实现一个端云联邦的图像分类应用(x86)
![]()
根据参与客户端的类型,联邦学习可分为云云联邦学习(cross-silo)和端云联邦学习(cross-device)。在云云联邦学习场景中,参与联邦学习的客户端是不同的组织(例如,医疗或金融)或地理分布的数据中心,即在多个数据孤岛上训练模型。在端云联邦学习场景中,参与的客户端为大量的移动或物联网设备。本框架将介绍如何在MindSpore端云联邦框架上使用网络LeNet实现一个图片分类应用,并提供在x86环境中模拟启动多客户端参与联邦学习的相关教程。
在动手进行实践之前,确保你已经正确安装了MindSpore。如果没有,可以参考MindSpore安装页面完成安装。
准备工作
我们提供了可供用户直接使用的联邦学习图像分类数据集FEMNIST,以及.ms格式的端侧模型文件。用户也可以根据实际需求,参考以下教程自行生成数据集和模型。
生成端侧模型文件
定义网络和训练过程。
具体网络和训练过程的定义可参考快速入门。
将模型导出为MindIR格式文件。
代码片段如下:
import argparse import numpy as np import mindspore as ms import mindspore.nn as nn def conv(in_channels, out_channels, kernel_size, stride=1, padding=0): """weight initial for conv layer""" weight = weight_variable() return nn.Conv2d( in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, weight_init=weight, has_bias=False, pad_mode="valid", ) def fc_with_initialize(input_channels, out_channels): """weight initial for fc layer""" weight = weight_variable() bias = weight_variable() return nn.Dense(input_channels, out_channels, weight, bias) def weight_variable(): """weight initial""" return ms.common.initializer.TruncatedNormal(0.02) class LeNet5(nn.Cell): def __init__(self, num_class=10, channel=3): super(LeNet5, self).__init__() self.num_class = num_class self.conv1 = conv(channel, 6, 5) self.conv2 = conv(6, 16, 5) self.fc1 = fc_with_initialize(16 * 5 * 5, 120) self.fc2 = fc_with_initialize(120, 84) self.fc3 = fc_with_initialize(84, self.num_class) self.relu = nn.ReLU() self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2) self.flatten = nn.Flatten() def construct(self, x): x = self.conv1(x) x = self.relu(x) x = self.max_pool2d(x) x = self.conv2(x) x = self.relu(x) x = self.max_pool2d(x) x = self.flatten(x) x = self.fc1(x) x = self.relu(x) x = self.fc2(x) x = self.relu(x) x = self.fc3(x) return x parser = argparse.ArgumentParser(description="export mindir for lenet") parser.add_argument("--device_target", type=str, default="CPU") parser.add_argument("--mindir_path", type=str, default="lenet_train.mindir") # the mindir file path of the model to be export args, _ = parser.parse_known_args() device_target = args.device_target mindir_path = args.mindir_path ms.set_context(mode=ms.GRAPH_MODE, device_target=device_target) if __name__ == "__main__": np.random.seed(0) network = LeNet5(62) criterion = nn.SoftmaxCrossEntropyWithLogits(sparse=False, reduction="mean") net_opt = nn.Momentum(network.trainable_params(), 0.01, 0.9) net_with_criterion = nn.WithLossCell(network, criterion) train_network = nn.TrainOneStepCell(net_with_criterion, net_opt) train_network.set_train() data = ms.Tensor(np.random.rand(32, 3, 32, 32).astype(np.float32)) label = ms.Tensor(np.random.randint(0, 1, (32, 62)).astype(np.float32)) ms.export(train_network, data, label, file_name=mindir_path, file_format='MINDIR') # Add the export statement to obtain the model file in MindIR format.
参数
--mindir_path用于设置生成的MindIR格式文件路径。将MindIR文件转化为联邦学习端侧框架可用的ms文件。
模型转换可参考训练模型转换教程。
模型转换示例如下:
假设待转换的模型文件为
lenet_train.mindir,执行如下转换命令:./converter_lite --fmk=MINDIR --trainModel=true --modelFile=lenet_train.mindir --outputFile=lenet_train
转换成功输出如下:
CONVERT RESULT SUCCESS:0
这表明MindSpore模型成功转换为MindSpore端侧模型,并生成了新文件
lenet_train.ms。如果转换失败输出如下:CONVERT RESULT FAILED:
生成的
.ms格式的模型文件为后续客户端所需的模型文件。
模拟启动多客户端参与联邦学习
为客户端准备好模型文件
本例在端侧使用lenet模拟实际用的网络,其中lenet的.ms格式的端侧模型文件,由于真实场景一个客户端只包含一个.ms格式的模型文件,在模拟场景中,需要拷贝多份.ms文件,并按照lenet_train{i}.ms格式进行命名。其中i代表客户端编号,由于run_client_x86.py中,已自动为每个客户端拷贝.ms文件。
具体见启动脚本中的copy_ms函数。
启动云侧服务
用户可先参考横向云侧部署教程部署云侧环境,并启动云侧服务。
启动客户端
启动客户端之前请先参照横向端侧部署教程进行端侧环境部署。
使用提供的run_client_x86.py脚本进行端侧联邦学习的启动,通过相关参数的设置,来启动不同的联邦学习接口。
待云侧服务启动成功之后,使用提供run_client_x86.py的脚本,调用联邦学习框架jar包mindspore-lite-java-flclient.jar 和模型脚本对应的jar包quick_start_flclient.jar(可参考横向端侧部署中编译出包流程获取)来模拟启动多客户端参与联邦学习任务。
以LeNet网络为例,run_client_x86.py脚本中部分入参含义如下,用户可根据实际情况进行设置:
--fl_jar_path设置联邦学习jar包路径,x86环境联邦学习jar包获取可参考横向端侧部署中编译出包流程。
--case_jar_path设置模型脚本所生成的jar包
quick_start_flclient.jar的路径,x86环境联邦学习jar包获取可参考横向联邦端侧部署中编译出包流程。--lite_jar_path设置mindspore lite的端侧jar包
mindspore-lite-java.jar的路径,位于端侧包mindspore-lite-{version}-linux-x64.tar.gz中,x86环境联邦学习jar包获取可参考横向端侧部署中构建环境依赖。--train_data_dir训练数据集root路径,LeNet图片分类任务在该root路径中存放的是每个客户端的训练data.bin文件与label.bin文件,例如
data/femnist/3500_clients_bin/。--fl_name联邦学习使用的模型脚本包路径。我们提供了两个类型的模型脚本供大家参考(有监督情感分类任务、LeNet图片分类任务),对于有监督情感分类任务,该参数可设置为所提供的脚本文件AlBertClient.java 的包路径
com.mindspore.flclient.demo.albert.AlbertClient;对于LeNet图片分类任务,该参数可设置为所提供的脚本文件LenetClient.java 的包路径com.mindspore.flclient.demo.lenet.LenetClient。同时,用户可参考这两个类型的模型脚本,自定义模型脚本,然后将该参数设置为自定义的模型文件ModelClient.java(需继承于类Client.java)的包路径即可。--train_model_dir设置联邦学习使用的训练模型路径,为上面教程中拷贝的多份.ms文件所存放的目录,比如
ms/lenet,必须为绝对路径。--domain_name用于设置端云通信url,目前,可支持https和http通信,对应格式分别为:https://……、http://……,当
if_use_elb设置为true时,格式必须为:https://127.0.0.1:6666 或者http://127.0.0.1:6666 ,其中127.0.0.1对应提供云侧服务的机器ip(即云侧参数--scheduler_ip),6666对应云侧参数--fl_server_port。注意1,当该参数设置为
http://......时代表使用HTTP通信,可能会存在通信安全风险,请知悉。注意2,当该参数设置为
https://......代表使用HTTPS通信。此时必须进行SSL证书认证,需要通过参数--cert_path设置证书路径。--task用于设置本此启动的任务类型,为
train代表启动训练任务,为inference代表启动多条数据推理任务,为getModel代表启动获取云侧模型的任务,设置其他字符串代表启动单条数据推理任务。默认为train。由于初始的模型文件(.ms文件)是未训练过的,建议先启动训练任务,待训练完成之后,再启动推理任务(注意两次启动的client_num保持一致,以保证inference使用的模型文件与train保持一致)。--batch_size设置联邦学习训练和推理时使用的单步训练样本数,即batch size。需与模型的输入数据的batch size保持一致。
--client_num设置client数量,与启动server端时的
start_fl_job_cnt保持一致,真实场景不需要此参数。
若想进一步了解run_client_x86.py脚本中其他参数含义,可参考脚本中注释部分。
联邦学习接口基本启动指令示例如下:
rm -rf client_*\
&& rm -rf ms/* \
&& python3 run_client_x86.py \
--fl_jar_path="federated/mindspore_federated/device_client/build/libs/jarX86/mindspore-lite-java-flclient.jar" \
--case_jar_path="federated/example/quick_start_flclient/target/case_jar/quick_start_flclient.jar" \
--lite_jar_path="federated/mindspore_federated/device_client/third/mindspore-lite-2.0.0-linux-x64/runtime/lib/mindspore-lite-java.jar" \
--train_data_dir="federated/tests/st/simulate_x86/data/3500_clients_bin/" \
--eval_data_dir="null" \
--infer_data_dir="null" \
--vocab_path="null" \
--ids_path="null" \
--path_regex="," \
--fl_name="com.mindspore.flclient.demo.lenet.LenetClient" \
--origin_train_model_path="federated/tests/st/simulate_x86/ms_files/lenet/lenet_train.ms" \
--origin_infer_model_path="null" \
--train_model_dir="ms" \
--infer_model_dir="ms" \
--ssl_protocol="TLSv1.2" \
--deploy_env="x86" \
--domain_name="http://10.*.*.*:8010" \
--cert_path="CARoot.pem" --use_elb="false" \
--server_num=1 \
--task="train" \
--thread_num=1 \
--cpu_bind_mode="NOT_BINDING_CORE" \
--train_weight_name="null" \
--infer_weight_name="null" \
--name_regex="::" \
--server_mode="FEDERATED_LEARNING" \
--batch_size=32 \
--input_shape="null" \
--client_num=8
注意,启动指令中涉及路径的必须给出绝对路径。
以上指令代表启动8个客户端参与联邦学习训练任务,若启动成功,会在当前文件夹生成8个客户端对应的日志文件,查看日志文件内容可了解每个客户端的运行情况:
./
├── client_0
│ └── client.log # 客户端0的日志文件
│ ......
└── client_7
└── client.log # 客户端4的日志文件
针对不同的接口和场景,只需根据参数含义,修改特定参数值即可,比如:
启动联邦学习训练任务SyncFLJob.flJobRun()
当
基本启动指令中--task设置为train时代表启动该任务。可通过指令
grep -r "average loss:" client_0/client.log查看client_0在训练过程中每个epoch的平均loss,会有类似如下打印:INFO: <FLClient> ----------epoch:0,average loss:4.1258564 ---------- ......
也可通过指令
grep -r "evaluate acc:" client_0/client.log查看client_0在每个联邦学习迭代中聚合后模型的验证精度,会有类似如下打印:INFO: <FLClient> [evaluate] evaluate acc: 0.125 ......
在云侧,可以通过设置yaml配置文件的
cluster_client_num参数与eval_type参数来指定进行无监督聚类指标统计的客户端group id数量与算法类型,在云侧生成的metrics.json统计文件可以查询到无监督指标信息:"unsupervisedEval":0.640 "unsupervisedEval":0.675 "unsupervisedEval":0.677 "unsupervisedEval":0.706 ......
启动推理任务SyncFLJob.modelInference()
当
基本启动指令中--task设置为inference时代表启动该任务。可通过指令
grep -r "the predicted labels:" client_0/client.log查看client_0的推理结果:INFO: <FLClient> [model inference] the predicted labels: [0, 0, 0, 1, 1, 1, 2, 2, 2] ......
启动获取云侧最新模型任务SyncFLJob.getModel()
当
基本启动指令中--task设置为getModel时代表启动该任务。在日志文件中若有如下内容代表获取云侧最新模型成功:
INFO: <FLClient> [getModel] get response from server ok!
关闭客户端进程
可参考finish.py脚本,具体如下:
关闭客户端指令如下:
python finish.py --kill_tag=mindspore-lite-java-flclient
其中参数--kill_tag用于搜索该关键字对客户端进程进行kill,只需要设置--jarPath中的特殊关键字即可。默认为mindspore-lite-java-flclient,即联邦学习jar包名。
用户可通过指令ps -ef |grep "mindspore-lite-java-flclient"查看进程是否还存在。
50个客户端参与联邦学习训练任务实验结果。
目前3500_clients_bin文件夹中包含3500个客户端的数据,本脚本最多可模拟3500个客户端参与联邦学习。
下图给出了50个客户端(设置server_num为16)进行联邦学习的测试集精度:
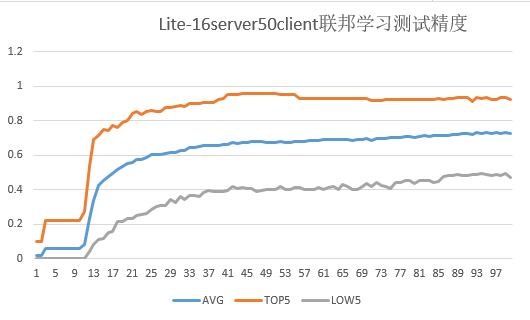
其中联邦学习总迭代数为100,客户端本地训练epoch数为20,batchSize设置为32。
图中测试精度指对于每个联邦学习迭代,各客户端测试集在云侧聚合后的模型上的精度。
AVG:对于每个联邦学习迭代,50个客户端测试集精度的平均值。
TOP5:对于每个联邦学习迭代,测试集精度最高的5个客户端的精度平均值。
LOW5:对于每个联邦学习迭代,测试集精度最低的5个客户端的精度平均值。