Data Processing
![]()
Data is the foundation of deep learning, and high-quality data input is beneficial to the entire deep neural network.
mindspore.dataset provides a loading interface for some commonly used datasets and datasets in standard formats, enabling users to quickly process data. For an image dataset, you can use mindvision.dataset to load and process the dataset. This chapter first describes how to load and process the CIFAR-10 dataset by using the mindvision.dataset.Cifar10 interface, and then describes how to use mindspore.dataset.GeneratorDataset to implement custom dataset loading.
mindvision.datasetis a dataset interface developed based onmindspore.dataset. In addition to providing dataset loading capabilities,mindvision.datasetprovides dataset download, data processing, and data argumentation capabilities.
Data Process
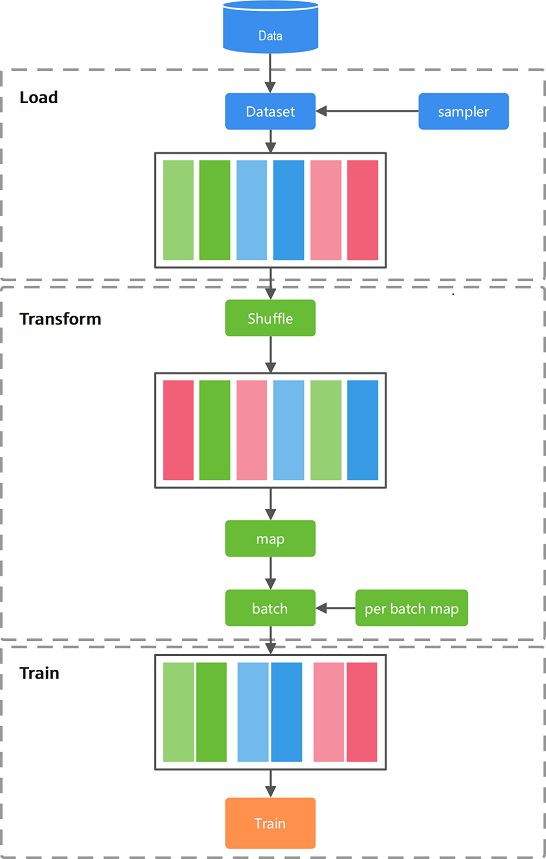
In the network training and inference process, raw data is generally stored in disks or databases. You need to read the data to the memory space through data loading, convert the data into the framework-common tensor format, and then map the data to an easy-to-learn feature space through data processing and argumentation. At the same time, increase the number of samples and generalization, and finally input the data to the network for calculation.
The following figure shows the overall process.
Dataset
A dataset is a collection of samples, and a row of a dataset is a sample that contains one or more features, and may further contain a label. Datasets must comply with certain specifications to facilitate model effect evaluation.
The dataset supports multiple formats, such as MindRecord (a MindSpore-developed data format), commonly used public image datasets and text datasets, and custom datasets.
Dataset Loading
The dataset loading enables continuous data obtaining for model training. The dataset provides classes to load common datasets. The dataset also provides classes for data files in different storage formats to load data.
The dataset provides a sampler for multiple purposes. The sampler generates the index sequence to be read, and the dataset reads data based on the index to help users sample datasets in different forms to meet training requirements, solve problems such as large datasets or uneven distribution of sample classes.
It should be noted that the sampler is responsible for performing the filter and reorder operations on samples, not performing the batch operation.
Data Processing
After the dataset loads data to the memory, the data is organized as tensors. Tensor is also a basic data structure in data augmentation.
Loading a Dataset
In the following example, the CIFAR-10 dataset is loaded through the mindvision.dataset.Cifar10 interface. The CIFAR-10 dataset contains a total of 60,000 32 x 32 color images which are evenly divided into 10 classes and classified into 50,000 training images and 10,000 test images. The Cifar10 interface allows users to download and load the CIFAR-10 dataset.

path: indicates the root directory of the dataset.split: indicates the training, test, or inference dataset. The value can betrain(default value),test, orinfer.download: determines whether to download the dataset. If this parameter is set toTrueand the dataset does not exist, the dataset can be downloaded and decompressed. The default value isFalse.
from mindvision.dataset import Cifar10
# Dataset root directory
data_dir = "./datasets"
# Download, extract, and load the CIFAR-10 training dataset.
dataset = Cifar10(path=data_dir, split='train', batch_size=6, resize=32, download=True)
dataset = dataset.run()
The directory structure of the CIFAR-10 dataset file is as follows:
datasets/
├── cifar-10-batches-py
│ ├── batches.meta
│ ├── data_batch_1
│ ├── data_batch_2
│ ├── data_batch_3
│ ├── data_batch_4
│ ├── data_batch_5
│ ├── readme.html
│ └── test_batch
└── cifar-10-python.tar.gz
Iterating a Dataset
You can use the create_dict_iterator interface to create a data iterator to iteratively access data. The default type of data to be accessed is Tensor. If output_numpy=True is set, the type of data to be accessed is Numpy.
The following shows the corresponding access data types, and the image shapes and labels.
data = next(dataset.create_dict_iterator())
print(f"Data type:{type(data['image'])}\nImage shape: {data['image'].shape}, Label: {data['label']}")
data = next(dataset.create_dict_iterator(output_numpy=True))
print(f"Data type:{type(data['image'])}\nImage shape: {data['image'].shape}, Label: {data['label']}")
Data type:<class 'mindspore.common.tensor.Tensor'>
Image shape: (6, 3, 32, 32), Label: [7 1 2 8 7 8]
Data type:<class 'numpy.ndarray'>
Image shape: (6, 3, 32, 32), Label: [8 0 0 2 6 1]
Data Processing and Augmentation
Data Processing
The mindvision.dataset.Cifar10 interface provides data processing capability. The data can be processed by simply setting the corresponding attributes.
shuffle: determines whether to shuffle datasets. If this parameter is set toTrue, the sequence of data sets is shuffled. The default value isFalse.batch_size: indicates the number of data contained in each batch.batch_size=2indicates that each batch contains two data records. The default value ofbatch_sizeis 32.repeat_num: indicates the number of duplicate datasets.repeat_num=1indicates one dataset. The default value ofrepeat_numis 1.
import numpy as np
import matplotlib.pyplot as plt
import mindspore.dataset.vision as vision
trans = [vision.HWC2CHW()] # convert shape of the input image from <H,W,C> to <C,H,W>
dataset = Cifar10(data_dir, batch_size=6, resize=32, repeat_num=1, shuffle=True, transform=trans)
data = dataset.run()
data = next(data.create_dict_iterator())
images = data["image"].asnumpy()
labels = data["label"].asnumpy()
print(f"Image shape: {images.shape}, Label: {labels}")
plt.figure()
for i in range(1, 7):
plt.subplot(2, 3, i)
image_trans = np.transpose(images[i-1], (1, 2, 0))
plt.title(f"{dataset.index2label[labels[i-1]]}")
plt.imshow(image_trans, interpolation="None")
plt.show()
Image shape: (6, 3, 32, 32), Label: [9 3 8 9 6 8]
Data Augmentation
If the data volume is too small or the sample scenario is simple, the model training effect is affected. You can perform the data augmentation operation to expand the sample diversity and improve the generalization capability of the model.
The mindvision.dataset.Cifar10 interface uses the default data augmentation feature, which allows users to perform data augmentation by setting attributes transform and target_transform.
transform: performs augmentation on dataset image data.target_transform: processes the dataset label data.
This section describes data augmentation of the CIFAR-10 dataset by using operators in the mindspore.dataset.vision .c_transforms module.
import numpy as np
import matplotlib.pyplot as plt
import mindspore.dataset.vision as vision
# Image augmentation
trans = [
vision.RandomCrop((32, 32), (4, 4, 4, 4)), # Automatically crop the image.
vision.RandomHorizontalFlip(prob=0.5), # Flip the image horizontally at random.
vision.HWC2CHW(), # Convert (h, w, c) to (c, h, w).
]
dataset = Cifar10(data_dir, batch_size=6, resize=32, transform=trans)
data = dataset.run()
data = next(data.create_dict_iterator())
images = data["image"].asnumpy()
labels = data["label"].asnumpy()
print(f"Image shape: {images.shape}, Label: {labels}")
plt.figure()
for i in range(1, 7):
plt.subplot(2, 3, i)
image_trans = np.transpose(images[i-1], (1, 2, 0))
plt.title(f"{dataset.index2label[labels[i-1]]}")
plt.imshow(image_trans, interpolation="None")
plt.show()
Image shape: (6, 3, 32, 32), Label: [7 6 7 4 5 3]