快速入门:手写数字识别
![]()
![]()
![]()
本章节贯穿MindSpore深度学习的基本流程,以LeNet5网络模型为例子,实现深度学习中的常见任务。
下载并处理数据集
数据集对于模型训练非常重要,好的数据集可以有效提高训练精度和效率。示例中用到的MNIST数据集是由10类28∗28的灰度图片组成,训练数据集包含60000张图片,测试数据集包含10000张图片。

你可以从MNIST数据集下载页面下载,解压后按下方目录结构放置。
MindSpore Vision套件提供了用于下载并处理MNIST数据集的Mnist模块,以下示例代码将数据集下载、解压到指定位置并进行数据处理:
本章节中的示例代码依赖
mindvision,可使用命令pip install mindvision安装。如本文档以Notebook运行时,完成安装后需要重启kernel才能执行后续代码。
[1]:
from mindvision.dataset import Mnist
# 下载并处理MNIST数据集
download_train = Mnist(path="./mnist", split="train", batch_size=32, repeat_num=1, shuffle=True, resize=32, download=True)
download_eval = Mnist(path="./mnist", split="test", batch_size=32, resize=32, download=True)
dataset_train = download_train.run()
dataset_eval = download_eval.run()
参数说明:
path:数据集路径。
split:数据集类型,支持train、 test、infer,默认为train。
batch_size:每个训练批次设定的数据大小,默认为32。
repeat_num:训练时遍历数据集的次数,默认为1。
shuffle:是否需要将数据集随机打乱(可选参数)。
resize:输出图像的图像大小,默认为32*32。
download:是否需要下载数据集,默认为False。
下载的数据集文件的目录结构如下:
./mnist/
├── test
│ ├── t10k-images-idx3-ubyte
│ └── t10k-labels-idx1-ubyte
└── train
├── train-images-idx3-ubyte
└── train-labels-idx1-ubyte
创建模型
按照LeNet的网络结构,LeNet除去输入层共有7层,其中有2个卷积层,2个子采样层,3个全连接层。

下面是LeNet5网络模型的具体代码实现:
[1]:
import mindspore.nn as nn
class LeNet5(nn.Cell):
"""
LeNet-5网络结构
"""
def __init__(self, num_class=10, num_channel=1):
super(LeNet5, self).__init__()
# 卷积层,输入的通道数为num_channel,输出的通道数为6,卷积核大小为5*5
self.conv1 = nn.Conv2d(num_channel, 6, 5, pad_mode='valid')
# 卷积层,输入的通道数为6,输出的通道数为16,卷积核大小为5*5
self.conv2 = nn.Conv2d(6, 16, 5, pad_mode='valid')
# 全连接层,输入个数为16*5*5,输出个数为120
self.fc1 = nn.Dense(16 * 5 * 5, 120)
# 全连接层,输入个数为120,输出个数为84
self.fc2 = nn.Dense(120, 84)
# 全连接层,输入个数为84,分类的个数为num_class
self.fc3 = nn.Dense(84, num_class)
# ReLU激活函数
self.relu = nn.ReLU()
# 池化层
self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2)
# 多维数组展平为一维数组
self.flatten = nn.Flatten()
def construct(self, x):
# 使用定义好的运算构建前向网络
x = self.conv1(x)
x = self.relu(x)
x = self.max_pool2d(x)
x = self.conv2(x)
x = self.relu(x)
x = self.max_pool2d(x)
x = self.flatten(x)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x
network = LeNet5(num_class=10)
同时,MindSpore Vision套件提供了LeNet网络模型接口lenet, 定义网络模型如下:
[2]:
from mindvision.classification.models import lenet
network = lenet(num_classes=10, pretrained=False)
定义损失函数和优化器
要训练神经网络模型,需要定义损失函数和优化器函数。
损失函数这里使用交叉熵损失函数
SoftmaxCrossEntropyWithLogits。优化器这里使用
Momentum。
[3]:
import mindspore.nn as nn
# 定义损失函数
net_loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
# 定义优化器函数
net_opt = nn.Momentum(network.trainable_params(), learning_rate=0.01, momentum=0.9)
训练及保存模型
在开始训练之前,MindSpore需要提前声明网络模型在训练过程中是否需要保存中间过程和结果,因此使用ModelCheckpoint接口用于保存网络模型和参数,以便进行后续的Fine-tuning(微调)操作。
[4]:
import mindspore as ms
# 设置模型保存参数,模型训练保存参数的step为1875。
config_ck = ms.CheckpointConfig(save_checkpoint_steps=1875, keep_checkpoint_max=10)
# 应用模型保存参数
ckpoint = ms.ModelCheckpoint(prefix="lenet", directory="./lenet", config=config_ck)
通过MindSpore提供的model.train接口可以方便地进行网络的训练,LossMonitor可以监控训练过程中loss值的变化。
[5]:
from mindvision.engine.callback import LossMonitor
import mindspore as ms
# 初始化模型参数
model = ms.Model(network, loss_fn=net_loss, optimizer=net_opt, metrics={'accuracy'})
# 训练网络模型,并保存为lenet-1_1875.ckpt文件
model.train(10, dataset_train, callbacks=[ckpoint, LossMonitor(0.01, 1875)])
Epoch:[ 0/ 10], step:[ 1875/ 1875], loss:[0.314/0.314], time:2237.313 ms, lr:0.01000
Epoch time: 3577.754 ms, per step time: 1.908 ms, avg loss: 0.314
Epoch:[ 1/ 10], step:[ 1875/ 1875], loss:[0.031/0.031], time:1306.982 ms, lr:0.01000
Epoch time: 1307.792 ms, per step time: 0.697 ms, avg loss: 0.031
Epoch:[ 2/ 10], step:[ 1875/ 1875], loss:[0.007/0.007], time:1324.625 ms, lr:0.01000
Epoch time: 1325.340 ms, per step time: 0.707 ms, avg loss: 0.007
Epoch:[ 3/ 10], step:[ 1875/ 1875], loss:[0.021/0.021], time:1396.733 ms, lr:0.01000
Epoch time: 1397.495 ms, per step time: 0.745 ms, avg loss: 0.021
Epoch:[ 4/ 10], step:[ 1875/ 1875], loss:[0.028/0.028], time:1594.762 ms, lr:0.01000
Epoch time: 1595.549 ms, per step time: 0.851 ms, avg loss: 0.028
Epoch:[ 5/ 10], step:[ 1875/ 1875], loss:[0.007/0.007], time:1242.175 ms, lr:0.01000
Epoch time: 1242.928 ms, per step time: 0.663 ms, avg loss: 0.007
Epoch:[ 6/ 10], step:[ 1875/ 1875], loss:[0.033/0.033], time:1199.938 ms, lr:0.01000
Epoch time: 1200.627 ms, per step time: 0.640 ms, avg loss: 0.033
Epoch:[ 7/ 10], step:[ 1875/ 1875], loss:[0.175/0.175], time:1228.845 ms, lr:0.01000
Epoch time: 1229.548 ms, per step time: 0.656 ms, avg loss: 0.175
Epoch:[ 8/ 10], step:[ 1875/ 1875], loss:[0.009/0.009], time:1237.200 ms, lr:0.01000
Epoch time: 1237.969 ms, per step time: 0.660 ms, avg loss: 0.009
Epoch:[ 9/ 10], step:[ 1875/ 1875], loss:[0.000/0.000], time:1287.693 ms, lr:0.01000
Epoch time: 1288.413 ms, per step time: 0.687 ms, avg loss: 0.000
训练过程中会打印loss值,loss值会波动,但总体来说loss值会逐步减小,精度逐步提高。每个人运行的loss值有一定随机性,不一定完全相同。
通过模型运行测试数据集得到的结果,验证模型的泛化能力:
使用
model.eval接口读入测试数据集。使用保存后的模型参数进行推理。
[6]:
acc = model.eval(dataset_eval)
print("{}".format(acc))
{'accuracy': 0.9903846153846154}
可以在打印信息中看出模型精度数据,示例中精度数据达到95%以上,模型质量良好。随着网络迭代次数增加,模型精度会进一步提高。
加载模型
[7]:
import mindspore as ms
# 加载已经保存的用于测试的模型
param_dict = ms.load_checkpoint("./lenet/lenet-1_1875.ckpt")
# 加载参数到网络中
ms.load_param_into_net(network, param_dict)
[7]:
[]
阅读更多有关加载模型的信息。
验证模型
我们使用生成的模型进行单个图片数据的分类预测,具体步骤如下:
被预测的图片会随机生成,每次运行结果可能会不一样。
代码使用了Tensor模块,阅读更多有关张量Tensor的信息。
[9]:
import numpy as np
import mindspore as ms
import matplotlib.pyplot as plt
mnist = Mnist("./mnist", split="train", batch_size=6, resize=32)
dataset_infer = mnist.run()
ds_test = dataset_infer.create_dict_iterator()
data = next(ds_test)
images = data["image"].asnumpy()
labels = data["label"].asnumpy()
plt.figure()
for i in range(1, 7):
plt.subplot(2, 3, i)
plt.imshow(images[i-1][0], interpolation="None", cmap="gray")
plt.show()
# 使用函数model.predict预测image对应分类
output = model.predict(ms.Tensor(data['image']))
predicted = np.argmax(output.asnumpy(), axis=1)
# 输出预测分类与实际分类
print(f'Predicted: "{predicted}", Actual: "{labels}"')
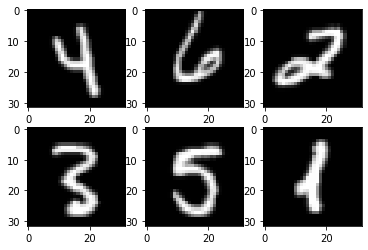
Predicted: "[4 6 2 3 5 1]", Actual: "[4 6 2 3 5 1]"
从上面的打印结果可以看出,预测值与目标值完全一致。