Optimizer Parallel
![]()
Overview
When performing data parallel training, the parameter update part of the model is computed redundantly across cards. Optimizer parallelism can effectively reduce memory consumption and improve network performance on large-scale networks (e.g., Bert, GPT) by spreading the computation of the optimizer to the cards of the data parallel dimension.
In AUTO_PARALLEL or SEMI_AUTO_PARALLEL mode to enable optimizer parallelism, if the parameters after slicing strategy have duplicate slices between machines and the highest dimension of the shape is divisible by the cardinality of the duplicate slices, the framework saves the parameters as minimal slices and updates them in the optimizer. All optimizers are supported in this mode.
Parallel mode |
Parameter update mode |
Optimizer support |
Backend support |
|---|---|---|---|
Automatic/semi-automatic parallel |
The parameters are sliced into N copies according to data parallelism, and each card updates the parameters on the current card |
all optimizers |
Ascend, GPU |
In either mode, the optimizer parallelism does not affect the compute graph of the original forward and backward network, but only the compute volume and compute logic of the parameter updates.
Hardware platforms supported by the optimizer parallel model include Ascend, GPU, and need to be run in Graph mode.
Related interfaces:
mindspore.set_auto_parallel_context(parallel_mode=ParallelMode.SEMI_AUTO_PARALLEL, enable_parallel_optimizer=True): Set semi-automatic parallel mode and enable optimizer parallel, must be called before initializing the network. Whenenable_parallel_optimizeris turned on, the optimizer slices by default for all parameters occupying no less than 64KB of memory. See Advanced Interfaces in this chapter.Cell.set_comm_fusion(fusion_type=NUM): In automatic/semi-automatic mode, each parameter generates a corresponding AllGather operation and ReduceScatter operation. These communication operators are automatically inserted by the auto-parallel framework. However, as the number of parameters increases, the number of corresponding communication operators also increases, and the scheduling and startup of operators generated by communication operations incurs more overhead. Therefore, it is possible to manually configure fusion markers NUM for the AllGather and ReduceScatter operations corresponding to parameters within eachCellthrough theset_comm_fusionmethod provided byCellin order to improve communication efficiency. MindSpore will fuse the communication operators corresponding to the same NUM parameters to minimize communication overhead.
Basic Principles
The traditional data parallel model keeps copies of the model parameters on each device, slices the training data, synchronizes the gradient information after each iteration by using communication operators, and finally updates the parameters through optimizer calculations. Data parallelism, while effective in improving training throughput, does not maximize the use of machine resources. The optimizer introduces redundant memory and computation, eliminating these redundancies is an optimization point to focus on.
In a training iteration, the data parallelism introduces a communication operation to synchronize the gradients across multiple cards to collect the parameter gradients generated by the different samples on each card. Because the model parallelism is not involved, the optimizer operations on each card are actually updated based on the same parameters and in the same direction. The fundamental idea of eliminating optimizer redundancy is to spread this memory and computation across the cards to achieve memory and performance gains.
If you want to implement parallel computing for the optimizer, there are two implementation ideas, weights grouping and weights sharding. One of the weights grouping is to do inter-layer division of the parameters and gradients within the optimizer, and the general training flow is shown in Figure 1. The parameters and gradients are grouped onto different cards to be updated, and then the updated weights are shared among devices through a communication broadcast operation. The memory and performance gains of the solution depend on the group with the largest proportion of parameters. When the parameters are divided evenly, the theoretical positive gains are N-1/N of optimizer runtime and dynamic memory, and N-1/N of memory size for optimizer state parameters, where N denotes the number of devices. And the negative gain introduced is the communication time that comes when sharing network weights.
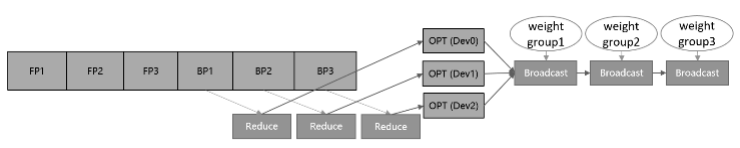
Figure 1: Schematic diagram of the parameter grouping training process
Another way to implement parameter slicing is to do intra-layer division of parameters, and take the corresponding slice for each parameter and gradient according to the device number. After updating the parameters and gradients, the communication aggregation operation is called to share the parameters among devices. The advantage of this scheme is that it naturally supports load balancing, i.e., the number of parameters and computations are consistent on each card, and the disadvantage is that the shape of the parameter requires to be divisible by the number of devices. The theoretical gains of this scheme are consistent with the parameter grouping, and the following improvements are made to the framework in order to extend the advantages.
First, slice the weights in the network can further reduce static memory. However, this also requires performing the shared weight operation at the end of the iteration before the forward start of the next iteration, ensuring that the original tensor shape remains the same after going into the forward and backward operations. In addition, the main negative gain from the parallel operation of the optimizer is the communication time of the shared weights, which can bring a performance gain if we can reduce or hide it. One advantage of communication cross-iteration execution is that communication operations can be executed interleaved with the forward network by fusing the communication operators in appropriate groups, thus hiding the communication time consumption as much as possible. The communication time consumption is also related to the communication volume. For the network involving mixed precision, if we can use fp16 communication, the communication volume will be reduced by half compared to fp32. Combining the above characteristics, the implementation scheme of parameter slicing is shown in Figure 2.
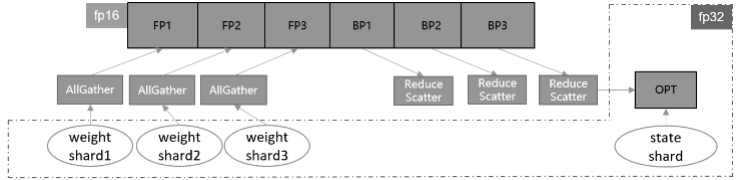
Figure 2: Schematic diagram of the parameter slicing training process
In the test validation of the actual network training, we found that the memory gain from parameter slicing is significant. In particular, for large-scale network models, the popular Adaptive Moment estimation (Adam) and Layer-wise Adaptive Moments optimizer for Batching training (LAMB) are usually chosen to train the network, and the number of parameters and computations of the optimizer itself should not be neglected. After parameter grouping, the weight parameters in the network and the two copies of state parameters in the optimizer are reduced by a factor of N-1/N, which greatly saves the static memory. This provides the possibility to increase the number of samples in a single iteration and improve the overall training throughput, which effectively solves the memory pressure of large-scale network training.
Optimizer parameter slicing implemented by MindSpore also has the advantage of being mixed with operator-level parallelism. When the number of sliced parts in the operator-level model parallel parameters are smaller than the number of dimensions, the optimizer parameters can continue to be sliced in the dimension of data parallelism, increasing the utilization of machine resources and thus improving the end-to-end performance.
Operation Practice
The following is an illustration of optimizer parallel operation using an Ascend or GPU single-machine 8-card example:
Sample Code Description
Download the full sample code: distributed_optimizer_parallel.
The directory structure is as follows:
└─ sample_code
├─ distributed_optimizer_parallel
├── distributed_optimizer_parallel.py
└── run.sh
...
Among them, distributed_optimizer_parallel.py is the script that defines the network structure and the training process. run.sh is the execution script.
Configuring the Distributed Environment
Specify the run mode, run device, run card number through the context interface. Unlike single-card scripts, parallel scripts also need to specify the parallel mode parallel_mode to be semi-automatic parallel mode, and initialize HCCL or NCCL communication through init. In addition, optimizer parallel should be turned on, configuring enable_parallel_optimizer=True. If device_target is not set here, it will be automatically specified as the backend hardware device corresponding to the MindSpore package.
import mindspore as ms
from mindspore.communication import init
ms.set_context(mode=ms.GRAPH_MODE)
ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.SEMI_AUTO_PARALLEL, enable_parallel_optimizer=True)
init()
ms.set_seed(1)
Loading the Dataset
In the optimizer parallel scenario, the dataset is loaded in the same way as single-card is loaded, with the following code:
import os
import mindspore.dataset as ds
def create_dataset(batch_size):
"""create dataset"""
dataset_path = os.getenv("DATA_PATH")
dataset = ds.MnistDataset(dataset_path)
image_transforms = [
ds.vision.Rescale(1.0 / 255.0, 0),
ds.vision.Normalize(mean=(0.1307,), std=(0.3081,)),
ds.vision.HWC2CHW()
]
label_transform = ds.transforms.TypeCast(ms.int32)
dataset = dataset.map(image_transforms, 'image')
dataset = dataset.map(label_transform, 'label')
dataset = dataset.batch(batch_size)
return dataset
data_set = create_dataset(32)
Defining the Network
The optimizer parallel network structure is essentially the same as the single card network structure, with the difference being the addition of a configuration for communication operator fusion:
from mindspore import nn
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.layer1 = nn.Dense(28*28, 512)
self.layer2 = nn.Dense(512, 512)
self.layer3 = nn.Dense(512, 10)
self.relu = nn.ReLU()
def construct(self, x):
x = self.flatten(x)
x = self.layer1(x)
x = self.relu(x)
x = self.layer2(x)
x = self.relu(x)
logits = self.layer3(x)
return logits
net = Network()
net.layer1.set_comm_fusion(0)
net.layer2.set_comm_fusion(1)
net.layer3.set_comm_fusion(2)
Here communication fusion is configured for different layers in order to reduce the communication cost. Details can be found in Communication Operator Fusion.
Training the Network
In this step, we need to define the loss function, the optimizer, and the training process, which is the same as that of the single-card:
import mindspore as ms
from mindspore import nn
optimizer = nn.SGD(net.trainable_params(), 1e-2)
loss_fn = nn.CrossEntropyLoss()
def forward_fn(data, target):
logits = net(data)
loss = loss_fn(logits, target)
return loss, logits
grad_fn = ms.value_and_grad(forward_fn, None, net.trainable_params(), has_aux=True)
@ms.jit
def train_step(inputs, targets):
(loss_value, _), grads = grad_fn(inputs, targets)
optimizer(grads)
return loss_value
for epoch in range(10):
i = 0
for image, label in data_set:
loss_output = train_step(image, label)
if i % 10 == 0:
print("epoch: %s, step: %s, loss is %s" % (epoch, i, loss_output))
i += 1
Running the Single-machine Eight-card Script
Next, the corresponding scripts are invoked by commands, using the mpirun startup method and the 8-card distributed training script as an example of distributed training:
bash run.sh
After training, the log files are saved to the log_output directory, where part of the file directory structure is as follows:
└─ log_output
└─ 1
├─ rank.0
| └─ stdout
├─ rank.1
| └─ stdout
...
The results are saved in log_output/1/rank.*/stdout, and example is as follows:
epoch: 0, step: 0, loss is 2.3024087
epoch: 0, step: 10, loss is 2.2921634
epoch: 0, step: 20, loss is 2.278274
epoch: 0, step: 30, loss is 2.2537143
epoch: 0, step: 40, loss is 2.1638
epoch: 0, step: 50, loss is 1.984318
epoch: 0, step: 60, loss is 1.6061916
epoch: 0, step: 70, loss is 1.20966
epoch: 0, step: 80, loss is 0.98156196
epoch: 0, step: 90, loss is 0.77229893
epoch: 0, step: 100, loss is 0.6854114
...
Other startup methods such as dynamic networking and rank table startup can be found in startup methods.
Advanced Interfaces
parallel_optimizer_config: The optimizer parallel feature also provides a configuration dictionaryparallel_optimizer_config={}. Different effects can be achieved by configuring different key values inmindspore.set_auto_parallel_context():gradient_accumulation_shard: If True, the cumulative gradient variables will be sliced on the data parallelism. When accumulating gradients, an additional communication (ReduceScatter) will be introduced in each accumulation iteration to ensure computational consistency, but saves a large amount of compute device memory (e.g. GPU video memory), thus allowing the model to be trained in larger batches. This configuration is valid only if the model is set in pipelined parallel training or gradient accumulation and has a data parallel dimension. The default value is True.import mindspore as ms ms.set_auto_parallel_context(parallel_optimizer_config={"gradient_accumulation_shard": True}, enable_parallel_optimizer=True)
parallel_optimizer_threshold(int): This value indicates the minimum value of memory required for the target parameter when slicing the parameter. When the target parameter is smaller than this value, it will not be sliced. The default value is 64 in KB.import numpy as np import mindspore as ms param = ms.Parameter(ms.Tensor(np.ones((10, 2)), dtype=ms.float32), name='weight1') # The float32 type occupies 4 Bytes of memory: # param_size = np.prod(list(param.shape)) * 4 = (10 * 2) * 4 = 80B < 24KB, not be sliced ms.set_auto_parallel_context(parallel_optimizer_config={"parallel_optimizer_threshold": 24})
optimizer_weight_shard_size:Set the size of the communication domain split by the optimizer weight. The numerical range can be (0, device_num]. If pipeline parallel is enabled, the numerical range is (0, device_num/stage]. If the size of data parallel communication domain of the parameter cannot be divided byoptimizer_weight_shard_size, then the specified size of the communication domain split by the optimizer weight will not take effect. Default value is-1, which means the size of the communication domain split by the optimizer weight will be the size of data parallel communication domain of each parameter.import mindspore as ms ms.set_auto_parallel_context(parallel_optimizer_config={"optimizer_weight_shard_size": 2}, enable_parallel_optimizer=True)
Parameter.parallel_optimizer: This interface also allows the user to customize whether certain weights are sliced by the optimizer, as shown below:import numpy as np import mindspore as ms param = ms.Parameter(ms.Tensor(np.ones((10, 2))), name='weight1', parallel_optimizer=True) # Another way to set the parallel_optimizer attribute param2 = ms.Parameter(ms.Tensor(np.ones((10, 2))), name='weight2') param2.parallel_optimizer = False