will concatenate the stack information to the Name field.
minddata_pipeline_raw_*.csv
minddata_pipeline_raw_*.csv records the performance metrics of the dataset operation.
Field Name |
Field Explanation |
|---|---|
op_id |
Dataset operation ID |
op_type |
Operation type |
num_workers |
Number of operation workers |
output_queue_size |
Output queue size |
output_queue_average_size |
Output queue average size |
output_queue_length |
Output queue length |
output_queue_usage_rate |
Output queue usage rate |
sample_interval |
Sampling interval |
parent_id |
Parent operation ID |
children_id |
Child operation ID |
minddata_pipeline_summary_*.csv
minddata_pipeline_summary_*.csv and minddata_pipeline_summary_*.json have the same content, but different file formats. They record more detailed performance metrics of dataset operations and provide optimization suggestions based on these metrics.
Field Name |
Field Explanation |
|---|---|
op_ids |
Dataset operation ID |
op_names |
Operation name |
pipeline_ops |
Operation pipeline |
num_workers |
Number of operation workers |
queue_queue_size |
Output queue size |
queue_utilization_pct |
Output queue usage rate |
queue_empty_freq_pct |
Output queue idle frequency |
children_ids |
Child operation ID |
parent_id |
Parent operation ID |
avg_cpu_pct |
Average CPU usage rate |
per_pipeline_time |
Time for each pipeline execution |
per_push_queue_time |
Time for each push queue |
per_batch_time |
Time for each data batch execution |
avg_cpu_pct_per_worker |
Average CPU usage rate per thread |
cpu_analysis_details |
CPU analysis details |
queue_analysis_details |
Queue analysis details |
bottleneck_warning |
Performance bottleneck warning |
bottleneck_suggestion |
Performance bottleneck suggestion |
trace_view.json
trace_view.json is recommended to be opened using MindStudio Insight tool or chrome://tracing/. MindSpore Profiler does not support the record_shapes and GC functions.
Other Performance Data
The specific field and meaning of other performance data files can be referred to Ascend official documentation.
Performance Tuning Case
In the process of large model training, due to some unpredictable introduction, the model has some performance deterioration problems, such as slow operator calculation time, communication speed and slow card. The root cause of performance degradation needs to be identified and the problem addressed.
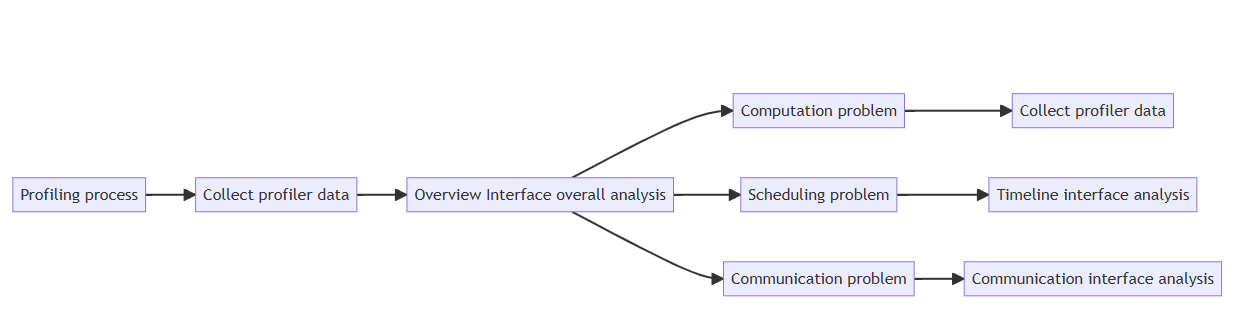
The most important thing in performance tuning is to apply the right medicine to the problem, delimit the problem first, and then perform targeted tuning to the problem. The first to use MindStudio Insight visualization tools and bound performance issues. The results of delimiting are usually divided into three aspects: computation, scheduling and communication. Finally, users can tune performance based on expert advice from MindStudio Insight. Re-run the training after each tuning, collect performance data, and use the MindStudio Insight tool to see if the tuning method produced results. Repeat this process until the performance issue is resolved.
MindStudio Insight provides a wealth of tuning and analysis methods, visualizing the real software and hardware operation data, analyzing performance data in multiple dimensions, locating performance bottlenecks, and supporting visual cluster performance analysis of the scale of heckcal, kcal and above. The user imports the performance data collected in the previous step into MindStudio Insight and uses the visualization capabilities to analyze the performance data according to the following process.
1. Overview of the data
You can learn about each module through the overview interface.
First, select the 'Import Data' button in the MindStudio Insight interface to import collected profiler data, and then import multi-card performance data.
Next, the overview interface can display the calculation, communication, idle time ratio of each card under the selected communication domain, and provide expert advice.
The meanings of data indicators related to each legend are as follows:
legend |
Meaning |
|---|---|
Total compute time |
Total kernel time on the ascending device |
pure computing time |
pure computing time = Total computing time - Communication time (overwritten) |
Communication duration (overwritten) |
The duration of the communication that is overwritten, that is, the duration of the computation and communication at the same time |
communication duration (not covered) |
The communication duration that is not covered, that is, the pure communication duration |
Idle time |
Duration of no calculation or communication |
2. Definition and Analysis of Problems
Different indicator phenomena can delimit different performance problems:
(1) Calculation problem: usually manifested as a large difference between the maximum value and the minimum value of the total calculation time in the communication domain. If the calculation time of some computing cards is obviously beyond the normal range, it is likely to mean that the card has undertaken too heavy computing tasks, such as the amount of data to be processed is too large, or the complexity of the model calculation is too high, or the performance of the card itself is limited.
(2) Scheduling problem: Usually manifested as a large difference between the maximum and minimum of the proportion of idle time in the communication domain. If the idle time of the compute cards is too long, it indicates that the task distribution may be unbalanced, or there is a situation in which the cards are waiting for data from each other, which also adversely affects the performance of the cluster.
(3) Communication problems: If the communication time (not covered) is too long, it indicates that there is a problem with the coordination between calculation and communication, which may correspond to a variety of situations. Perhaps the communication protocol is not optimized enough, or the network bandwidth is unstable, resulting in communication and calculation can not be well matched.
2.1 Computation Problems
When the data indicator phenomenon indicates a computation problem, the operator data of the abnormal card can be directly viewed and compared with the normal card. In this case, you can use the performance comparison function of MindStudio Insight to set the two cards to the comparison mode and view the result on the operator interface.
2.2 Scheduling Problems
When the data indicator phenomenon indicates a scheduling problem, it is necessary to go to the timeline interface to compare the abnormal card with the normal card to further locate the operator that has the problem.
On the timeline screen, select the connection type of HostToDevice. HostToDevice shows the downward execution relationship of CANN layer operators to AscendHardware operators and the downward execution relationship of CANN layer operators to HCCL communication operators for locating scheduling problems.
The connection of HostToDevice usually has two forms, inclined and vertical. The following figure shows a case of scheduling problems. If the connection of HostToDevice is inclined as shown on the left, it indicates that the scheduling task is arranged properly during this time period, and the ascending device performs calculation and communication tasks at full load. If the HostToDevice cable is vertical as shown on the right, it indicates that the ascending device quickly completes the tasks sent by the CPU and performs calculation and communication tasks under full load. This generally indicates a scheduling problem.
2.3 Communication Problems
When the data indicator symptom indicates a communication problem, you need to enter the communication interface for further analysis. The communication interface is used to display the link performance of the whole network and the communication performance of all nodes in the cluster. By analyzing the overlap time of cluster communication and calculation, the slow host or slow node in the cluster training can be found out. Typically, we analyze performance issues in terms of key metrics communication matrix, communication duration.
Communication matrix
When analyzing, you can first check the transmission size, analyze whether there is a difference in the transmission volume of each card in this collection communication, and whether there is an uneven distribution. Second, look at the transmission time, if the transmission time of a card is very short, it is most likely to be dealing with other things, resulting in a long wait for the downstream card. Finally, you can view the bandwidth situation, if the bandwidth data difference between different cards is too large or the bandwidth value is abnormal, it means that there is an abnormal card in the communication domain.
Communication duration
Communication time refers to the time taken for a communication between computing cards. There are many factors that lead to excessive communication time, such as incorrect configuration of communication protocols, excessive data transmission, and so on. Only by finding these links that take too long to communicate and properly solving the problems, can data be transmitted between computing cards more smoothly, thereby improving the overall performance of the cluster. After the user selects a specific communication domain, the user can view the time summary of each calculation card in the communication domain in the communication duration interface, as well as the timing diagram and communication duration distribution diagram of each communication operator, so as to quickly obtain the relative position relationship and detailed communication data of the communication operator.
Common Tool Issues and Solutions
Common Issues with step Collection Performance Data
schedule Configuration Error Problem
schedule configuration related parameters have 5 parameters: wait, warmup, active, repeat, skip_first. Each parameter must be greater than or equal to 0; active must be greater than or equal to 1, otherwise a warning will be thrown and set to the default value 1; if repeat is set to 0, it means that the repeat parameter does not take effect, Profiler will determine the number of loops according to the number of model training times.
schedule and step Configuration Mismatch Problem
Normally, the schedule configuration should be less than the number of model training times, that is, repeat*(wait+warmup+active)+skip_first should be less than the number of model training times. If the schedule configuration is greater than the number of model training times, Profiler will throw an exception warning, but this will not interrupt the model training, but there may be incomplete data collection and analysis.