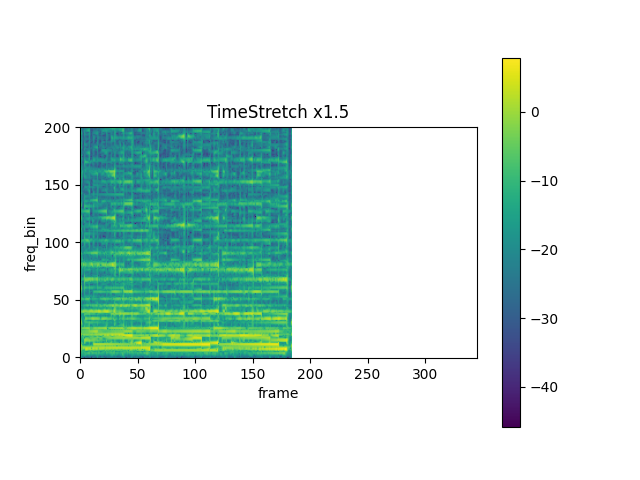
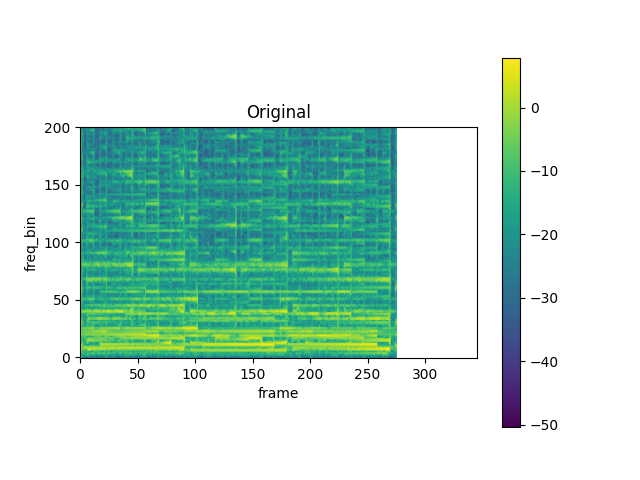
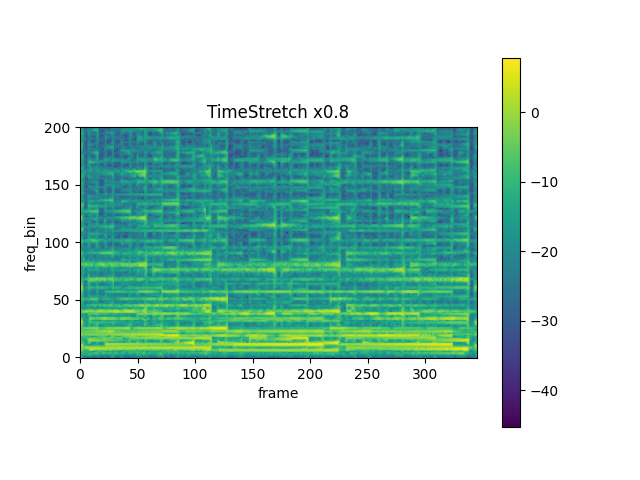
mindspore.dataset.audio.TimeStretch
- class mindspore.dataset.audio.TimeStretch(hop_length=None, n_freq=201, fixed_rate=None)[源代码]
以给定的比例拉伸音频短时傅里叶(Short Time Fourier Transform, STFT)频谱的时域,但不改变音频的音高。
说明
待处理音频shape需为<…, freq, time, complex=2>。第零维代表实部,第一维代表虚部。
- 参数:
hop_length (int, 可选) - STFT窗之间每跳的长度,即连续帧之间的样本数。默认值:
None,表示取 n_freq - 1 。n_freq (int, 可选) - STFT中的滤波器组数。默认值:
201。fixed_rate (float, 可选) - 频谱在时域加快或减缓的比例。默认值:
None,表示保持原始速率。
- 异常:
TypeError - 当 hop_length 的类型不为int。
ValueError - 当 hop_length 不为正数。
TypeError - 当 n_freq 的类型不为int。
ValueError - 当 n_freq 不为正数。
TypeError - 当 fixed_rate 的类型不为float。
ValueError - 当 fixed_rate 不为正数。
RuntimeError - 当输入音频的shape不为<…, freq, num_frame, complex=2>。
- 支持平台:
CPU
样例:
>>> import numpy as np >>> import mindspore.dataset as ds >>> import mindspore.dataset.audio as audio >>> >>> # Use the transform in dataset pipeline mode >>> waveform = np.random.random([5, 16, 8, 2]) # 5 samples >>> numpy_slices_dataset = ds.NumpySlicesDataset(data=waveform, column_names=["audio"]) >>> transforms = [audio.TimeStretch()] >>> numpy_slices_dataset = numpy_slices_dataset.map(operations=transforms, input_columns=["audio"]) >>> for item in numpy_slices_dataset.create_dict_iterator(num_epochs=1, output_numpy=True): ... print(item["audio"].shape, item["audio"].dtype) ... break (1, 16, 8, 2) float64 >>> >>> # Use the transform in eager mode >>> waveform = np.random.random([16, 8, 2]) # 1 sample >>> output = audio.TimeStretch()(waveform) >>> print(output.shape, output.dtype) (1, 16, 8, 2) float64
- 教程样例: