实现一个云云联邦的目标检测应用(x86)
![]()
根据参与客户端的类型,联邦学习可分为云云联邦学习(cross-silo)和端云联邦学习(cross-device)。在云云联邦学习场景中,参与联邦学习的客户端是不同的组织(例如,医疗或金融)或地理分布的数据中心,即在多个数据孤岛上训练模型。在端云联邦学习场景中,参与的客户端为大量的移动或物联网设备。本框架将介绍如何在MindSpore Federated云云联邦框架上使用网络Fast R-CNN实现一个目标检测应用。
启动云云联邦的目标检测应用的完整脚本可参考这里。
任务前准备
本教程基于MindSpore model_zoo中提供的的faster_rcnn网络部署云云联邦目标检测任务,请先根据官方faster_rcnn教程及代码先了解COCO数据集、faster_rcnn网络结构、训练过程以及评估过程。由于COCO数据集已开源,请参照其官网指引自行下载好数据集,并进行数据集切分(例如模拟100个客户端,可将数据集切分成100份,每份代表一个客户端所持有的数据)。
由于原始COCO数据集为json文件格式,云云联邦学习框架提供的目标检测脚本暂时只支持MindRecord格式输入数据,可根据以下步骤将json文件转换为MindRecord格式文件。
首先在配置文件default_config.yaml中设置以下参数:
参数
mindrecord_dir用于设置生成的MindRecord格式文件保存路径,文件夹名称必须为mindrecord_{num}格式,数字num代表客户端标号0,1,2,3,……
mindrecord_dir:"./datasets/coco_split/split_100/mindrecord_0"参数
instance_set用于设置原始json文件路径。
instance_set: "./datasets/coco_split/split_100/train_0.json"
运行脚本generate_mindrecord.py即可生成
train_0.json对应的MindRecord文件,保存在路径mindrecord_dir中。
启动云云联邦任务
安装MindSpore和Mindspore Federated
包括源码和下载发布版两种方式,支持CPU、GPU、Ascend硬件平台,根据硬件平台选择安装即可。安装步骤可参考MindSpore安装指南,Mindspore Federated安装指南。
目前联邦学习框架只支持Linux环境中部署,cross-silo联邦学习框架需要MindSpore版本号>=1.5.0。
启动任务
参考示例,启动集群。参考示例目录结构如下:
cross_silo_faster_rcnn
├── src
│ ├── FasterRcnn
│ │ ├── __init__.py // init文件
│ │ ├── anchor_generator.py // 锚点生成器
│ │ ├── bbox_assign_sample.py // 第一阶段采样器
│ │ ├── bbox_assign_sample_stage2.py // 第二阶段采样器
│ │ ├── faster_rcnn_resnet.py // Faster R-CNN网络
│ │ ├── faster_rcnn_resnet50v1.py // 以Resnet50v1.0作为backbone的Faster R-CNN网络
│ │ ├── fpn_neck.py // 特征金字塔网络
│ │ ├── proposal_generator.py // 候选生成器
│ │ ├── rcnn.py // R-CNN网络
│ │ ├── resnet.py // 骨干网络
│ │ ├── resnet50v1.py // Resnet50v1.0骨干网络
│ │ ├── roi_align.py // ROI对齐网络
│ │ └── rpn.py // 区域候选网络
│ ├── dataset.py // 创建并处理数据集
│ ├── lr_schedule.py // 学习率生成器
│ ├── network_define.py // Faster R-CNN网络定义
│ ├── util.py // 例行操作
│ └── model_utils
│ ├── __init__.py // init文件
│ ├── config.py // 获取.yaml配置参数
│ ├── device_adapter.py // 获取云上id
│ ├── local_adapter.py // 获取本地id
│ └── moxing_adapter.py // 云上数据准备
├── requirements.txt
├── mindspore_hub_conf.py
├── generate_mindrecord.py // 将.json格式的annotations文件转化为MindRecord格式,以便读取datasets
├── default_yaml_config.yaml // 联邦训练所需配置文件
├── default_config.yaml // 网络结构、数据集地址、fl_plan所需配置文件
├── run_cross_silo_fasterrcnn_worker.py // 启动云云联邦worker脚本
├── run_cross_silo_fasterrcnn_worker_distribute.py // 启动云云联邦分布式worker训练脚本
└── test_fl_fasterrcnn.py // 客户端使用的训练脚本
└── run_cross_silo_fasterrcnn_sched.py // 启动云云联邦scheduler脚本
└── run_cross_silo_fasterrcnn_server.py // 启动云云联邦server脚本
注意在
test_fl_fasterrcnn.py文件中可通过设置参数dataset_sink_mode来选择是否记录每个step的loss值:model.train(config.client_epoch_num, dataset, callbacks=cb, dataset_sink_mode=True) # 不设置dataset_sink_mode代表只记录每个epoch中最后一个step的loss值。 model.train(config.client_epoch_num, dataset, callbacks=cb, dataset_sink_mode=False) # 设置dataset_sink_mode=False代表记录每个step的loss值,代码里默认为这种方式。
在配置文件default_config.yaml中设置以下参数:
参数
pre_trained用于设置预训练模型路径(.ckpt 格式)。
本教程中实验的预训练模型是在ImageNet2012上训练的ResNet-50检查点。你可以使用ModelZoo中 resnet50 脚本来训练,然后使用src/convert_checkpoint.py把训练好的resnet50的权重文件转换为可加载的权重文件。
启动redis
redis-server --port 2345 --save ""
启动Scheduler
run_sched.py是用于启动Scheduler的Python脚本,并支持通过argparse传参修改配置。执行指令如下,代表启动本次联邦学习任务的Scheduler,--yaml_config用于设置yaml文件路径,其管理ip:port为127.0.0.1:18019。python run_cross_silo_fasterrcnn_sched.py --yaml_config="default_yaml_config.yaml" --scheduler_manage_address="127.0.0.1:18019"
具体实现详见run_cross_silo_fasterrcnn_sched.py。
打印如下代表启动成功:
[INFO] FEDERATED(3944,2b280497ed00,python):2022-10-10-17:11:08.154.878 [mindspore_federated/fl_arch/ccsrc/scheduler/scheduler.cc:35] Run] Scheduler started successfully. [INFO] FEDERATED(3944,2b28c5ada700,python):2022-10-10-17:11:08.155.056 [mindspore_federated/fl_arch/ccsrc/common/communicator/http_request_handler.cc:90] Run] Start http server!
启动Server
run_cross_silo_fasterrcnn_server.py是用于启动若干Server的Python脚本,并支持通过argparse传参修改配置。执行指令如下,代表启动本次联邦学习任务的Server,其TCP地址为127.0.0.1,联邦学习HTTP服务起始端口为6668,Server数量为4个。python run_cross_silo_fasterrcnn_server.py --yaml_config="default_yaml_config.yaml" --tcp_server_ip="127.0.0.1" --checkpoint_dir="/path/to/fl_ckpt" --local_server_num=4 --http_server_address="127.0.0.1:6668"
以上指令等价于启动了4个
Server进程,每个Server的联邦学习服务端口分别为6668、6669、6670和6671,具体实现详见run_cross_silo_fasterrcnn_server.py。其中checkpoint_dir需要输入checkpoint所在的目录路径,server会从该路径下读取checkpoint初始化权重,checkpoint的前缀格式需要是{fl_name}_recovery_iteration_。打印如下代表启动成功:
[INFO] FEDERATED(3944,2b280497ed00,python):2022-10-10-17:11:08.154.645 [mindspore_federated/fl_arch/ccsrc/common/communicator/http_server.cc:122] Start] Start http server! [INFO] FEDERATED(3944,2b280497ed00,python):2022-10-10-17:11:08.154.725 [mindspore_federated/fl_arch/ccsrc/common/communicator/http_request_handler.cc:85] Initialize] Ev http register handle of: [/d isableFLS, /enableFLS, /state, /queryInstance, /newInstance] success. [INFO] FEDERATED(3944,2b280497ed00,python):2022-10-10-17:11:08.154.878 [mindspore_federated/fl_arch/ccsrc/scheduler/scheduler.cc:35] Run] Scheduler started successfully. [INFO] FEDERATED(3944,2b28c5ada700,python):2022-10-10-17:11:08.155.056 [mindspore_federated/fl_arch/ccsrc/common/communicator/http_request_handler.cc:90] Run] Start http server!
启动Worker
run_cross_silo_femnist_worker.py是用于启动若干worker的Python脚本,并支持通过argparse传参修改配置。执行指令如下,代表启动本次联邦学习任务的worker,联邦学习任务正常进行需要的worker数量至少为2个:python run_cross_silo_fasterrcnn_worker.py --local_worker_num=2 --yaml_config="default_yaml_config.yaml" --pre_trained="/path/to/pre_trained" --dataset_path=/path/to/datasets/coco_split/split_100 --http_server_address=127.0.0.1:6668
具体实现详见run_cross_silo_femnist_worker.py。在数据下沉模式下,云云联邦的同步频率以epoch为单位,否则同步频率以step为单位。
如上指令,
--local_worker_num=2代表启动两个客户端,且两个客户端使用的数据集分别为datasets/coco_split/split_100/mindrecord_0和datasets/coco_split/split_100/mindrecord_1,请根据任务前准备教程准备好对应客户端所需数据集。当执行以上三个指令之后,等待一段时间之后,进入当前目录下
worker_0文件夹,通过指令grep -rn "\epoch:" *查看worker_0日志,可看到类似如下内容的日志信息:epoch: 1 step: 1 total_loss: 0.6060338
则说明云云联邦启动成功,
worker_0正在训练,其他worker可通过类似方式查看。当前云云联邦的
worker节点支持单机多卡&多机多卡的分布式训练方式,run_cross_silo_fasterrcnn_worker_distributed.py是为用户启动worker节点的分布式训练而提供的Python脚本,并支持通过argparse传参修改配置。执行指令如下,代表启动本次联邦学习任务的分布式worker,其中device_num表示worker集群启动的进程数目,run_distribute表示启动集群的分布式训练,其http起始端口为6668,worker进程数量为4个:python run_cross_silo_fasterrcnn_worker_distributed.py --device_num=4 --run_distribute=True --dataset_path=/path/to/datasets/coco_split/split_100 --http_server_address=127.0.0.1:6668
进入当前目录下
worker_distributed/log_output/文件夹,通过指令grep -rn "epoch" *查看worker分布式集群的日志,可看到如下类似打印:epoch: 1 step: 1 total_loss: 0.613467
以上脚本中参数配置说明请参考yaml配置说明。
日志查看
成功启动任务之后,会在当前目录cross_silo_faster_rcnn下生成相应日志文件,日志文件目录结构如下:
cross_silo_faster_rcnn
├── scheduler
│ └── scheduler.log # 运行scheduler过程中打印日志
├── server_0
│ └── server.log # server_0运行过程中打印日志
├── server_1
│ └── server.log # server_1运行过程中打印日志
├── server_2
│ └── server.log # server_2运行过程中打印日志
├── server_3
│ └── server.log # server_3运行过程中打印日志
├── worker_0
│ ├── ckpt # 存放worker_0在每个联邦学习迭代结束时获取的聚合后的模型ckpt
│ │ └── mindrecord_0
│ │ ├── mindrecord_0-fast-rcnn-0epoch.ckpt
│ │ ├── mindrecord_0-fast-rcnn-1epoch.ckpt
│ │ │
│ │ │ ......
│ │ │
│ │ └── mindrecord_0-fast-rcnn-29epoch.ckpt
│ ├──loss_0.log # 记录worker_0训练过程中的每个step的loss值
│ └── worker.log # 记录worker_0参与联邦学习任务过程中输出日志
└── worker_1
├── ckpt # 存放worker_1在每个联邦学习迭代结束时获取的聚合后的模型ckpt
│ └── mindrecord_1
│ ├── mindrecord_1-fast-rcnn-0epoch.ckpt
│ ├── mindrecord_1-fast-rcnn-1epoch.ckpt
│ │
│ │ ......
│ │
│ └── mindrecord_1-fast-rcnn-29epoch.ckpt
├──loss_0.log # 记录worker_1训练过程中的每个step的loss值
└── worker.log # 记录worker_1参与联邦学习任务过程中输出日志
关闭任务
若想中途退出,则可用以下指令:
python finish_cross_silo_fasterrcnn.py --redis_port=2345
具体实现详见finish_cloud.py。
或者等待训练任务结束之后集群会自动退出,不需要手动关闭。
实验结果
使用数据:
COCO数据集,拆分为100份,取前两份分别作为两个worker的数据集
客户端本地训练epoch数:1
云云联邦学习总迭代数:30
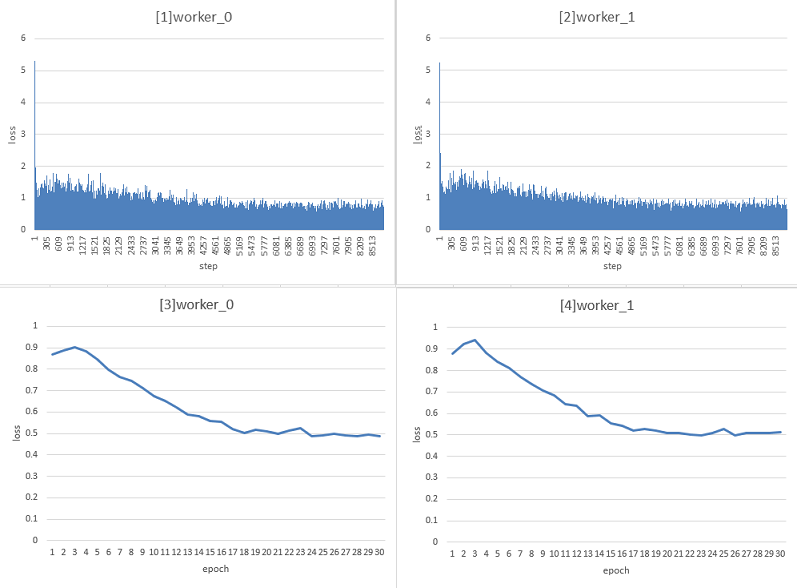
实验结果(记录客户端本地训练过程中的loss值):
进入当前目录下
worker_0文件夹,通过指令grep -rn "\]epoch:" *查看worker_0日志,可看到每个step输出的loss值,如下所示:epoch: 1 step: 1 total_loss: 5.249325 epoch: 1 step: 2 total_loss: 4.0856013 epoch: 1 step: 3 total_loss: 2.6916502 epoch: 1 step: 4 total_loss: 1.3917351 epoch: 1 step: 5 total_loss: 0.8109232 epoch: 1 step: 6 total_loss: 0.99101084 epoch: 1 step: 7 total_loss: 1.7741735 epoch: 1 step: 8 total_loss: 0.9517553 epoch: 1 step: 9 total_loss: 1.7988946 epoch: 1 step: 10 total_loss: 1.0213892 epoch: 1 step: 11 total_loss: 1.1700443 . . .
worker_0和worker_1在30个迭代的训练过程中,统计每个step的训练loss变换柱状图如下[1]和[2]:
worker_0和worker_1在30个迭代的训练过程中,统计每个epoch的平均loss (一个epoch中包含的所有step的loss之和除以step数)的折线图如下[3]和[4]: