mindspore.dataset.Dataset.bucket_batch_by_length
- Dataset.bucket_batch_by_length(column_names, bucket_boundaries, bucket_batch_sizes, element_length_function=None, pad_info=None, pad_to_bucket_boundary=False, drop_remainder=False)[source]
Bucket elements according to their lengths. Each bucket will be padded and batched when they are full.
A length function is called on each row in the dataset. The row is then bucketed based on its length and bucket boundaries. When a bucket reaches its corresponding size specified in bucket_batch_sizes, the entire bucket will be padded according to pad_info, and then form a batch.
Refer to the following figure for the execution process:
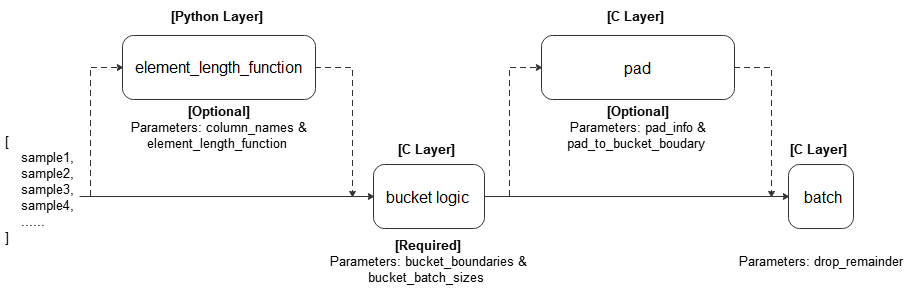
- Parameters
column_names (list[str]) – Columns passed to element_length_function.
bucket_boundaries (list[int]) – A list consisting of the upper boundaries of the buckets. Must be strictly increasing. If there are n boundaries, n+1 buckets are created: One bucket for [0, bucket_boundaries[0]), one bucket for [bucket_boundaries[i], bucket_boundaries[i+1]) for each 0<i<n-1, and the last bucket for [bucket_boundaries[n-1], inf).
bucket_batch_sizes (list[int]) – A list consisting of the batch sizes for each bucket. Must contain len(bucket_boundaries)+1 elements.
element_length_function (Callable, optional) – A function that takes in M arguments where M = len(column_names) and returns an integer. If no value provided, parameter M the len(column_names) must be 1, and the size of the first dimension of that column will be taken as the length. Default: None.
pad_info (dict, optional) – The information about how to batch each column. The key corresponds to the column name, and the value must be a tuple of 2 elements. The first element corresponds to the shape to pad to, and the second element corresponds to the value to pad with. If a column is not specified, then that column will be padded to the longest in the current batch, and 0 will be used as the padding value. Any None dimensions will be padded to the longest in the current batch, unless if pad_to_bucket_boundary is True. If no padding is wanted, set pad_info to None. Default: None.
pad_to_bucket_boundary (bool, optional) – If True, will pad each None dimension in pad_info to the bucket_boundary minus 1. If there are any elements that fall into the last bucket, an error will occur. Default: False.
drop_remainder (bool, optional) – If True, will drop the last batch for each bucket if it is not a full batch. Default: False.
- Returns
Dataset, dataset bucketed and batched by length.
Examples
>>> # Create a dataset where certain counts rows are combined into a batch >>> # and drops the last incomplete batch if there is one. >>> import numpy as np >>> def generate_2_columns(n): ... for i in range(n): ... yield (np.array([i]), np.array([j for j in range(i + 1)])) >>> >>> column_names = ["col1", "col2"] >>> dataset = ds.GeneratorDataset(generate_2_columns(8), column_names) >>> bucket_boundaries = [5, 10] >>> bucket_batch_sizes = [2, 1, 1] >>> element_length_function = (lambda col1, col2: max(len(col1), len(col2))) >>> # Will pad col2 to shape [bucket_boundaries[i]] where i is the >>> # index of the bucket that is currently being batched. >>> pad_info = {"col2": ([None], -1)} >>> pad_to_bucket_boundary = True >>> dataset = dataset.bucket_batch_by_length(column_names, bucket_boundaries, ... bucket_batch_sizes, ... element_length_function, pad_info, ... pad_to_bucket_boundary)