进阶案例:线性拟合
![]()
![]()
![]()
MindSpore向用户提供了高阶、中阶和低阶3个不同层次的API,详细内容参见基本介绍-层次结构内容章节。
为方便控制网络的执行流程,MindSpore提供了高阶的训练和推理接口mindspore.Model,通过指定要训练的神经网络模型和常见的训练设置,调用train和eval方法对网络进行训练和推理。同时,用户如果想要对特定模块进行个性化设置,也可以调用对应的中低阶接口自行定义网络的训练流程。
本章将使用MindSpore提供的中低阶API拟合线性函数:
本章将会介绍配置信息和使用MindSpore提供的中低阶API,实现自定义损失函数、优化器、训练流程、Metric、自定义验证流程模块。
配置信息
初始化网络之前,需要配置context参数,用于控制程序执行的策略,如配置静态图或动态图模式,配置网络运行的硬件环境等。本节主要介绍执行模式管理和硬件管理。
执行模式
MindSpore支持Graph和PyNative两种运行模式。Graph模式是MindSpore的默认模式,而PyNative模式用于调试等用途。
Graph模式(静态图模式):将神经网络模型编译成一整张图,然后下发到硬件执行。该模式利用图优化等技术提高运行性能,同时有助于规模部署和跨平台运行。
PyNative模式(动态图模式):将神经网络中的各个算子逐一下发到硬件中执行,该模式方便用户编写代码和调试神经网络模型。
MindSpore提供了静态图和动态图统一的编码方式,大大增加了静态图和动态图的可兼容性,用户无需开发多套代码,仅变更一行代码便可切换静态图/动态图模式。模式切换时,请留意目标模式的约束。
设置运行模式为动态图模式:
[1]:
import mindspore as ms
ms.set_context(mode=ms.PYNATIVE_MODE)
同样,MindSpore处于动态图模式时,可以通过set_context(mode=GRAPH_MODE)切换为静态图模式:
[2]:
import mindspore as ms
ms.set_context(mode=ms.GRAPH_MODE)
硬件管理
硬件管理部分主要包括device_target和device_id两个参数。
device_target: 待运行的目标设备,支持Ascend、GPU和CPU,可以根据实际环境情况设置,或者使用系统默认配置。device_id: 表示目标设备ID,其值在[0,device_num_per_host- 1]范围内,device_num_per_host表示服务器的总设备数量,device_num_per_host的值不能超过4096,device_id默认为0。
在非分布式模式执行的情况下,为了避免设备的使用冲突,可以通过设置
device_id决定程序执行的设备ID。
代码样例如下:
import mindspore as ms
ms.set_context(device_target="Ascend", device_id=6)
处理数据集
生成数据集
定义数据集生成函数 get_data ,生成训练数据集和测试数据集。
由于拟合的是线性数据,假定要拟合的目标函数为:\(f(x)=2x+3\),那么我们需要的训练数据集应随机分布于函数周边,这里采用了\(f(x)=2x+3+noise\)的方式生成,其中noise为遵循标准正态分布规律的随机数值。
[3]:
import numpy as np
def get_data(num, w=2.0, b=3.0):
for _ in range(num):
x = np.random.uniform(-10.0, 10.0)
noise = np.random.normal(0, 1)
y = x * w + b + noise
yield np.array([x]).astype(np.float32), np.array([y]).astype(np.float32)
使用get_data生成50组验证数据,并可视化。
[4]:
import matplotlib.pyplot as plt
train_data = list(get_data(50))
x_target_label = np.array([-10, 10, 0.1])
y_target_label = x_target_label * 2 + 3
x_eval_label, y_eval_label = zip(*train_data)
plt.scatter(x_eval_label, y_eval_label, color="red", s=5)
plt.plot(x_target_label, y_target_label, color="green")
plt.title("Eval data")
plt.show()
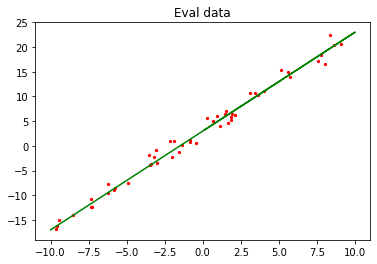
上图中绿色线条部分为目标函数,红点部分为验证数据train_data。
加载数据集
加载get_data函数所产生的数据集到系统内存里面,并进行基本的数据处理操作。
ds.GeneratorDataset:将生成的数据转换为MindSpore的数据集,并且将生成的数据的x,y值存入到data和label的数组中。batch:将batch_size个数据组合成一个batch。repeat:将数据集数量倍增。
[3]:
from mindspore import dataset as ds
def create_dataset(num_data, batch_size=16, repeat_size=1):
input_data = ds.GeneratorDataset(list(get_data(num_data)), column_names=['data', 'label'])
input_data = input_data.batch(batch_size, drop_remainder=True)
input_data = input_data.repeat(repeat_size)
return input_data
使用数据集增强函数生成训练数据,通过定义的create_dataset将生成的1600个数据增强为100组shape为16x1的数据集。
[4]:
data_number = 1600
batch_number = 16
repeat_number = 1
ds_train = create_dataset(data_number, batch_size=batch_number, repeat_size=repeat_number)
print("The dataset size of ds_train:", ds_train.get_dataset_size())
step_size = ds_train.get_dataset_size()
dict_datasets = next(ds_train.create_dict_iterator())
print(dict_datasets.keys())
print("The x label value shape:", dict_datasets["data"].shape)
print("The y label value shape:", dict_datasets["label"].shape)
The dataset size of ds_train: 100
dict_keys(['data', 'label'])
The x label value shape: (16, 1)
The y label value shape: (16, 1)
定义网络模型
mindspore.nn类是构建所有网络的基类,也是网络的基本单元。当用户需要自定义网络时,可以继承nn.Cell类,并重写__init__方法和construct方法。
mindspore.ops模块提供了基础算子的实现,nn.Cell模块实现了对基础算子的进一步封装,用户可以根据需要,灵活使用不同的算子。
如下示例使用nn.Cell构建一个简单的全连接网络,用于后续自定义内容的示例片段代码。在MindSpore中使用nn.Dense生成单个数据输入,单个数据输出的线性函数模型:
并使用Normal算子随机初始化公式 (2) 中的参数\(w\)和\(b\)。
[5]:
from mindspore import nn
from mindspore.common.initializer import Normal
class LinearNet(nn.Cell):
def __init__(self):
super(LinearNet, self).__init__()
self.fc = nn.Dense(1, 1, Normal(0.02), Normal(0.02))
def construct(self, x):
fx = self.fc(x)
return fx
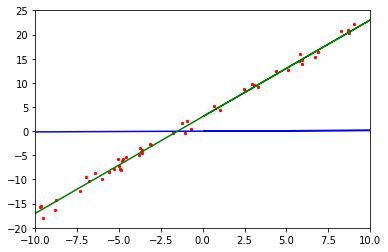
初始化网络模型后,接下来将初始化的网络函数和训练数据集进行可视化,了解拟合前的模型函数情况。
[6]:
import mindspore as ms
net = LinearNet() # 初始化线性回归网络
model_params = net.trainable_params() # 获取训练前的网络参数 w 和 b
x_model_label = np.array([-10, 10, 0.1])
y_model_label = (x_model_label * model_params[0].asnumpy()[0] + model_params[1].asnumpy()[0])
plt.axis([-10, 10, -20, 25])
plt.scatter(x_eval_label, y_eval_label, color="red", s=5)
plt.plot(x_model_label, y_model_label, color="blue")
plt.plot(x_target_label, y_target_label, color="green")
plt.show()
自定义损失函数
损失函数(Loss Function)用于衡量预测值与真实值差异的程度。深度学习中,模型训练就是通过不停地迭代来缩小损失函数值的过程,因此在模型训练过程中损失函数的选择非常重要,定义一个好的损失函数可以帮助损失函数值更快收敛,达到更好的精度。
mindspore.nn提供了许多通用损失函数供用户选择, 也支持用户根据需要自定义损失函数。
自定义损失函数类时,既可以继承网络的基类nn.Cell,也可以继承损失函数的基类nn.LossBase。nn.LossBase在nn.Cell的基础上,提供了get_loss方法,利用reduction参数对损失值求和或求均值,输出一个标量。下面将使用继承LossBase的方法来定义平均绝对误差损失函数(Mean Absolute Error,MAE),MAE算法的公式如下所示:
上式中\(f(x)\)为预测值,\(y\)为样本真实值,\(loss\)为预测值与真实值之间距离的平均值。
使用继承LossBase的方法来自定义损失函数时,需要重写__init__方法和construct方法,使用get_loss方法计算损失。示例代码如下:
[7]:
from mindspore import nn, ops
class MyMAELoss(nn.LossBase):
"""定义损失"""
def __init__(self):
super(MyMAELoss, self).__init__()
self.abs = ops.Abs()
def construct(self, predict, target):
x = self.abs(target - predict)
return self.get_loss(x)
自定义优化器
优化器在模型训练过程中,用于计算和更新网络参数,合适的优化器可以有效减少训练时间,提高模型性能。
mindspore.nn提供了许多通用的优化器供用户选择,同时也支持用户根据需要自定义优化器。
自定义优化器时可以继承优化器基类nn.Optimizer,重写__init__方法和construct方法实现参数的更新。
如下示例实现自定义优化器Momentum(带动量的SGD算法):
其中,\(grad\) 、\(lr\) 、\(p\) 、\(v\) 和 \(u\) 分别表示梯度、学习率、权重参数、动量参数(Momentum)和初始速度。
[8]:
import mindspore as ms
from mindspore import nn, ops
class MyMomentum(nn.Optimizer):
"""定义优化器"""
def __init__(self, params, learning_rate, momentum=0.9):
super(MyMomentum, self).__init__(learning_rate, params)
self.moment = ms.Parameter(ms.Tensor(momentum, ms.float32), name="moment")
self.momentum = self.parameters.clone(prefix="momentum", init="zeros")
self.assign = ops.Assign()
def construct(self, gradients):
"""construct输入为梯度,在训练中自动传入梯度gradients"""
lr = self.get_lr()
params = self.parameters # 待更新的权重参数
for i in range(len(params)):
self.assign(self.momentum[i], self.momentum[i] * self.moment + gradients[i])
update = params[i] - self.momentum[i] * lr # 带有动量的SGD算法
self.assign(params[i], update)
return params
自定义训练流程
mindspore.Model提供了train和eval的接口方便用户在训练过程中使用,但此接口无法适用于所有场景,比如多数据多标签场景,在这些场景下用户需自行定义训练过程。
本节主要使用线性回归的例子来简单介绍自定义训练流程。首先定义损失网络,将前向网络与损失函数连接起来;然后定义训练流程,训练流程一般继承nn.TrainOneStepCell,nn.TrainOneStepCell封装了损失网络和优化器,用来实现反向传播网络以更新权重参数。
定义损失网络
定义损失网络MyWithLossCell,将前向网络与损失函数连接起来。
[9]:
class MyWithLossCell(nn.Cell):
"""定义损失网络"""
def __init__(self, backbone, loss_fn):
"""实例化时传入前向网络和损失函数作为参数"""
super(MyWithLossCell, self).__init__(auto_prefix=False)
self.backbone = backbone
self.loss_fn = loss_fn
def construct(self, data, label):
"""连接前向网络和损失函数"""
out = self.backbone(data)
return self.loss_fn(out, label)
def backbone_network(self):
"""要封装的骨干网络"""
return self.backbone
定义训练流程
定义训练流程MyTrainStep,该类继承nn.TrainOneStepCell,nn.TrainOneStepCell封装了损失网络和优化器,在执行训练时通过ops.GradOperation算子来进行梯度的获取,通过优化器来实现权重的更新。
[10]:
class MyTrainStep(nn.TrainOneStepCell):
"""定义训练流程"""
def __init__(self, network, optimizer):
"""参数初始化"""
super(MyTrainStep, self).__init__(network, optimizer)
self.grad = ops.GradOperation(get_by_list=True)
def construct(self, data, label):
"""构建训练过程"""
weights = self.weights
loss = self.network(data, label)
grads = self.grad(self.network, weights)(data, label)
return loss, self.optimizer(grads)
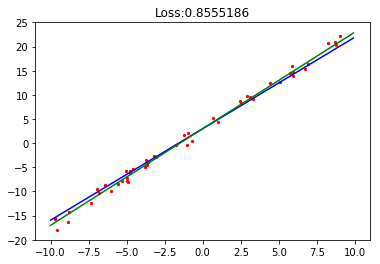
下面定义绘图函数plot_model_and_datasets来绘制测试数据、目标函数和网络模型拟合函数,并查看损失值。
[11]:
from IPython import display
import matplotlib.pyplot as plt
import time
def plot_model_and_datasets(net, data, loss):
weight = net.trainable_params()[0]
bias = net.trainable_params()[1]
x = np.arange(-10, 10, 0.1)
y = x * ms.Tensor(weight).asnumpy()[0][0] + ms.Tensor(bias).asnumpy()[0]
x1, y1 = zip(*data)
x_target = x
y_target = x_target * 2 + 3
plt.axis([-11, 11, -20, 25])
plt.scatter(x1, y1, color="red", s=5) # 原始数据
plt.plot(x, y, color="blue") # 预测数据
plt.plot(x_target, y_target, color="green") # 拟合函数
plt.title(f"Loss:{loss}") # 打印损失值
plt.show()
time.sleep(0.2)
display.clear_output(wait=True)
执行训练
使用训练数据ds_train对训练网络train_net进行训练,并可视化训练过程。
[12]:
loss_func = MyMAELoss() # 损失函数
opt = MyMomentum(net.trainable_params(), 0.01) # 优化器
net_with_criterion = MyWithLossCell(net, loss_func) # 构建损失网络
train_net = MyTrainStep(net_with_criterion, opt) # 构建训练网络
for data in ds_train.create_dict_iterator():
train_net(data['data'], data['label']) # 执行训练,并更新权重
loss = net_with_criterion(data['data'], data['label']) # 计算损失值
plot_model_and_datasets(train_net, train_data, loss) # 可视化训练过程
自定义评价指标
当训练任务结束,常常需要评价指标(Metrics)评估函数来评估模型的好坏。常用的评价指标有混淆矩阵、准确率 Accuracy、精确率 Precision、召回率 Recall等。
mindspore.nn模块提供了常见的评估函数,用户也可以根据需要自行定义评估指标。自定义Metrics函数需要继承nn.Metric父类,并重新实现父类中的clear方法、update方法和eval方法。平均绝对误差(MAE)算法如下式所示,下面以简单的MAE为例,介绍这三个函数及其使用方法。
clear:初始化相关的内部参数。update:接收网络预测输出和标签,计算误差,并更新内部评估结果。一般在每个step后进行计算,并更新统计值。eval:计算最终评估结果,一般在一个epoch结束后计算最终的评估结果。
[13]:
class MyMAE(nn.Metric):
"""定义metric"""
def __init__(self):
super(MyMAE, self).__init__()
self.clear()
def clear(self):
"""初始化变量abs_error_sum和samples_num"""
self.abs_error_sum = 0
self.samples_num = 0
def update(self, *inputs):
"""更新abs_error_sum和samples_num"""
y_pred = inputs[0].asnumpy()
y = inputs[1].asnumpy()
# 计算预测值与真实值的绝对误差
error_abs = np.abs(y.reshape(y_pred.shape) - y_pred)
self.abs_error_sum += error_abs.sum()
self.samples_num += y.shape[0] # 样本的总数
def eval(self):
"""计算最终评估结果"""
return self.abs_error_sum / self.samples_num
自定义验证流程
mindspore.nn模块提供了评估网络包装函数nn.WithEvalCell,由于nn.WithEvalCell只有两个输入data和label,不适用于多数据或多标签的场景,所以需要自定义评估网络。多标签场景下自定义评估网络可参考自定义评估与训练章节。
如下示例实现简单的自定义评估网络MyWithEvalCell,输入传入数据data和标签label:
[14]:
class MyWithEvalCell(nn.Cell):
"""定义验证流程"""
def __init__(self, network):
super(MyWithEvalCell, self).__init__(auto_prefix=False)
self.network = network
def construct(self, data, label):
outputs = self.network(data)
return outputs, label
执行推理并评估:
[15]:
data_number = 160
batch_number = 16
repeat_number = 1
# 获取验证数据
ds_eval = create_dataset(data_number, batch_size=batch_number, repeat_size=repeat_number)
eval_net = MyWithEvalCell(net) # 定义评估网络
eval_net.set_train(False)
mae = MyMAE()
# 执行推理过程
for data in ds_eval.create_dict_iterator():
output, eval_y = eval_net(data['data'], data['label'])
mae.update(output, eval_y)
mae_result = mae.eval()
print("MAE: ", mae_result)
MAE: 0.9605088472366333
输出评估误差,MAE与模型在训练集上效果大致相同。
保存及导出模型
将上述训练好的模型参数保存到CheckPoint(简称ckpt)文件中,然后将CheckPoint文件导出为MindIR格式文件用于跨平台推理使用。
[16]:
import numpy as np
import mindspore as ms
ms.save_checkpoint(net, "./linear.ckpt") # 将模型参数保存在ckpt文件
param_dict = ms.load_checkpoint("./linear.ckpt") # 将模型参数存入param_dict字典中
# 查看模型参数
for param in param_dict:
print(param, ":", param_dict[param].asnumpy())
net1 = LinearNet()
input_np = np.random.uniform(0.0, 1.0, size=[1, 1]).astype(np.float32)
ms.export(net1, ms.Tensor(input_np), file_name='linear', file_format='MINDIR')
fc.weight : [[1.894384]]
fc.bias : [3.0015702]