图像数据加载与增强
![]()
![]()
![]()
![]()
在计算机视觉任务中,数据量过小、样本场景单一等问题都会影响模型的训练效果,用户可以通过数据增强操作对图像进行预处理,从而提升模型的泛化性。MindSpore提供了c_transforms模块和py_transforms模块供用户进行多种数据增强操作,二者的区别如下,用户也可以自定义函数或者算子进行数据增强。
c_transforms:基于C++的OpenCV实现,提供了多种图像增强功能,具有较高的性能;py_transforms:基于Python的PIL实现,提供了多种图像增强功能,并提供了PIL Image和NumPy数组之间的传输方法。
下面将以CIFAR-10数据集和MNIST数据集为例,简要介绍这两种图像数据加载的方式和几种常用的c_transforms模块和py_transforms模块数据增强算子的使用方法,更多图像类型的数据集加载方式可参考API文档,更多图像数据增强算子相关信息可参考API文档。
加载图像数据
以下示例代码分别将CIFAR-10数据集和MNIST数据集下载并解压到指定位置,网络状况良好的情况下此段代码预计需执行三至五分钟。
[1]:
import os
from mindvision.dataset import DownLoad
dl_path_cifar10 = "./datasets"
dl_url_cifar10 = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/cifar-10-binary.tar.gz"
dl = DownLoad()
# 下载CIFAR-10数据集并解压
dl.download_and_extract_archive(url=dl_url_cifar10, download_path=dl_path_cifar10)
# MNIST数据集保存路径
dl_path_mnist = "./mnist"
dl_url_mnist_labels = "http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz"
dl_url_mnist_images = "http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz"
# 下载MNIST数据集并解压
dl.download_and_extract_archive(url=dl_url_mnist_labels, download_path=dl_path_mnist)
dl.download_and_extract_archive(url=dl_url_mnist_images, download_path=dl_path_mnist)
image_gz = "./mnist/train-images-idx3-ubyte.gz"
label_gz = "./mnist/train-labels-idx1-ubyte.gz"
# 删除压缩文件
if os.path.exists(image_gz):
os.remove(image_gz)
if os.path.exists(label_gz):
os.remove(label_gz)
使用mindspore.dataset.Cifar10Dataset接口加载CIFAR-10数据集,使用mindspore.dataset.MnistDataset接口加载MNIST数据集。示例代码如下:
[2]:
import matplotlib.pyplot as plt
import mindspore.dataset as ds
%matplotlib inline
DATA_DIR_MNIST = "./mnist/"
DATA_DIR_CIFAR10 = "./datasets/cifar-10-batches-bin/"
# 加载数据集,选取4张图片
dataset_cifar10 = ds.Cifar10Dataset(DATA_DIR_CIFAR10, num_samples=4)
dataset_mnist = ds.MnistDataset(DATA_DIR_MNIST, num_samples=4)
def printDataset(dataset_list, name_list):
"""显示数据集"""
dataset_sizes = []
for dataset in dataset_list:
dataset_sizes.append(dataset.get_dataset_size())
row = len(dataset_list) # 画布行数
column = max(dataset_sizes) # 画布列数
pos = 1
for i in range(row):
for data in dataset_list[i].create_dict_iterator(output_numpy=True):
plt.subplot(row, column, pos) # 显示位置
plt.imshow(data['image'].squeeze(), cmap=plt.cm.gray) # 显示内容
plt.title(data['label']) # 显示标题
print(name_list[i], " shape:", data['image'].shape, "label:", data['label'])
pos = pos + 1
pos = column * (i + 1) + 1
printDataset([dataset_cifar10, dataset_mnist], ["CIFAR-10", "MNIST"])
CIFAR-10 shape: (32, 32, 3) label: 4
CIFAR-10 shape: (32, 32, 3) label: 5
CIFAR-10 shape: (32, 32, 3) label: 7
CIFAR-10 shape: (32, 32, 3) label: 2
MNIST shape: (28, 28, 1) label: 0
MNIST shape: (28, 28, 1) label: 3
MNIST shape: (28, 28, 1) label: 8
MNIST shape: (28, 28, 1) label: 9

c_transforms模块
c_transforms是基于C++的OpenCV实现,提供了多种图像增强功能,具有较高的性能。
RandomCrop
RandomCrop操作对输入图像进行在随机位置的裁剪。
参数说明:
size:裁剪图像的尺寸。padding:填充的像素数量。pad_if_needed:原图小于裁剪尺寸时,是否需要填充。fill_value:在常量填充模式时使用的填充值。padding_mode:填充模式。
下面的样例首先使用顺序采样器加载CIFAR-10数据集,然后对已加载的图片进行长宽均为10的随机裁剪,最后输出裁剪前后的图片形状及对应标签,并对图片进行了展示。
[3]:
import matplotlib.pyplot as plt
import mindspore.dataset as ds
import mindspore.dataset.vision.c_transforms as c_trans
ds.config.set_seed(1)
# CIFAR-10数据集加载路径
DATA_DIR = "./datasets/cifar-10-batches-bin/"
# 使用SequentialSampler采样器选取3张图片
sampler = ds.SequentialSampler(num_samples=3)
dataset1 = ds.Cifar10Dataset(DATA_DIR, sampler=sampler)
# 使用RandomCrop对原图进行10*10随机裁剪操作
random_crop = c_trans.RandomCrop([10, 10])
dataset2 = dataset1.map(operations=random_crop, input_columns=["image"])
printDataset([dataset1, dataset2], ["Source image", "Cropped image"])
Source image shape: (32, 32, 3) label: 6
Source image shape: (32, 32, 3) label: 9
Source image shape: (32, 32, 3) label: 9
Cropped image shape: (10, 10, 3) label: 6
Cropped image shape: (10, 10, 3) label: 9
Cropped image shape: (10, 10, 3) label: 9

从上面的打印和图片显示结果可以看出,图片随机裁剪前后,标签不变,形状发生了变化。裁剪前的图片分辨率为32×32,裁剪后为10×10。
RandomHorizontalFlip
RandomHorizontalFlip操作对输入图像进行随机水平翻转。
参数说明:
prob: 单张图片发生翻转的概率。
下面的样例首先使用随机采样器加载CIFAR-10数据集,然后对已加载的图片进行概率为0.8的随机水平翻转,最后输出翻转前后的图片形状及对应标签,并对图片进行了展示。
[4]:
import matplotlib.pyplot as plt
import mindspore.dataset as ds
import mindspore.dataset.vision.c_transforms as c_trans
ds.config.set_seed(1)
# CIFAR-10数据集加载路径
DATA_DIR = "./datasets/cifar-10-batches-bin/"
# 使用RandomSampler采样器随机选取4张图片
sampler = ds.RandomSampler(num_samples=4)
dataset1 = ds.Cifar10Dataset(DATA_DIR, sampler=sampler)
# 使用RandomHorizontalFlip对原图进行随机水平翻转
random_horizontal_flip = c_trans.RandomHorizontalFlip(prob=0.8)
dataset2 = dataset1.map(operations=random_horizontal_flip, input_columns=["image"])
printDataset([dataset1, dataset2], ["Source image", "Flipped image"])
Source image shape: (32, 32, 3) label: 7
Source image shape: (32, 32, 3) label: 8
Source image shape: (32, 32, 3) label: 2
Source image shape: (32, 32, 3) label: 9
Flipped image shape: (32, 32, 3) label: 7
Flipped image shape: (32, 32, 3) label: 8
Flipped image shape: (32, 32, 3) label: 2
Flipped image shape: (32, 32, 3) label: 9

从上面的打印和图片显示结果可以看出,经过随机水平翻转操作后,图像的形状、标签均未发生变化,部分图片被水平翻转。
Resize
Resize操作对输入图像进行缩放。
参数说明:
size:缩放的目标大小。interpolation:缩放时采用的插值方式。
下面的样例首先加载MNIST数据集[2],然后将已加载的图片缩放至(101, 101)大小,最后输出缩放前后的图片形状及对应标签,并对图片进行了展示。
[5]:
import matplotlib.pyplot as plt
import mindspore.dataset as ds
import mindspore.dataset.vision.c_transforms as c_trans
# MNIST数据集加载路径
DATA_DIR = "./mnist/"
# 加载MNIST数据集,选取4张图片
dataset1 = ds.MnistDataset(DATA_DIR, num_samples=4, shuffle=False)
# 使用Resize操作对图像进行101×101缩放
resize = c_trans.Resize(size=[101, 101])
dataset2 = dataset1.map(operations=resize, input_columns=["image"])
printDataset([dataset1, dataset2], ["Source image", "Resized image"])
Source image shape: (28, 28, 1) label: 5
Source image shape: (28, 28, 1) label: 0
Source image shape: (28, 28, 1) label: 4
Source image shape: (28, 28, 1) label: 1
Resized image shape: (101, 101, 1) label: 5
Resized image shape: (101, 101, 1) label: 0
Resized image shape: (101, 101, 1) label: 4
Resized image shape: (101, 101, 1) label: 1
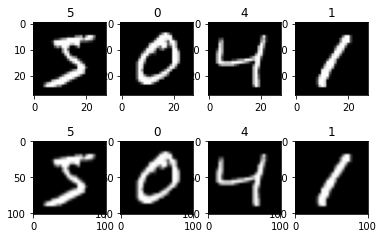
从上面的打印和图片显示结果可以看出,缩放前后,图片的形状发生了变化,标签未变。缩放前图片分辨率为28×28,缩放后,图片分辨率为101×101。
Invert
Invert操作对输入图像进行反相处理。
下面的样例首先加载CIFAR-10数据集,然后定义反相操作并作用于已加载的图片,最后输出反相前后的图片形状和标签,并对图片进行展示。
[6]:
import matplotlib.pyplot as plt
import mindspore.dataset as ds
import mindspore.dataset.vision.c_transforms as c_trans
ds.config.set_seed(18)
# CIFAR-10数据集加载路径
DATA_DIR = "./datasets/cifar-10-batches-bin/"
# 加载CIFAR-10数据集,选取4张图片
dataset1 = ds.Cifar10Dataset(DATA_DIR, num_samples=4, shuffle=True)
# 对图片进行反相操作
invert = c_trans.Invert()
dataset2 = dataset1.map(operations=invert, input_columns=["image"])
printDataset([dataset1, dataset2], ["Source image", "Inverted image"])
Source image shape: (32, 32, 3) label: 8
Source image shape: (32, 32, 3) label: 1
Source image shape: (32, 32, 3) label: 9
Source image shape: (32, 32, 3) label: 7
Inverted image shape: (32, 32, 3) label: 8
Inverted image shape: (32, 32, 3) label: 1
Inverted image shape: (32, 32, 3) label: 9
Inverted image shape: (32, 32, 3) label: 7

从上面的打印和图片显示结果可以看出,反相操作前后,图片的形状和标签未变,颜色发生了变化。
py_transforms模块
Compose
Compose操作接收一个transforms列表,将列表中的数据增强操作依次作用于数据集图片。
下面的样例首先加载CIFAR-10数据集[1],然后同时定义解码、缩放和数据类型转换操作,并作用于已加载的图片,最后输出处理后的图片形状及对应标签,并对图片进行展示。
[7]:
import matplotlib.pyplot as plt
import mindspore.dataset as ds
import mindspore.dataset.vision.py_transforms as py_trans
from mindspore.dataset.transforms.py_transforms import Compose
from PIL import Image
%matplotlib inline
ds.config.set_seed(8)
# CIFAR-10数据集加载路径
DATA_DIR = "./datasets/cifar-10-batches-bin/"
# 加载CIFAR-10数据集,选取5张图片
dataset1 = ds.Cifar10Dataset(DATA_DIR, num_samples=5, shuffle=True)
def decode(image):
"""定义解码函数"""
return Image.fromarray(image)
# 定义transforms列表
transforms_list = [
decode,
py_trans.Resize(size=(200, 200)),
py_trans.ToTensor()
]
# 通过Compose操作将transforms列表中函数作用于数据集图片
compose_trans = Compose(transforms_list)
dataset2 = dataset1.map(operations=compose_trans, input_columns=["image"])
# 打印数据增强操作后图片的形状、标签
image_list, label_list = [], []
for data in dataset2.create_dict_iterator():
image_list.append(data['image'])
label_list.append(data['label'])
print("Transformed image Shape:", data['image'].shape, ", Transformed label:", data['label'])
num_samples = len(image_list)
for i in range(num_samples):
plt.subplot(1, len(image_list), i + 1)
plt.imshow(image_list[i].asnumpy().transpose(1, 2, 0))
plt.title(label_list[i].asnumpy())
Transformed image Shape: (3, 200, 200) , Transformed label: 4
Transformed image Shape: (3, 200, 200) , Transformed label: 9
Transformed image Shape: (3, 200, 200) , Transformed label: 6
Transformed image Shape: (3, 200, 200) , Transformed label: 5
Transformed image Shape: (3, 200, 200) , Transformed label: 7

从上面的打印和图片显示结果可以看出,经过transforms列表中的数据增强操作后,图片标签未变,形状发生了变化,分辨率缩放为200×200。
注意事项
在数据管道处理模式中,请谨慎混用c_transforms与py_transforms,因为两者在数据的计算管道(即Pipeline)中运行的方式存在差异。
混用会引发C++与Python切换的成本,从而降低处理性能,因此建议尽量不要过度混用两个模块的算子。
注:Eager模式混用
c_transforms与py_transforms不受运行方式差异影响
推荐的使用方式
优先推荐单独使用
py_transform或c_transform。如下图所示,不存在Python层和C++层切换使用的情况。
先使用
py_transform,再使用c_transform。如下图所示,先完成Python层的操作后,再完成C++层的操作。
先使用
c_transform,再使用py_transform。如下图所示,先完成C++层的操作后,再完成Python层的操作。
不推荐的使用方式
在两种transform之间频繁切换。如下图所示,这种在Python层和C++层来回切换的使用方式是极不推荐的。

参考文献
[1] Alex Krizhevsky. Learning_Multiple Layers of Features from Tiny Images.
[2] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner. Gradient-based learning applied to document recognition.
本章节中的示例代码依赖第三方支持包
matplotlib,可使用命令pip install matplotlib安装。如本文档以Notebook运行时,完成安装后需要重启kernel才能执行后续代码。