数据处理性能优化
![]()
![]()
![]()
数据是深度学习中最重要的一环。数据的质量决定了最终结果的上限,模型的优劣只是不断逼近这个上限。因此,高质量的数据输入会在深度神经网络中发挥积极作用。数据在处理和增强过程中,如同流水般经过pipeline管道,源源不断地流向训练系统,如图所示:

MindSpore Dataset为用户提供了数据加载以及数据增强的功能。在数据pipeline过程中每一步,如果都能够进行合理的运用,将大幅提升数据处理性能。
本文以CIFAR-10数据集为例,展示如何在数据加载、处理和增强过程中进行性能的优化。
此外,操作系统的存储、架构和计算资源等在一定程度上也会影响数据处理的性能。
下载数据集
运行以下命令来获取数据集:
下载CIFAR-10二进制格式数据集,并将其解压到./datasets/目录下,数据加载时使用该数据集。
[1]:
from download import download
import os
import shutil
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/cifar-10-binary.tar.gz"
path = download(url, "./datasets", kind="tar.gz", replace=True) # 下载CIFAR-10数据集
test_path = "./datasets/cifar-10-batches-bin/test"
train_path = "./datasets/cifar-10-batches-bin/train"
os.makedirs(test_path, exist_ok=True)
os.makedirs(train_path, exist_ok=True)
if not os.path.exists(os.path.join(test_path, "test_batch.bin")):
shutil.move("./datasets/cifar-10-batches-bin/test_batch.bin", test_path)
[shutil.move("./datasets/cifar-10-batches-bin/"+i, train_path) for i in os.listdir("./datasets/cifar-10-batches-bin/") if os.path.isfile("./datasets/cifar-10-batches-bin/"+i) and not i.endswith(".html") and not os.path.exists(os.path.join(train_path, i))]
解压后的数据集文件的目录结构如下:
./datasets/cifar-10-batches-bin
├── readme.html
├── test
│ └── test_batch.bin
└── train
├── batches.meta.txt
├── data_batch_1.bin
├── data_batch_2.bin
├── data_batch_3.bin
├── data_batch_4.bin
└── data_batch_5.bin
数据加载性能优化
MindSpore支持加载计算机视觉、自然语言处理等领域的常用数据集,也支持加载特定格式的数据集以及用户自定义的数据集。不同数据集加载接口的底层实现方式不同,性能也存在着差异,如下所示:
常用数据集 |
标准格式(MindRecord等) |
用户自定义 |
|
|---|---|---|---|
底层实现 |
C++ |
C++ |
Python |
性能 |
高 |
高 |
中 |
可参考下图,选择适合当前场景的数据集加载接口:
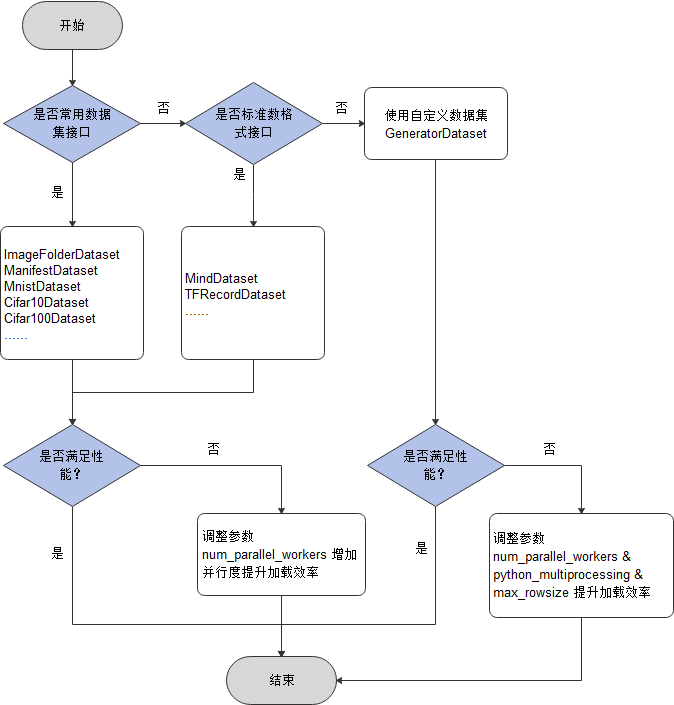
数据加载性能优化建议如下:
对于已经提供加载接口的常用数据集,优先使用MindSpore提供的数据集加载接口,可以获得较好的加载性能。具体内容请参考框架提供的数据集加载接口。如果性能仍无法满足需求,可通过增大数据集接口参数
num_parallel_workers(默认值:8)的值来提升性能。对于不支持的数据集格式,建议先将数据集转换为MindRecord数据格式,再使用
MindDataset类进行加载(详细使用方法参考API)。具体内容请参考将数据集转换为MindSpore数据格式。如果性能仍无法满足需求,可通过增大num_parallel_workers(默认值:8)的值来提升性能。对于不支持的数据集格式,在算法快速验证场景下,优选使用用户自定义的
GeneratorDataset类实现(详细使用方法参考API)。如果性能仍无法满足需求,则可采取多进程/多线程并发方案,即:增大数据集接口参数
num_parallel_workers(默认值:1)的值,以提升并发度;将数据集接口的参数
python_multiprocessing设置为True(默认值)或False,分别启动多进程或多线程模式。多进程模式适用于CPU计算密集型任务,多线程适用于IO密集型任务;注意:如果配置
python_multiprocessing=True(默认值:True)和num_parallel_workers>1(默认值:1)表示启动了多进程方式进行数据load加速,此时随着数据集迭代,子进程的内存占用会逐渐增加,主要是因为自定义数据集的子进程以 Copy-On-Write 的方式获取主进程中的成员变量。举例:如果自定义数据集__init__函数中包含大量成员变量数据(例如:在数据集构建时加载了一个非常大的文件名列表)并且使用了多进程方式,那这可能会导致产生OOM的问题(总内存的预估使用量是:(子进程数量 + 1) * 父进程的内存大小)。最简单的解决方法是成员变量用非引用数据类型 (如:Pandas、Numpy或PyArrow对象)替换Python对象(如:list / dict / int / float / string等),或者加载更少的元数据以减小成员变量,或者配置python_multiprocessing=False使用多线程方式。如果出现
Using shared memory queue, but rowsize is larger than allocated memory ...日志提示,可按日志提示增大max_rowsize参数,或直接设为None,以提升进程间数据传递效率。
基于以上的数据加载性能优化建议,本次体验分别使用框架提供的数据集加载操作Cifar10Dataset类(详细使用方法参考API)、数据转换后使用MindDataset类、使用GeneratorDataset类进行数据加载,代码演示如下:
使用数据集加载操作
Cifar10Dataset类加载CIFAR-10数据集,这里使用的是CIFAR-10二进制格式的数据集,加载数据时采取多线程优化方案,开启了4个线程并发完成任务,最后对数据创建了字典迭代器,并通过迭代器读取了一条数据记录。
[2]:
import mindspore.dataset as ds
cifar10_path = "./datasets/cifar-10-batches-bin/train"
# create Cifar10Dataset for reading data
cifar10_dataset = ds.Cifar10Dataset(cifar10_path, num_parallel_workers=4)
# create a dictionary iterator and read a data record through the iterator
print(next(cifar10_dataset.create_dict_iterator()))
{'image': Tensor(shape=[32, 32, 3], dtype=UInt8, value=
[[[181, 185, 194],
[184, 187, 196],
[189, 192, 201],
...
[178, 181, 191],
[171, 174, 183],
[166, 170, 179]],
[[182, 185, 194],
[184, 187, 196],
[189, 192, 201],
...
[180, 183, 192],
[173, 176, 185],
[167, 170, 179]],
[[185, 188, 197],
[187, 190, 199],
[193, 196, 205],
...
[182, 185, 194],
[176, 179, 188],
[170, 173, 182]],
...
[[176, 174, 185],
[172, 171, 181],
[174, 172, 183],
...
[168, 171, 180],
[164, 167, 176],
[160, 163, 172]],
[[172, 170, 181],
[171, 169, 180],
[173, 171, 182],
...
[164, 167, 176],
[160, 163, 172],
[156, 159, 168]],
[[171, 169, 180],
[173, 171, 182],
[177, 175, 186],
...
[162, 165, 174],
[158, 161, 170],
[152, 155, 164]]]), 'label': Tensor(shape=[], dtype=UInt32, value= 6)}
使用
Cifar10ToMR这个类将CIFAR-10数据集转换为MindSpore数据格式,这里使用的是CIFAR-10 python文件格式的数据集,然后使用MindDataset类加载MindSpore数据格式数据集,加载数据采取多线程优化方案,开启了4个线程并发完成任务,最后对数据创建了字典迭代器,并通过迭代器读取了一条数据记录。
[3]:
from mindspore.mindrecord import Cifar10ToMR
trans_path = "./transform/"
if not os.path.exists(trans_path):
os.mkdir(trans_path)
os.system("rm -f {}cifar10*".format(trans_path))
# download CIFAR-10 python
py_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/cifar-10-python.tar.gz"
download(py_url, "./datasets", kind="tar.gz", replace=True)
cifar10_path = './datasets/cifar-10-batches-py'
cifar10_mindrecord_path = './transform/cifar10.record'
cifar10_transformer = Cifar10ToMR(cifar10_path, cifar10_mindrecord_path)
# execute transformation from CIFAR-10 to MindRecord
cifar10_transformer.transform(['label'])
# create MindDataset for reading data
cifar10_mind_dataset = ds.MindDataset(dataset_files=cifar10_mindrecord_path, num_parallel_workers=4)
# create a dictionary iterator and read a data record through the iterator
print(next(cifar10_mind_dataset.create_dict_iterator(output_numpy=True)))
{'data': array([b'\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x00\x00\x01\x00\x01\x00\x00\xff
...
...
\x88\xf4\xfdjY\xf5\x04\xf2c\xbb\xf2%\x02\xd0\x8eL\xa6\xbes\x8ew\x80\xa5\x18W\xbc\xfb5
\x14\xae6\x88\xae'], dtype='|S1405'), 'id': array(20374, dtype=int64), 'label': array(5, dtype=int64)}
使用
GeneratorDataset类加载自定义数据集,并且采取多进程优化方案,开启了4个进程并发完成任务,最后对数据创建了字典迭代器,并通过迭代器读取了一条数据记录。
[4]:
import numpy as np
def generator_func(num):
for i in range(num):
yield (np.array([i]),)
# create GeneratorDataset for reading data
dataset = ds.GeneratorDataset(source=generator_func(5), column_names=["data"], num_parallel_workers=4)
# create a dictionary iterator and read a data record through the iterator
print(next(dataset.create_dict_iterator()))
{'data': Tensor(shape=[1], dtype=Int64, value= [0])}
shuffle性能优化
shuffle操作用于对有序数据集或经过repeat的数据集进行混洗。MindSpore提供了shuffle函数,它是基于内存缓存实现的。其中设定的buffer_size参数越大,混洗程度越大,但会增加内存和时间消耗。该接口支持在pipeline的任意阶段对数据进行混洗,具体内容请参考shuffle处理。
但由于其基于内存缓存方式实现,性能不如直接在数据集加载操作中设置shuffle=True(默认值)参数进行混洗。
shuffle方案选择参考如下:
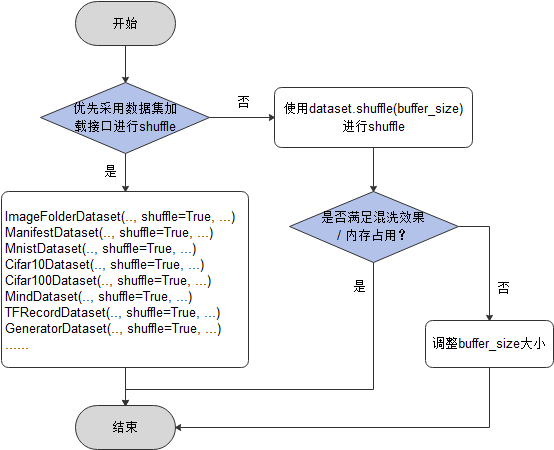
shuffle性能优化建议如下:
直接使用数据集加载接口中的
shuffle=True参数进行数据的混洗;如果使用的是
shuffle函数,当混洗效果无法满足需求,可增大buffer_size参数的值;当内存占用率过高时,可适当减小buffer_size参数的值。
基于以上的shuffle方案建议,本次体验分别使用数据集加载操作Cifar10Dataset类的shuffle参数和shuffle函数进行数据的混洗,代码演示如下:
使用数据集加载接口
Cifar10Dataset类加载CIFAR-10数据集,这里使用的是CIFAR-10二进制格式的数据集,并且设置shuffle参数为True来进行数据混洗,最后对数据创建了字典迭代器,并通过迭代器读取了一条数据记录。
[5]:
cifar10_path = "./datasets/cifar-10-batches-bin/train"
# create Cifar10Dataset for reading data
cifar10_dataset = ds.Cifar10Dataset(cifar10_path, shuffle=True)
# create a dictionary iterator and read a data record through the iterator
print(next(cifar10_dataset.create_dict_iterator()))
{'image': Tensor(shape=[32, 32, 3], dtype=UInt8, value=
[[[213, 205, 194],
[215, 207, 196],
[219, 210, 200],
...
[253, 254, 249],
[253, 254, 249],
[253, 254, 249]],
[[218, 208, 198],
[220, 210, 200],
[222, 212, 202],
...
[253, 254, 249],
[253, 254, 249],
[253, 254, 249]],
[[219, 209, 198],
[222, 211, 200],
[224, 214, 202],
...
[254, 253, 248],
[254, 253, 248],
[254, 253, 248]],
...
[[135, 141, 139],
[135, 141, 139],
[146, 152, 150],
...
[172, 174, 172],
[181, 182, 182],
[168, 168, 167]],
[[113, 119, 117],
[109, 115, 113],
[117, 123, 121],
...
[155, 159, 156],
[150, 155, 155],
[135, 140, 140]],
[[121, 127, 125],
[117, 123, 121],
[121, 127, 125],
...
[180, 184, 180],
[141, 146, 144],
[125, 130, 129]]]), 'label': Tensor(shape=[], dtype=UInt32, value= 8)}
使用
shuffle函数进行数据混洗,参数buffer_size设置为3,数据采用GeneratorDataset类自定义生成。
[6]:
def generator_func():
for i in range(5):
yield (np.array([i, i+1, i+2, i+3, i+4]),)
ds1 = ds.GeneratorDataset(source=generator_func, column_names=["data"])
print("before shuffle:")
for data in ds1.create_dict_iterator():
print(data["data"])
ds2 = ds1.shuffle(buffer_size=3)
print("after shuffle:")
for data in ds2.create_dict_iterator():
print(data["data"])
before shuffle:
[0 1 2 3 4]
[1 2 3 4 5]
[2 3 4 5 6]
[3 4 5 6 7]
[4 5 6 7 8]
after shuffle:
[2 3 4 5 6]
[3 4 5 6 7]
[1 2 3 4 5]
[0 1 2 3 4]
[4 5 6 7 8]
数据增强性能优化
在训练任务中,尤其是当数据集比较小的时候,用户可以使用数据增强的方法来预处理图片,达到丰富数据集的目的。MindSpore为用户提供了多种数据增强操作,其中包括:
Vision类数据增强操作,主要基于C++实现,见Vision数据增强。
NLP类数据增强操作,主要基于C++实现,见NLP数据增强。
Audio类数据增强操作,主要基于C++实现,见Audio数据增强。
用户可根据需求,自定义Python数据增强函数(Python实现)。
由于实现方式不同(C++实现与Python实现),数据增强操作的性能也存在差异,具体如下所示:
编程语言 |
说明 |
|---|---|
C++ |
使用C++代码实现,性能较高 |
Python |
使用Python代码实现,更加灵活 |
数据增强操作选择参考:
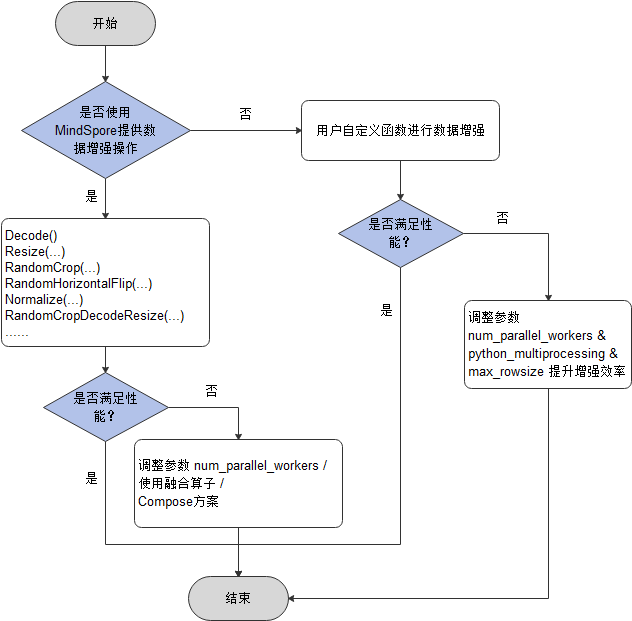
数据增强性能优化建议如下:
优先使用MindSpore提供的数据增强操作,以获得更好的性能。如果性能仍无法满足需求,可通过以下方式优化:
多线程优化
增大
map接口参数num_parallel_workers(默认值:8)的值,以提升性能。融合算子优化
当CPU占用率比较高时(如:单机多卡训练),使用融合操作(将多个操作聚合为一个)降低CPU占用,提升性能。可以通过设置环境变量
export OPTIMIZE=true来使其生效。融合示例如下: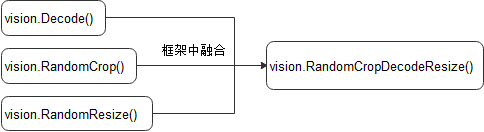
Compose优化
当CPU占用率比较高时(如:单机多卡训练),通过一个map操作接收多个增强操作(会按照顺序应用这些操作),降低CPU竞争,提升性能。示例如下:
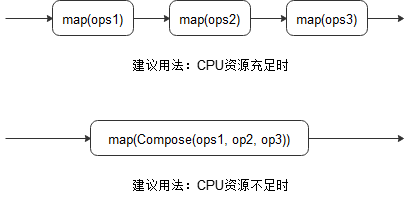
如果用户使用自定义Python函数进行数据增强,性能仍无法满足需求,可采取多进程或多线程并发方案,参考如下。但如果还是无法提升性能,则需要对自定义的Python函数进行优化。
增大
map接口参数num_parallel_workers(默认值:8)的值,以提升并发度;将
map接口的参数python_multiprocessing设置为True或False(默认值),分别启动多进程或多线程模式。多进程模式适用于CPU计算密集型任务,多线程适用于IO密集型任务;如果出现
Using shared memory queue, but rowsize is larger than allocated memory ...日志提示,可按提示增大max_rowsize参数,或直接设为None,以提升进程间数据传递效率。
基于以上的数据增强性能优化建议,本次体验分别使用实现在C++层的数据增强操作和自定义Python函数进行数据增强,演示代码如下所示:
使用实现在C++层的数据增强操作,采用多线程优化方案,开启了4个线程并发完成任务,并且采用了融合算子优化方案,框架中使用
RandomResizedCrop融合类替代RandomResize类和RandomCrop类。
[7]:
import mindspore.dataset.vision as vision
import matplotlib.pyplot as plt
cifar10_path = "./datasets/cifar-10-batches-bin/train"
# create Cifar10Dataset for reading data
cifar10_dataset = ds.Cifar10Dataset(cifar10_path, num_parallel_workers=4)
transforms = vision.RandomResizedCrop((800, 800))
# apply the transform to the dataset through dataset.map()
cifar10_dataset = cifar10_dataset.map(operations=transforms, input_columns="image", num_parallel_workers=4)
data = next(cifar10_dataset.create_dict_iterator())
plt.imshow(data["image"].asnumpy())
plt.show()

使用自定义Python函数进行数据增强,数据增强时采用多进程优化方案,开启了4个进程并发完成任务。
[8]:
def generator_func():
for i in range(5):
yield (np.array([i, i+1, i+2, i+3, i+4]),)
ds3 = ds.GeneratorDataset(source=generator_func, column_names=["data"])
print("before map:")
for data in ds3.create_dict_iterator():
print(data["data"])
def preprocess(x):
return (x**2,)
ds4 = ds3.map(operations=preprocess, input_columns="data", python_multiprocessing=True, num_parallel_workers=4)
print("after map:")
for data in ds4.create_dict_iterator():
print(data["data"])
before map:
[0 1 2 3 4]
[1 2 3 4 5]
[2 3 4 5 6]
[3 4 5 6 7]
[4 5 6 7 8]
after map:
[ 0 1 4 9 16]
[ 1 4 9 16 25]
[ 4 9 16 25 36]
[ 9 16 25 36 49]
[16 25 36 49 64]
batch操作性能优化
在数据处理的最后阶段,会使用batch操作将多条数据组织成一个batch,然后再传递给网络用于训练。对于batch操作的性能优化建议如下:
仅配置batch_size和drop_remainder,且batch_size比较大时,建议增大
num_parallel_workers(默认值:8)的值,以提升性能;如果使用per_batch_map功能,建议配置如下:
增大参数
num_parallel_workers(默认值:8)的值,以提升并发度;将参数
python_multiprocessing设置为True或False(默认值),分别启动多进程或多线程模式。多进程模式适用于CPU计算密集型任务,多线程适用于IO密集型任务;如果出现
Using shared memory queue, but rowsize is larger than allocated memory ...日志提示,可按提示增大max_rowsize参数,或直接设为None,以提升进程间数据传递的效率。
操作系统性能优化
由于MindSpore的数据处理主要在Host端进行,运行环境的配置也会影响处理性能,主要体现在存储设备、NUMA架构和CPU计算资源等方面。
存储设备
数据加载过程涉及频繁的磁盘操作,磁盘读写性能直接影响数据加载速度。当数据集较大时,推荐使用固态硬盘存储,固态硬盘的读写速度普遍高于普通磁盘,能够减少I/O操作对数据处理性能的影响。
通常,加载后的数据将会被缓存到操作系统的页面缓存中,在一定程度上降低了后续读取的开销,加快后续Epoch的数据加载速度。用户也可以通过MindSpore提供的单节点缓存技术,手动缓存加载增强后的数据,避免重复加载和增强。
NUMA架构
NUMA(Non-Uniform Memory Access,非一致性内存访问),是一种为解决传统对称多处理器(SMP)架构可扩展性问题而设计的内存架构。在传统架构中,多个处理器共用一条内存总线,容易产生带宽不足、内存冲突等问题。
而在NUMA架构中,处理器和内存被划分为多个组,每个组称为一个节点(Node),各个节点拥有独立的集成内存控制器(IMC)总线,用于节点内通信,不同节点间则通过快速路径互连(QPI)进行通信。对于某一节点来说,处在同节点内的内存被称为本地内存,处在其他节点的内存被称为外部内存,访问本地内存的延迟会小于访问外部内存的延迟。
在数据处理过程中,可以通过将进程与节点绑定,来减小内存访问的延迟。一般我们可以使用以下命令绑定进程与node节点,或者通过设置环境变量
export DATASET_ENABLE_NUMA=True,使每个训练进程绑定至不同的numa节点。numactl --cpubind=0 --membind=0 python train.py
CPU计算资源
尽管可以通过多线程并行技术加快数据处理的速度,但是实际运行时并不能保证CPU计算资源完全被利用起来。如果能够提前配置计算资源分配策略,可在一定程度上提高CPU利用率。
计算资源的分配
在分布式训练中,同一设备上可能开启多个训练进程。默认情况下,各个进程的资源分配与抢占遵循操作系统策略,当进程较多时,频繁的资源竞争可能会导致数据处理性能下降。如果能够提前配置计算资源分配策略,可避免资源竞争带来的开销。
numactl --cpubind=0 python train.py
CPU频率设置
出于节约能效的考虑,操作系统会根据需要动态调整CPU的运行频率,但较低的功耗意味着计算性能下降、数据处理速度减慢。要想充分发挥CPU算力,需要手动设置CPU的运行频率。如果发现操作系统的CPU运行模式为平衡或节能模式,可调整为性能模式,提升数据处理性能。
cpupower frequency-set -g performance
多线程竞争
如果用户在数据处理阶段使用了
cv2、numpy、numba等三方库,且使用top命令查看CPU时,sy占用高而us占用低,说明存在线程竞争。可通过以下方式解决:如果数据处理阶段有
opencv的cv2操作,可通过cv2.setNumThreads(2)设置cv2全局线程数,减少线程竞争;如果数据处理阶段有
numpy操作,可通过export OPENBLAS_NUM_THREADS=1设置OPENBLAS线程数,减少线程竞争;如果数据处理阶段有
numba操作,可通过numba.set_num_threads(1)设置并行度,减少线程竞争。
CPU/内存占用率高
MindSpore Dataset主要使用Host侧CPU和内存做数据处理。在CPU和内存资源比较紧张的环境下,数据预处理时可能会出现CPU或内存占用过高的现象。可通过以下方法降低CPU和内存占用率,但会有一定程度的性能损失。详细使用指导可参考:https://blog.csdn.net/guozhijian521/article/details/123552540
在定义
**Dataset对象前,设置数据处理预取的大小:ds.config.set_prefetch_size(2);在定义
**Dataset对象时,可将参数num_parallel_workers设为1;如果使用
.map(...)操作,可将参数num_parallel_workers设为1;如果使用
.batch(...)操作,可将参数num_parallel_workers设为1;如果使用
.shuffle(...)操作,可适当减少buffer_size参数;如果有多个
.map(...)操作,可合并为一个。
单卡训练 VS 多卡训练并行度优化建议
在使用MindSpore进行单卡或多卡训练时,num_parallel_workers参数的设置应遵循以下原则:
各数据加载和处理操作所设置的num_parallel_workers参数之和,应不超过CPU支持的最大线程数,否则会导致操作间的资源竞争。
在设置num_parallel_workers参数前,建议先使用MindSpore Profiler(性能分析工具)分析各操作的性能情况,将更多资源分配给性能较差的操作,即设置更大的num_parallel_workers,使各操作之间的吞吐达到平衡,避免不必要的等待。
在单卡训练场景中,提高num_parallel_workers参数通常能直接提升性能。但在多卡场景下,由于CPU竞争加剧,盲目提高该参数可能会导致性能劣化,需要在实际训练中尝试使用折中数值。
自动数据加速
MindSpore提供了一种自动数据调优的工具——Dataset AutoTune,可在训练过程中根据环境资源自动调整数据处理管道的并行度,最大化利用系统资源,加速数据处理。详细用法请参考自动数据加速。
数据异构加速
MindSpore提供运算负载均衡技术,可将Tensor运算分配到不同的异构硬件上,既均衡各硬件的运算开销,又能利用异构硬件的优势加速运算。详细用法请参考数据异构加速。