mindspore.dataset.Dataset.padded_batch
- Dataset.padded_batch(batch_size, drop_remainder=False, num_parallel_workers=None, pad_info=None)[source]
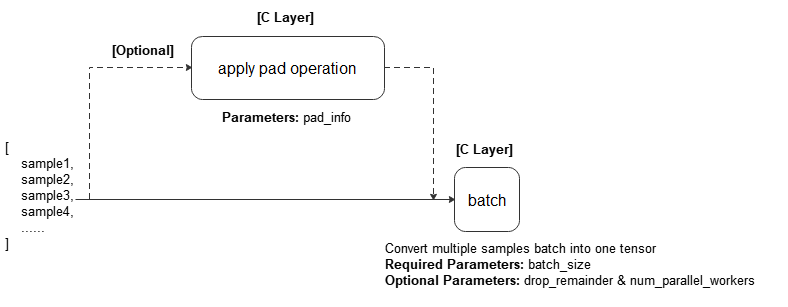
Combine batch_size number of consecutive rows into batch which apply pad_info to the samples first.
Refer to the following figure for the execution process:
Note
The order of using repeat and padded_batch reflects the number of batches. It is recommended that the repeat operation applied after the padded_batch operation finished.
- Parameters
batch_size (Union[int, Callable]) – The number of rows each batch is created with. An int or callable object which takes exactly 1 parameter, BatchInfo.
drop_remainder (bool, optional) – Determines whether or not to drop the last block whose data row number is less than batch size. Default: False. If True, and if there are less than batch_size rows available to make the last batch, then those rows will be dropped and not propagated to the child node.
num_parallel_workers (int, optional) – Number of workers(threads) to process the dataset in parallel. Default: None.
pad_info (dict, optional) – The information about how to batch each column. The key corresponds to the column name, and the value must be a tuple of 2 elements. The first element corresponds to the shape to pad to, and the second element corresponds to the value to pad with. If a column is not specified, then that column will be padded to the longest in the current batch, and 0 will be used as the padding value. Any None dimensions will be padded to the longest in the current batch, unless if pad_to_bucket_boundary is True. If no padding is wanted, set pad_info to None. Default: None.
- Returns
PaddedBatchDataset, dataset batched.
Examples
>>> # 1) Pad every sample to the largest sample's shape and batch the samples >>> dataset = dataset.padded_batch(100, True, pad_info={}) >>> >>> # 2) Create a dataset where every 100 rows are combined into a batch >>> # and drops the last incomplete batch if there is one. >>> dataset = dataset.padded_batch(100, True) >>> >>> # 3)Create a dataset where its batch size is dynamic >>> # Define a callable batch size function and let batch size increase 1 each time. >>> def add_one(BatchInfo): ... return BatchInfo.get_batch_num() + 1 >>> dataset = dataset.padded_batch(batch_size=add_one, drop_remainder=True)