Implementing an Image Classification Application
Linux Windows Ascend GPU CPU Whole Process Beginner Intermediate Expert
![]()
Overview
This document uses a practice example to demonstrate the basic functions of MindSpore. For common users, it takes 20 to 30 minutes to complete the practice.
During the practice, a simple image classification function is implemented. The overall process is as follows:
Process the required dataset. The MNIST dataset is used in this example.
Define a network. The LeNet network is used in this example.
Define the loss function and optimizer.
Load the dataset and perform training. After the training is complete, check the result and save the model file.
Load the saved model for inference.
Validate the model, load the test dataset and trained model, and validate the result accuracy.
You can find the complete executable sample code at https://gitee.com/mindspore/docs/tree/r1.1/tutorials/tutorial_code/lenet.
This is a simple and basic workflow. For applying to other advanced and complex applications, extend this basic process as appropriate.
Preparations
Before you start, check whether MindSpore has been correctly installed. If not, install MindSpore on your computer by visiting MindSpore installation page.
In addition, you shall have basic mathematical knowledge such as Python coding basics, probability, and matrix.
Start your MindSpore experience now.
Downloading the Dataset
The MNIST dataset used in this example consists of 10 classes of 28 x 28 pixels grayscale images. It has a training set of 60,000 examples, and a test set of 10,000 examples.
Download the MNIST dataset at http://yann.lecun.com/exdb/mnist/. This page provides four download links of dataset files. The first two links are required for data training, and the last two links are required for data test.
Download the files, decompress them, and store them in the workspace directories ./MNIST_Data/train and ./MNIST_Data/test.
The directory structure is as follows:
└─MNIST_Data
├─test
│ t10k-images.idx3-ubyte
│ t10k-labels.idx1-ubyte
│
└─train
train-images.idx3-ubyte
train-labels.idx1-ubyte
For ease of use, we added the function of automatically downloading datasets in the sample script.
Importing Python Libraries and Modules
Before start, you need to import Python libraries.
Currently, the os libraries are required. For ease of understanding, other required libraries will not be described here.
import os
For details about MindSpore modules, search on the MindSpore API Page.
Configuring the Running Information
Before compiling code, you need to learn basic information about the hardware and backend required for MindSpore running.
You can use context.set_context to configure the information required for running, such as the running mode, backend information, and hardware information.
Import the context module and configure the required information.
import argparse
from mindspore import context
if __name__ == "__main__":
parser = argparse.ArgumentParser(description='MindSpore LeNet Example')
parser.add_argument('--device_target', type=str, default="CPU", choices=['Ascend', 'GPU', 'CPU'],
help='device where the code will be implemented (default: CPU)')
args = parser.parse_args()
context.set_context(mode=context.GRAPH_MODE, device_target=args.device_target)
dataset_sink_mode = not args.device_target == "CPU"
...
This example runs in graph mode. You can configure hardware information based on site requirements. For example, if the code runs on the Ascend AI processor, set --device_target to Ascend. This rule also applies to the code running on the CPU and GPU. For details about parameters, see the API description for context.set_context.
Processing Data
Datasets are important for training. A good dataset can effectively improve training accuracy and efficiency. Generally, before loading a dataset, you need to perform some operations on the dataset.
Defining the Dataset and Data Operations
Define the create_dataset function to create a dataset. In this function, define the data augmentation and processing operations to be performed.
Define the dataset.
Define parameters required for data augmentation and processing.
Generate corresponding data augmentation operations according to the parameters.
Use the
mapmapping function to apply data operations to the dataset.Process the generated dataset.
import mindspore.dataset as ds
import mindspore.dataset.transforms.c_transforms as C
import mindspore.dataset.vision.c_transforms as CV
from mindspore.dataset.vision import Inter
from mindspore import dtype as mstype
def create_dataset(data_path, batch_size=32, repeat_size=1,
num_parallel_workers=1):
""" create dataset for train or test
Args:
data_path: Data path
batch_size: The number of data records in each group
repeat_size: The number of replicated data records
num_parallel_workers: The number of parallel workers
"""
# define dataset
mnist_ds = ds.MnistDataset(data_path)
# define operation parameters
resize_height, resize_width = 32, 32
rescale = 1.0 / 255.0
shift = 0.0
rescale_nml = 1 / 0.3081
shift_nml = -1 * 0.1307 / 0.3081
# define map operations
resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR) # resize images to (32, 32)
rescale_nml_op = CV.Rescale(rescale_nml, shift_nml) # normalize images
rescale_op = CV.Rescale(rescale, shift) # rescale images
hwc2chw_op = CV.HWC2CHW() # change shape from (height, width, channel) to (channel, height, width) to fit network.
type_cast_op = C.TypeCast(mstype.int32) # change data type of label to int32 to fit network
# apply map operations on images
mnist_ds = mnist_ds.map(operations=type_cast_op, input_columns="label", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=resize_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=rescale_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=rescale_nml_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=hwc2chw_op, input_columns="image", num_parallel_workers=num_parallel_workers)
# apply DatasetOps
buffer_size = 10000
mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size) # 10000 as in LeNet train script
mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True)
mnist_ds = mnist_ds.repeat(repeat_size)
return mnist_ds
In the preceding information:
batch_size: number of data records in each group. Currently, each group contains 32 data records.
repeat_size: number of replicated data records.
Perform the shuffle and batch operations, and then perform the repeat operation to ensure that data is unique during one epoch.
MindSpore supports multiple data processing and augmentation operations, which are usually used in combined. For details, see section Data Processing in the MindSpore Tutorials.
Defining the Network
The LeNet network is relatively simple. In addition to the input layer, the LeNet network has seven layers, including two convolutional layers, two down-sample layers (pooling layers), and three full connection layers. Each layer contains different numbers of training parameters, as shown in the following figure:
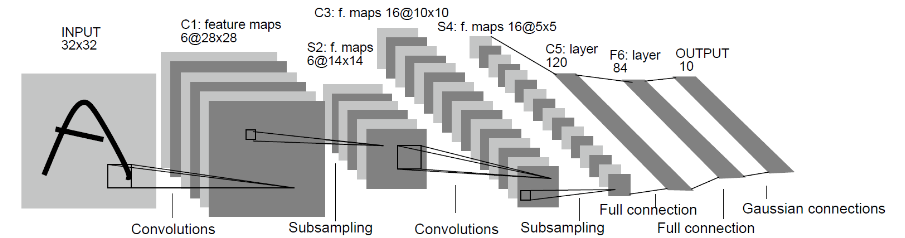
For details about the LeNet network, visit http://yann.lecun.com/exdb/lenet/.
You can initialize the full connection layers and convolutional layers by Normal.
MindSpore supports multiple parameter initialization methods, such as TruncatedNormal, Normal, and Uniform, default value is Normal. For details, see the description of the mindspore.common.initializer module in the MindSpore API.
To use MindSpore for neural network definition, inherit mindspore.nn.Cell. Cell is the base class of all neural networks (such as Conv2d).
Define each layer of a neural network in the __init__ method in advance, and then define the construct method to complete the forward construction of the neural network. According to the structure of the LeNet network, define the network layers as follows:
import mindspore.nn as nn
from mindspore.common.initializer import Normal
class LeNet5(nn.Cell):
"""
Lenet network structure
"""
#define the operator required
def __init__(self, num_class=10, num_channel=1):
super(LeNet5, self).__init__()
self.conv1 = nn.Conv2d(num_channel, 6, 5, pad_mode='valid')
self.conv2 = nn.Conv2d(6, 16, 5, pad_mode='valid')
self.fc1 = nn.Dense(16 * 5 * 5, 120, weight_init=Normal(0.02))
self.fc2 = nn.Dense(120, 84, weight_init=Normal(0.02))
self.fc3 = nn.Dense(84, num_class, weight_init=Normal(0.02))
self.relu = nn.ReLU()
self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten()
#use the preceding operators to construct networks
def construct(self, x):
x = self.max_pool2d(self.relu(self.conv1(x)))
x = self.max_pool2d(self.relu(self.conv2(x)))
x = self.flatten(x)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
Defining the Loss Function and Optimizer
Basic Concepts
Before definition, this section briefly describes concepts of loss function and optimizer.
Loss function: It is also called objective function and is used to measure the difference between a predicted value and an actual value. Deep learning reduces the value of the loss function by continuous iteration. Defining a good loss function can effectively improve the model performance.
Optimizer: It is used to minimize the loss function, improving the model during training.
After the loss function is defined, the weight-related gradient of the loss function can be obtained. The gradient is used to indicate the weight optimization direction for the optimizer, improving model performance.
Defining the Loss Function
Loss functions supported by MindSpore include SoftmaxCrossEntropyWithLogits, L1Loss, MSELoss. The loss function SoftmaxCrossEntropyWithLogits is used in this example.
from mindspore.nn.loss import SoftmaxCrossEntropyWithLogits
Call the defined loss function in the __main__ function.
if __name__ == "__main__":
...
#define the loss function
net_loss = SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
...
Defining the Optimizer
Optimizers supported by MindSpore include Adam, AdamWeightDecay and Momentum.
The popular Momentum optimizer is used in this example.
if __name__ == "__main__":
...
#learning rate setting
lr = 0.01
momentum = 0.9
#create the network
net = LeNet5()
#define the optimizer
net_opt = nn.Momentum(net.trainable_params(), lr, momentum)
...
Training the Network
Saving the Configured Model
MindSpore provides the callback mechanism to execute customized logic during training. ModelCheckpoint provided by the framework is used in this example.
ModelCheckpoint can save network models and parameters for subsequent fine-tuning.
from mindspore.train.callback import ModelCheckpoint, CheckpointConfig
if __name__ == "__main__":
...
# set parameters of check point
config_ck = CheckpointConfig(save_checkpoint_steps=1875, keep_checkpoint_max=10)
# apply parameters of check point
ckpoint = ModelCheckpoint(prefix="checkpoint_lenet", config=config_ck)
...
Configuring the Network Training
Use the model.train API provided by MindSpore to easily train the network. LossMonitor can monitor the changes of the loss value during training.
In this example, set train_epoch to 1 to train the dataset for five iterations.
from mindspore.nn.metrics import Accuracy
from mindspore.train.callback import LossMonitor
from mindspore import Model
...
def train_net(args, model, epoch_size, data_path, repeat_size, ckpoint_cb, sink_mode):
"""define the training method"""
print("============== Starting Training ==============")
#load training dataset
ds_train = create_dataset(os.path.join(data_path, "train"), 32, repeat_size)
model.train(epoch_size, ds_train, callbacks=[ckpoint_cb, LossMonitor()], dataset_sink_mode=sink_mode) # train
...
if __name__ == "__main__":
...
train_epoch = 1
mnist_path = "./MNIST_Data"
dataset_size = 1
model = Model(net, net_loss, net_opt, metrics={"Accuracy": Accuracy()})
train_net(args, model, train_epoch, mnist_path, dataset_size, ckpoint, dataset_sink_mode)
...
In the preceding information:
In the train_net method, we loaded the training dataset, mnist_path is MNIST dataset path.
Running and Viewing the Result
Run the script using the following command:
python lenet.py --device_target=CPU
In the preceding information:
Lenet. Py: the script file you wrote.
--device_target CPU: Specify the hardware platform.The parameters are ‘CPU’, ‘GPU’ or ‘Ascend’.
Loss values are printed during training, as shown in the following figure. Although loss values may fluctuate, they gradually decrease and the accuracy gradually increases in general. Loss values displayed each time may be different because of their randomicity.
The following is an example of loss values output during training:
...
epoch: 1 step: 1, loss is 2.3025916
epoch: 1 step: 2, loss is 2.302577
epoch: 1 step: 3, loss is 2.3023994
epoch: 1 step: 4, loss is 2.303059
epoch: 1 step: 5, loss is 2.3025753
epoch: 1 step: 6, loss is 2.3027692
epoch: 1 step: 7, loss is 2.3026521
epoch: 1 step: 8, loss is 2.3014607
...
epoch: 1 step: 1871, loss is 0.048939988
epoch: 1 step: 1872, loss is 0.028885357
epoch: 1 step: 1873, loss is 0.09475248
epoch: 1 step: 1874, loss is 0.046067055
epoch: 1 step: 1875, loss is 0.12366105
...
The following is an example of model files saved after training:
checkpoint_lenet-1_1875.ckpt
In the preceding information:
checkpoint_lenet-1_1875.ckpt: saved model parameter file. The following refers to saved files as well. The file name format is checkpoint_network name-epoch No._step No..ckpt.
Validating the Model
After obtaining the model file, we verify the generalization ability of the model.
from mindspore import load_checkpoint, load_param_into_net
def test_net(network,model,data_path):
"""define the evaluation method"""
print("============== Starting Testing ==============")
#load the saved model for evaluation
param_dict = load_checkpoint("checkpoint_lenet-1_1875.ckpt")
#load parameter to the network
load_param_into_net(network, param_dict)
#load testing dataset
ds_eval = create_dataset(os.path.join(data_path, "test")) # test
acc = model.eval(ds_eval, dataset_sink_mode=False)
print("============== Accuracy:{} ==============".format(acc))
if __name__ == "__main__":
...
test_net(net, model, mnist_path)
In the preceding information:
load_checkpoint: This API is used to load the CheckPoint model parameter file and return a parameter dictionary.
checkpoint_lenet-3_1404.ckpt: name of the saved CheckPoint model file.
load_param_into_net: This API is used to load parameters to the network.
Run the script using the following command:
python lenet.py --device_target=CPU
In the preceding information:
Lenet. Py: the script file you wrote.
--device_target CPU: Specify the hardware platform.The parameters are ‘CPU’, ‘GPU’ or ‘Ascend’.
After executing the command, the result is displayed as follows:
============== Starting Testing ==============
============== Accuracy:{'Accuracy': 0.9663477564102564} ==============
The model accuracy is displayed in the output content. In the example, the accuracy reaches 96.6%, indicating a good model quality. The model accuracy will be improved with more iterations train_epoch.