![]()
![]()
![]()
![]()
轻量化数据处理
在资源条件允许的情况下,为了追求更高的性能,一般使用Pipeline模式执行数据变换Transforms。
基于Pipeline模式执行的最大特点是需要使用map方法,如下图中将Resize、Crop、HWC2CHW交由map调度,由其负责启动和执行给定的Transform,对Pipeline的数据进行映射变换。

虽然构建数据管道可以批量处理输入数据,但是数据管道的API设计要求用户从构建输入源开始,逐步定义数据管道中的各个Transform,仅当在定义map的时候才会涉及与用户输入数据高度相关的Transform。
无疑,用户只想重点关注这些与其相关度最高的代码,但其他相关度较低的代码却在整个代码场景中为用户增加了不必要的负担。
因此,MindSpore提供了一种轻量化的数据处理执行方式,称为Eager模式。
在Eager模式下,执行Transforms不需要依赖构建数据管道map,而是以函数式调用的方式执行Transforms。因此代码编写会更为简洁且能立即执行得到运行结果,推荐在小型数据增强实验、模型推理等轻量化场景中使用。

MindSpore目前支持在Eager模式执行各种Transform,具体如下所示,更多数据变换接口参见API文档。
-
子模块transforms,基于OpenCV/Pillow实现的数据变换。
-
子模块transforms,基于Jieba/ICU4C等库实现的数据变换。
-
子模块transforms,基于C++/Python/NumPy实现的通用数据变换。
Eager模式
下面将简要介绍各Transforms模块的Eager模式使用方法。使用Eager模式,只需要将Transform本身当成可执行函数即可。
数据准备
以下示例代码将图片数据下载到指定位置。
[9]:
from download import download
url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/banana.jpg"
download(url, './banana.jpg', replace=True)
Downloading data from https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/banana.jpg (17 kB)
file_sizes: 100%|███████████████████████████| 17.1k/17.1k [00:00<00:00, 883kB/s]
Successfully downloaded file to ./banana.jpg
[9]:
'./banana.jpg'
vision
此示例将使用mindspore.dataset.vision模块中的Transform,对给定图像进行变换。
您仅需要关注使用何种数据变换,而不需要关注数据管道的任何代码。
Vision Transform的Eager模式支持numpy.array或PIL.Image类型的数据作为入参。
[10]:
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import mindspore.dataset.vision as vision
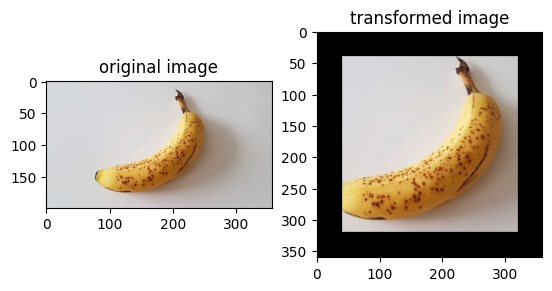
img_ori = Image.open("banana.jpg").convert("RGB")
print("Image.type: {}, Image.shape: {}".format(type(img_ori), img_ori.size))
# Define a Resize op and execute it immediately
op1 = vision.Resize(size=(320))
img = op1(img_ori)
print("Image.type: {}, Image.shape: {}".format(type(img), img.size))
# Define a CenterCrop op and execute it immediately
op2 = vision.CenterCrop((280, 280))
img = op2(img)
print("Image.type: {}, Image.shape: {}".format(type(img), img.size))
# Define a Pad op and execute it immediately
op3 = vision.Pad(40)
img = op3(img)
print("Image.type: {}, Image.shape: {}".format(type(img), img.size))
# Show the result
plt.subplot(1, 2, 1)
plt.imshow(img_ori)
plt.title("original image")
plt.subplot(1, 2, 2)
plt.imshow(img)
plt.title("transformed image")
plt.show()
Image.type: <class 'PIL.Image.Image'>, Image.shape: (356, 200)
Image.type: <class 'PIL.Image.Image'>, Image.shape: (569, 320)
Image.type: <class 'PIL.Image.Image'>, Image.shape: (280, 280)
Image.type: <class 'PIL.Image.Image'>, Image.shape: (360, 360)
text
此示例将使用text模块中Transforms,对给定文本进行变换。
Text Transforms的Eager模式支持numpy.array类型数据的作为入参。
[11]:
import mindspore.dataset.text.transforms as text
import mindspore as ms
# Define a WhitespaceTokenizer op and execute it immediately
txt = "Welcome to Beijing !"
txt = text.WhitespaceTokenizer()(txt)
print("Tokenize result: {}".format(txt))
# Define a ToNumber op and execute it immediately
txt = ["123456"]
to_number = text.ToNumber(ms.int32)
txt = to_number(txt)
print("ToNumber result: {}, type: {}".format(txt, type(txt[0])))
Tokenize result: ['Welcome' 'to' 'Beijing' '!']
ToNumber result: [123456], type: <class 'numpy.int32'>
transforms
此示例将使用transforms模块中通用Transform,对给定数据进行变换。
通用Transform的Eager模式支持numpy.array类型的数据作为入参。
[12]:
import numpy as np
import mindspore.dataset.transforms as trans
# Define a Fill op and execute it immediately
data = np.array([1, 2, 3, 4, 5])
fill = trans.Fill(0)
data = fill(data)
print("Fill result: ", data)
# Define a OneHot op and execute it immediately
label = np.array(2)
onehot = trans.OneHot(num_classes=5)
label = onehot(label)
print("OneHot result: ", label)
Fill result: [0 0 0 0 0]
OneHot result: [0 0 1 0 0]