Optimizing the Data Processing
Linux Ascend GPU CPU Data Preparation Intermediate Expert
![]()
Overview
Data is the most important factor of deep learning. Data quality determines the upper limit of deep learning result, whereas model quality enables the result to approach the upper limit. Therefore, high-quality data input is beneficial to the entire deep neural network. During the entire data processing and data augmentation process, data continuously flows through a pipeline to the training system.

MindSpore provides data processing and data augmentation functions for users. In the pipeline process, if each step can be properly used, the data performance will be greatly improved. This section describes how to optimize performance during data loading, data processing, and data augmentation based on the CIFAR-10 dataset [1].
In addition, the storage, architecture and computing resources of the operating system will influence the performance of data processing to a certain extent.
Preparations
Importing Modules
The dataset module provides APIs for loading and processing datasets.
import mindspore.dataset as ds
The numpy module is used to generate ndarrays.
import numpy as np
Downloading the Required Dataset
Create the
./dataset/Cifar10Datadirectory in the current working directory. The dataset used for this practice is stored in this directory.Create the
./transformdirectory in the current working directory. The dataset generated during the practice is stored in this directory.Download the CIFAR-10 dataset in binary format and decompress the dataset file to the
./dataset/Cifar10Data/cifar-10-batches-bindirectory. The dataset will be used during data loading.Download the CIFAR-10 Python dataset in file-format and decompress the dataset file to the
./dataset/Cifar10Data/cifar-10-batches-pydirectory. The dataset will be used for data conversion.
The directory structure is as follows:
dataset/Cifar10Data
├── cifar-10-batches-bin
│ ├── batches.meta.txt
│ ├── data_batch_1.bin
│ ├── data_batch_2.bin
│ ├── data_batch_3.bin
│ ├── data_batch_4.bin
│ ├── data_batch_5.bin
│ ├── readme.html
│ └── test_batch.bin
└── cifar-10-batches-py
├── batches.meta
├── data_batch_1
├── data_batch_2
├── data_batch_3
├── data_batch_4
├── data_batch_5
├── readme.html
└── test_batch
In the preceding information:
The
cifar-10-batches-bindirectory is the directory for storing the CIFAR-10 dataset in binary format.The
cifar-10-batches-pydirectory is the directory for storing the CIFAR-10 dataset in Python file format.
Optimizing the Data Loading Performance
MindSpore provides multiple data loading methods, including common dataset loading, user-defined dataset loading, and the MindSpore data format loading. The dataset loading performance varies depending on the underlying implementation method.
Common Dataset |
User-defined Dataset |
MindRecord Dataset |
|
|---|---|---|---|
Underlying implementation |
C++ |
Python |
C++ |
Performance |
High |
Medium |
High |
Performance Optimization Solution
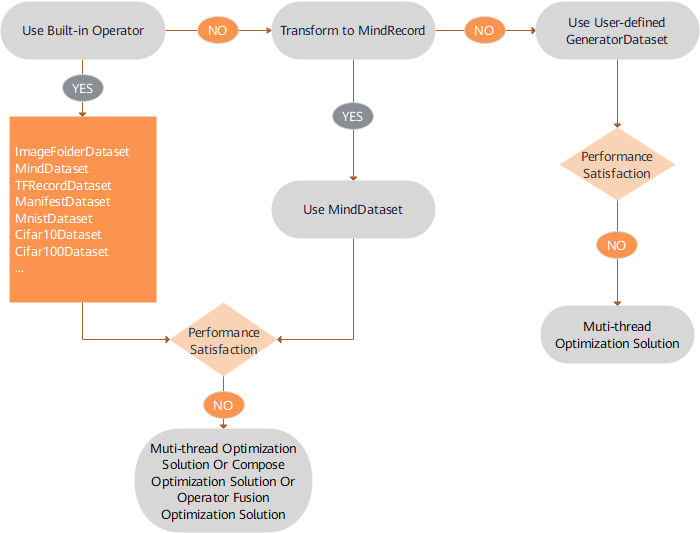
Suggestions on data loading performance optimization are as follows:
Built-in loading operators are preferred for supported dataset formats. For details, see Built-in Loading Operators. If the performance cannot meet the requirements, use the multi-thread concurrency solution. For details, see Multi-thread Optimization Solution.
For a dataset format that is not supported, convert the format to the MindSpore data format and then use the
MindDatasetclass to load the dataset. If the performance cannot meet the requirements, use the multi-thread concurrency solution, for details, see Multi-thread Optimization Solution.For dataset formats that are not supported, the user-defined
GeneratorDatasetclass is preferred for implementing fast algorithm verification. If the performance cannot meet the requirements, the multi-process concurrency solution can be used. For details, see Multi-process Optimization Solution.
Code Example
Based on the preceding suggestions of data loading performance optimization, the Cifar10Dataset class of built-in loading operators, the MindDataset class after data conversion, and the GeneratorDataset class are used to load data. The sample code is displayed as follows:
Use the
Cifar10Datasetclass of built-in operators to load the CIFAR-10 dataset in binary format. The multi-thread optimization solution is used for data loading. Four threads are enabled to concurrently complete the task. Finally, a dictionary iterator is created for the data and a data record is read through the iterator.cifar10_path = "./dataset/Cifar10Data/cifar-10-batches-bin/" # create a Cifar10Dataset object for reading data cifar10_dataset = ds.Cifar10Dataset(cifar10_path, num_parallel_workers=4) # create a dictionary iterator and read a data record through the iterator print(next(cifar10_dataset.create_dict_iterator()))
The output is as follows:
{'image': Tensor(shape=[32, 32, 3], dtype=UInt8, value= [[[235, 235, 235], [230, 230, 230], [234, 234, 234], ..., [248, 248, 248], [248, 248, 248], [249, 249, 249]], ..., [120, 120, 119], [146, 146, 146], [177, 174, 190]]]), 'label': Tensor(shape=[], dtype=UInt32, value= 9)}Use the
Cifar10ToMRclass to convert the CIFAR-10 dataset into the MindSpore data format. In this example, the CIFAR-10 dataset in Python file format is used. Then use theMindDatasetclass to load the dataset in the MindSpore data format. The multi-thread optimization solution is used for data loading. Four threads are enabled to concurrently complete the task. Finally, a dictionary iterator is created for data and a data record is read through the iterator.from mindspore.mindrecord import Cifar10ToMR cifar10_path = './dataset/Cifar10Data/cifar-10-batches-py' cifar10_mindrecord_path = './transform/cifar10.record' cifar10_transformer = Cifar10ToMR(cifar10_path, cifar10_mindrecord_path) # execute transformation from CIFAR-10 to MindRecord cifar10_transformer.transform(['label']) # create a MindDataset object for reading data cifar10_mind_dataset = ds.MindDataset(dataset_file=cifar10_mindrecord_path, num_parallel_workers=4) # create a dictionary iterator and read a data record through the iterator print(next(cifar10_mind_dataset.create_dict_iterator()))
The output is as follows:
{'data': Tensor(shape=[1431], dtype=UInt8, value= [255, 216, 255, ..., 63, 255, 217]), 'id': Tensor(shape=[], dtype=Int64, value= 30474), 'label': Tensor(shape=[], dtype=Int64, value= 2)}The
GeneratorDatasetclass is used to load the user-defined dataset, and the multi-process optimization solution is used. Four processes are enabled to concurrently complete the task. Finally, a dictionary iterator is created for the data, and a data record is read through the iterator.def generator_func(num): for i in range(num): yield (np.array([i]),) # create a GeneratorDataset object for reading data dataset = ds.GeneratorDataset(source=generator_func(5), column_names=["data"], num_parallel_workers=4) # create a dictionary iterator and read a data record through the iterator print(next(dataset.create_dict_iterator()))
The output is as follows:
{'data': Tensor(shape=[1], dtype=Int64, value= [0])}
Optimizing the Shuffle Performance
The shuffle operation is used to shuffle ordered datasets or repeated datasets. MindSpore provides the shuffle function for users. A larger value of buffer_size indicates a higher shuffling degree, consuming more time and computing resources. This API allows users to shuffle the data at any time during the entire pipeline process. However, because the underlying implementation methods are different, the performance of this method is not as good as that of setting the shuffle parameter to directly shuffle data by referring to the Built-in Loading Operators.
Performance Optimization Solution
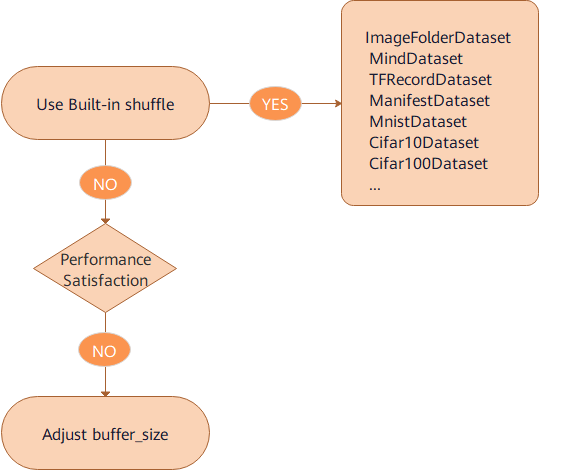
Suggestions on shuffle performance optimization are as follows:
Use the
shuffleparameter of built-in loading operators to shuffle data.If the
shufflefunction is used and the performance still cannot meet the requirements, adjust the value of thebuffer_sizeparameter to improve the performance.
Code Example
Based on the preceding shuffle performance optimization suggestions, the shuffle parameter of the Cifar10Dataset class of built-in loading operators and the Shuffle function are used to shuffle data. The sample code is displayed as follows:
Use the
Cifar10Datasetclass of built-in operators to load the CIFAR-10 dataset. In this example, the CIFAR-10 dataset in binary format is used, and theshuffleparameter is set to True to perform data shuffle. Finally, a dictionary iterator is created for the data and a data record is read through the iterator.cifar10_path = "./dataset/Cifar10Data/cifar-10-batches-bin/" # create a Cifar10Dataset object for reading data cifar10_dataset = ds.Cifar10Dataset(cifar10_path, shuffle=True) # create a dictionary iterator and read a data record through the iterator print(next(cifar10_dataset.create_dict_iterator()))
The output is as follows:
{'image': Tensor(shape=[32, 32, 3], dtype=UInt8, value= [[[235, 235, 235], [230, 230, 230], [234, 234, 234], ..., [248, 248, 248], [248, 248, 248], [249, 249, 249]], ..., [120, 120, 119], [146, 146, 146], [177, 174, 190]]]), 'label': Tensor(shape=[], dtype=UInt32, value= 9)}Use the
shufflefunction to shuffle data. Setbuffer_sizeto 3 and use theGeneratorDatasetclass to generate data.def generator_func(): for i in range(5): yield (np.array([i, i+1, i+2, i+3, i+4]),) ds1 = ds.GeneratorDataset(source=generator_func, column_names=["data"]) print("before shuffle:") for data in ds1.create_dict_iterator(): print(data["data"]) ds2 = ds1.shuffle(buffer_size=3) print("after shuffle:") for data in ds2.create_dict_iterator(): print(data["data"])
The output is as follows:
before shuffle: [0 1 2 3 4] [1 2 3 4 5] [2 3 4 5 6] [3 4 5 6 7] [4 5 6 7 8] after shuffle: [2 3 4 5 6] [0 1 2 3 4] [4 5 6 7 8] [1 2 3 4 5] [3 4 5 6 7]
Optimizing the Data Augmentation Performance
During image classification training, especially when the dataset is small, users can use data augmentation to preprocess images to enrich the dataset. MindSpore provides multiple data augmentation methods, including:
Use the built-in C operator (
c_transformsmodule) to perform data augmentation.Use the built-in Python operator (
py_transformsmodule) to perform data augmentation.Users can define Python functions as needed to perform data augmentation.
The performance varies according to the underlying implementation methods.
Module |
Underlying API |
Description |
|---|---|---|
c_transforms |
C++ (based on OpenCV) |
High performance |
py_transforms |
Python (based on PIL) |
This module provides multiple image augmentation functions and the method for converting PIL images into NumPy arrays |
Performance Optimization Solution
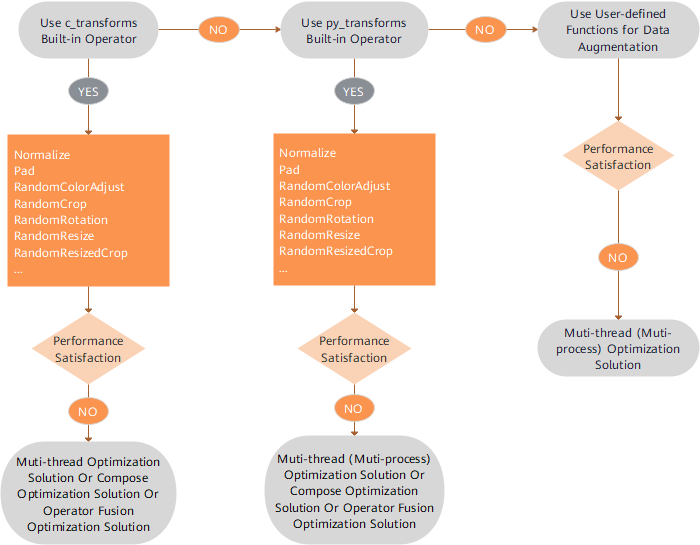
Suggestions on data augmentation performance optimization are as follows:
The
c_transformsmodule is preferentially used to perform data augmentation for its highest performance. If the performance cannot meet the requirements, refer to Multi-thread Optimization Solution, Compose Optimization Solution, or Operator Fusion Optimization Solution.If the
py_transformsmodule is used to perform data augmentation and the performance still cannot meet the requirements, refer to Multi-thread Optimization Solution, Multi-process Optimization Solution, Compose Optimization Solution, or Operator Fusion Optimization Solution.The
c_transformsmodule maintains buffer management in C++, and thepy_transformsmodule maintains buffer management in Python. Because of the performance cost of switching between Python and C++, it is advised not to use different operator types together.If the user-defined Python functions are used to perform data augmentation and the performance still cannot meet the requirements, use the Multi-thread Optimization Solution or Multi-process Optimization Solution. If the performance still cannot be improved, in this case, optimize the user-defined Python code.
Code Example
Based on the preceding suggestions of data augmentation performance optimization, the c_transforms module and user-defined Python function are used to perform data augmentation. The code is displayed as follows:
The
c_transformsmodule is used to perform data augmentation. During data augmentation, the multi-thread optimization solution is used. Four threads are enabled to concurrently complete the task. The operator fusion optimization solution is used and theRandomResizedCropfusion class is used to replace theRandomResizeandRandomCropclasses.import mindspore.dataset.transforms.c_transforms as c_transforms import mindspore.dataset.vision.c_transforms as C import matplotlib.pyplot as plt cifar10_path = "./dataset/Cifar10Data/cifar-10-batches-bin/" # create a Cifar10Dataset object for reading data cifar10_dataset = ds.Cifar10Dataset(cifar10_path, num_parallel_workers=4) transforms = C.RandomResizedCrop((800, 800)) # apply the transformation to the dataset through dataset.map() cifar10_dataset = cifar10_dataset.map(operations=transforms, input_columns="image", num_parallel_workers=4) data = next(cifar10_dataset.create_dict_iterator()) plt.imshow(data["image"].asnumpy()) plt.show()
The output is as follows:

A user-defined Python function is used to perform data augmentation. During data augmentation, the multi-process optimization solution is used, and four processes are enabled to concurrently complete the task.
def generator_func(): for i in range(5): yield (np.array([i, i+1, i+2, i+3, i+4]),) ds3 = ds.GeneratorDataset(source=generator_func, column_names=["data"]) print("before map:") for data in ds3.create_dict_iterator(): print(data["data"]) func = lambda x:x**2 ds4 = ds3.map(operations=func, input_columns="data", python_multiprocessing=True, num_parallel_workers=4) print("after map:") for data in ds4.create_dict_iterator(): print(data["data"])
The output is as follows:
before map: [0 1 2 3 4] [1 2 3 4 5] [2 3 4 5 6] [3 4 5 6 7] [4 5 6 7 8] after map: [ 0 1 4 9 16] [ 1 4 9 16 25] [ 4 9 16 25 36] [ 9 16 25 36 49] [16 25 36 49 64]
Optimizing the Operating System Performance
Data processing is performed on the host. Therefore, configurations of the host or operating system may affect the performance of data processing. Major factors include storage, NUMA architecture, and CPU (computing resources).
Storage
Solid State Drive (SSD) is recommended for storing large datasets. SSD reduces the impact of I/O on data processing.
In most cases, after a dataset is loaded, it is stored in page cache of the operating system. To some extent, this reduces I/O overheads and accelerates reading subsequent epochs.
NUMA architecture
NUMA (Non-uniform Memory Architecture) is developed to solve the scalability problem of traditional Symmetric Multi-processor systems. The NUMA system has multiple memory buses. Several processors are connected to one memory via memory bus to form a group. This way, the entire large system is divided into several groups, the concept of this group is called a node in the NUMA system. Memory belonging to this node is called local memory, memory belonging to other nodes (with respect to this node) is called foreign memory. Therefore, the latency for each node to access its local memory is different from accessing foreign memory. This needs to be avoided during data processing. Generally, the following command can be used to bind a process to a node:
numactl --cpubind=0 --membind=0 python train.py
The example above binds the
train.pyprocess tonuma node0.CPU (computing resource)
CPU affects data processing in two aspects: resource allocation and CPU frequency.
Resource allocation
In distributed training, multiple training processes are run on one device. These training processes allocate and compete for computing resources based on the policy of the operating system. When there is a large number of processes, data processing performance may deteriorate due to resource contention. In some cases, users need to manually allocate resources to avoid resource contention.
numactl --cpubind=0 python train.py
or
taskset -c 0-15 python train.py
The
numactlmethod directly specifiesnuma node id. Thetasksetmethod allows for finer control by specifyingcpu corewithin anuma node. Thecore idrange from 0 to 15.CPU frequency
The setting of CPU frequency is critical to maximizing the computing power of the host CPU. Generally, the Linux kernel supports the tuning of the CPU frequency to reduce power consumption. Power consumption can be reduced to varying degrees by selecting power management policies for different system idle states. However, lower power consumption means slower CPU wake-up which in turn impacts performance. Therefore, if the CPU’s power setting is in the conservative or powersave mode,
cpupowercommand can be used to switch performance modes, resulting in significant data processing performance improvement.cpupower frequency-set -g performance
Performance Optimization Solution Summary
Multi-thread Optimization Solution
During the data pipeline process, the number of threads for related operators can be set to improve the concurrency and performance. For example:
During data loading, the
num_parallel_workersparameter in the built-in data loading class is used to set the number of threads.During data augmentation, the
num_parallel_workersparameter in themapfunction is used to set the number of threads.During batch processing, the
num_parallel_workersparameter in thebatchfunction is used to set the number of threads.
For details, see Built-in Loading Operators.
Multi-process Optimization Solution
During data processing, operators implemented by Python support the multi-process mode. For example:
By default, the
GeneratorDatasetclass is in multi-process mode. Thenum_parallel_workersparameter indicates the number of enabled processes. The default value is 1. For details, see GeneratorDataset.If the user-defined Python function or the
py_transformsmodule is used to perform data augmentation and thepython_multiprocessingparameter of themapfunction is set to True, thenum_parallel_workersparameter indicates the number of processes and the default value of thepython_multiprocessingparameter is False. In this case, thenum_parallel_workersparameter indicates the number of threads. For details, see Built-in Loading Operators.
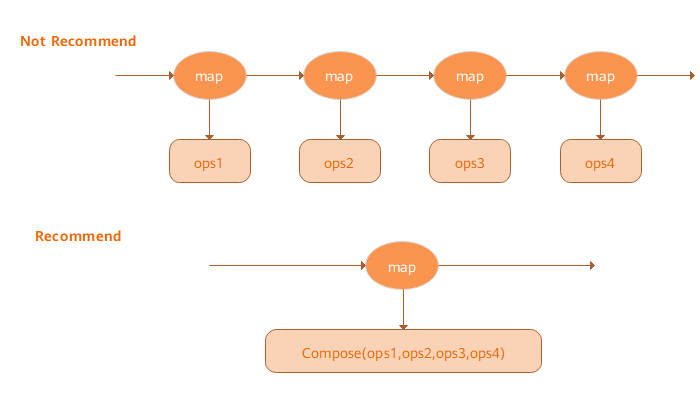
Compose Optimization Solution
Map operators can receive the Tensor operator list and apply all these operators based on a specific sequence. Compared with the Map operator used by each Tensor operator, such Fat Map operators can achieve better performance, as shown in the following figure:
Operator Fusion Optimization Solution
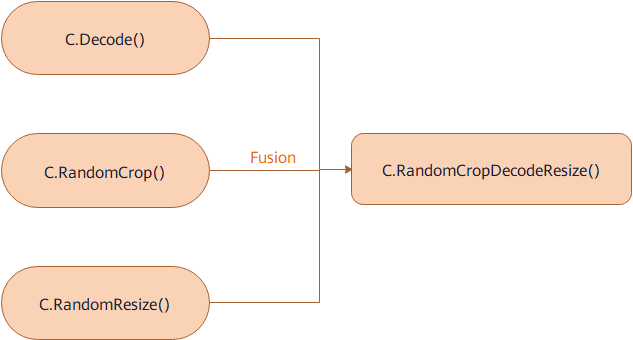
Some fusion operators are provided to aggregate the functions of two or more operators into one operator. For details, see Augmentation Operators. Compared with the pipelines of their components, such fusion operators provide better performance. As shown in the figure:
Operating System Optimization Solution
Use Solid State Drives to store the data.
Bind the process to a NUMA node.
Manually allocate more computing resources.
Set a higher CPU frequency.
References
[1] Alex Krizhevsky. Learning Multiple Layers of Features from Tiny Images.