使用Runtime执行训练 (C++)
Linux Android 模型训练 模型加载 数据准备 中级 高级
![]()
概述
端侧训练主要步骤:
选择一个模型,定义待训练层并导出。
将模型转换为端侧可训练模型,即
.ms文件。在设备端训练该模型,导出已经训练好的模型方便后续使用。
转换得到的 *.ms 文件包含模型结构,.ms文件将被载入设备端进行训练。
下面的时序图展示了训练流程:
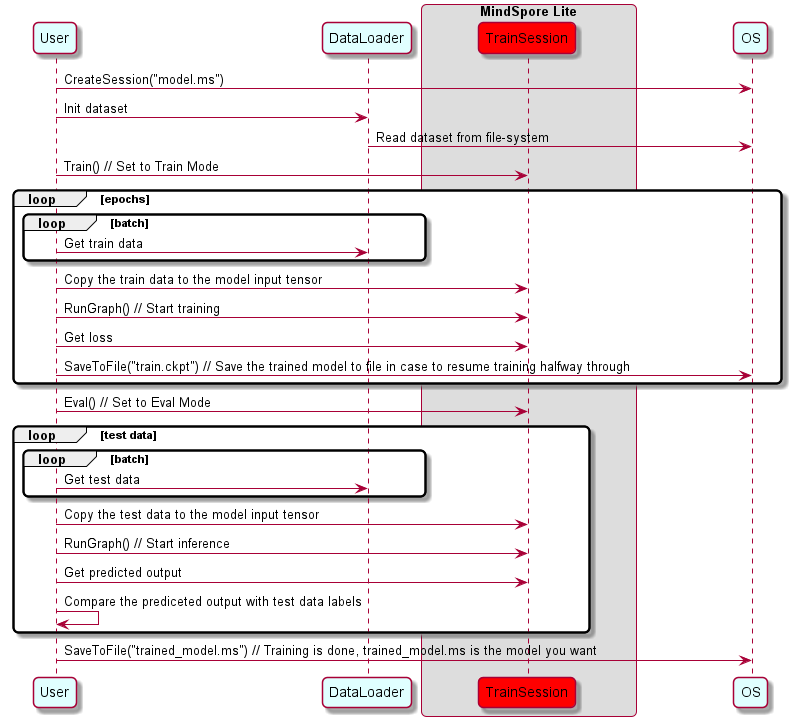
图中的名词说明:
OS:能够获取数据的操作系统。User:能够进行训练的应用/对象。DataLoader:能够加载数据并能在模型训练中进行数据预处理的对象(例如读取图像,缩放至指定大小,转换为bitmap格式)。TrainSession:一个由MindSpore Lite提供的软件模块,它能为模型节点和内联张量提供flatbuffer反序列化的功能、执行图编译并调用图执行器进行训练。
更多C++API说明,请参考API文档。
创建会话
使用Mindpore Lite训练框架进行训练时,TrainSession是训练的主入口,通过TrainSession我们可以进行训练图编译、训练图执行。
读取模型
模型文件是一个flatbuffer序列化文件,它通过MindSpore模型转换工具得到,其文件扩展名为.ms。在模型训练或推理之前,模型需要从文件系统中加载并解析。相关操作主要在Model类中实现,该类具有例如网络结构、张量大小、权重数据和操作属性等模型数据。
与MindSpore Lite推理架构不同的是:在MindSpore Lite中,由于训练时模型对象
Model将被TrainSession占用,所以你不允许再直接操作它。所有与Model对象的交互操作,包括实例化、编译和删除操作将在TrainSession中处理。
创建上下文
Context是一个MindSpore Lite对象,它包含了TrainSession用来引导图编译和执行的基础配置参数。它能够让你指定模型运行的设备类型(例如CPU或GPU),模型训练和推理时使用的线程数量,以及内存分配策略。目前TrainSession只支持单线程的CPU设备。
如果用户通过new创建Context,不再需要时,需要用户通过delete释放。一般在TrainSession对象创建完成后,Context对象即可释放。
创建会话
有两种方式可以创建会话:
第一种直接读取文件系统上的训练模型文件,然后反序列化,编译并生成有效的
TrainSession对象。上述Context将作为一个基本配置传递给TrainSession。该静态函数原型如下:TrainSession *TrainSession::CreateSession(const string &filename, const Context *context, bool mode)其中
filename是模型文件名,context是指向Context的对象指针,mode表示当前会话是否为训练模式。成功创建后,函数返回一个已全部编译并可使用的TrainSession,该实例必须在当前会话结束前使用delete释放。第二种使用flatbuffer的内存拷贝创建
TrainSession。静态方法如下:TrainSession *TrainSession::CreateSession(const char *buf, size_t size, const Context *context, bool mode)其中
buf是一个指向内存缓冲区的常量指针,size是缓冲区长度。成功创建后,函数返回一个完整编译并且可以使用的TrainSession实例。buf指针在函数调用完成后,可以被立即释放以节省资源。一旦TrainSession实例不再被使用,它必须使用delete释放。
使用示例
下面示例代码演示了如何在CPU单线程上创建TrainContext:
#include "include/train_session.h"
#include "include/context.h"
mindspore::lite::Context context;
context.device_list_[0].device_info_.cpu_device_info_.cpu_bind_mode_ = mindspore::lite::NO_BIND;
context.thread_num_ = 1;
auto session = mindspore::session::TrainSession::CreateSession(std::string("model_tod.ms"), &context);
训练模式
一个网络能通过TrainSession进行推理和训练。推理和训练模式的不同点:
网络输入:训练需要数据和标签,而推理只需要数据。
网络输出:训练返回损失值,而推理返回预测标签值。
每一轮训练都会更新网络的各层权重值,但推理不会。
网络的某些层在训练和推理具有不同的输出,例如在批量标准化 (Batch Normalization) 层中更新批次累计均值和方差。
切换训练和验证模式
TrainSession提供了下述公共方法:
/// \brief Set model to train mode
/// \return STATUS as an error code of compiling graph, STATUS is defined in errorcode.h
virtual int Train() = 0;
/// \brief Set model to eval mode
/// \return STATUS as an error code of compiling graph, STATUS is defined in errorcode.h
virtual int Eval() = 0;
使用示例
下述代码展示了如何将一个TrainSession对象设置为训练模式:
// Assuming session is a valid instance of TrainSession
auto ret = session->Train();
if (ret != RET_OK) {
std::cerr << "Could not set session to train mode" << std::endl;
return -1;
}
输入数据
获取输入张量
在图执行之前,无论执行训练或推理,输入数据必须载入模型的输入张量。MindSpore Lite提供了以下函数来获取模型的输入张量:
使用
GetInputsByTensorName方法,获取连接到基于张量名称的模型输入节点模型输入张量。/// \brief Get input MindSpore Lite MSTensors of model by tensor name. /// /// \param[in] tensor_name Define tensor name. /// /// \return MindSpore Lite MSTensor. virtual mindspore::tensor::MSTensor *GetInputsByTensorName(const std::string &tensor_name) const = 0;
使用
GetInputs方法,直接获取所有模型输入张量的向量。/// \brief Get input MindSpore Lite MSTensors of model. /// /// \return The vector of MindSpore Lite MSTensor. virtual std::vector<tensor::MSTensor *> GetInputs() const = 0;
如果模型需要1个以上的输入张量(例如训练过程中,数据和标签都作为网络的输入),用户有必要知道输入顺序和张量名称,这些信息可以从Python对应的模型中获取。此外,用户也根据输入张量的大小推导出这些信息。
拷贝数据
一旦获取到了模型的输入张量,数据需要拷贝到张量中。下列方法可以获取数据字节大小、数据维度、元素个数、数据类型和写指针。详见 MSTensor API 文档。
/// \brief Get byte size of data in MSTensor.
///
/// \return Byte size of data in MSTensor.
virtual size_t Size() const = 0;
/// \brief Get shape of the MindSpore Lite MSTensor.
///
/// \return A vector of int as the shape of the MindSpore Lite MSTensor.
virtual std::vector<int> shape() const = 0;
/// \brief Get number of element in MSTensor.
///
/// \return Number of element in MSTensor.
virtual int ElementsNum() const = 0;
/// \brief Get data type of the MindSpore Lite MSTensor.
///
/// \note TypeId is defined in mindspore/mindspore/core/ir/dtype/type_id.h. Only number types in TypeId enum are
/// suitable for MSTensor.
///
/// \return MindSpore Lite TypeId of the MindSpore Lite MSTensor.
virtual TypeId data_type() const = 0;
/// \brief Get the pointer of data in MSTensor.
///
/// \note The data pointer can be used to both write and read data in MSTensor.
///
/// \return The pointer points to data in MSTensor.
virtual void *MutableData() const = 0;
使用示例
以下示例代码展示了如何从LiteSession中获取完整的图输入张量和如何将模型输入数据转换为MSTensor类型。
// Assuming session is a valid instance of TrainSession
auto inputs = session->GetInputs();
// Assuming the model has two input tensors, the first is for data and the second for labels
int data_index = 0;
int label_index = 1;
if (inputs.size() != 2) {
std::cerr << "Unexpected amount of input tensors. Expected 2, model requires " << inputs.size() << std::endl;
return -1;
}
// Assuming batch_size and data_size variables holds the Batch size and the size of a single data tensor, respectively:
// And assuming sparse labels are used
if ((inputs.at(data_index)->Size() != batch_size*data_size) ||
(inputs.at(label_index)->ElementsNum() != batch_size)) {
std::cerr << "Input data size does not match model input" << std::endl;
return -1;
}
// Assuming data_ptr is the pointer to a batch of data tensors
// and iassuming label_ptr is a pointer to a batch of label indices (obtained by the DataLoder)
auto *in_data = inputs.at(data_index)->MutableData();
auto *in_labels = inputs.at(label_index)->MutableData();
if ((in_data == nullptr)|| (in_labels == nullptr)) {
std::cerr << "Model's input tensor is nullptr" << std::endl;
return -1;
}
memcpy(in_data, data_ptr, inputs.at(data_index)->Size());
memcpy(in_labels, label_ptr, inputs.at(label_index)->Size());
// After filling the input tensors the data_ptr and label_ptr may be freed
// The input tensors themselves are managed by MindSpore Lite and users are not allowed to access them or delete them
MindSpore Lite模型输入张量的数据维度必须为NHWC(批次数,高度,宽度和通道数)。
用户不能主动释放
GetInputs和GetInputsByTensorName函数返回的张量。
执行图
执行会话
无论TrainSession对象是训练模式还是推理模式,执行模型的方式都是调用RunGraph方法。
/// \brief Run session with callbacks.
///
/// \param[in] before Define a call_back_function to be called before running each node.
/// \param[in] after Define a call_back_function called after running each node.
///
/// \note RunGraph should be called after CompileGraph.
///
/// \return STATUS as an error code of running graph, STATUS is defined in errorcode.h.
virtual int RunGraph(const KernelCallBack &before = nullptr, const KernelCallBack &after = nullptr) = 0;
在执行图计算前,用户需要确保数据被正确地导入了输入张量中。
执行回调
MindSpore Lite框架允许用户设置两个在每个节点计算前后调用的回调函数。这两个函数能够帮助用户跟踪、调试网络,并测量各节点的计算时间。回调参数如下:
计算节点的当前输入张量。
计算节点的当前输出张量。
计算节点的名称和类型。
尽管节点计算前后的名称和类型一致,两个回调函数的输出张量却不同。对于某些计算操作,输入张量也不同。
/// \brief CallBackParam defines input arguments for callback function.
struct CallBackParam {
std::string node_name; /**< node name argument */
std::string node_type; /**< node type argument */
};
/// \brief KernelCallBack defined the function pointer for callBack.
using KernelCallBack = std::function<bool(std::vector<tensor::MSTensor *> inputs,
std::vector<tensor::MSTensor *> outputs, const CallBackParam &opInfo)>;
使用示例
// Assuming session is a valid instance of TrainSession and that data was assigned to the input tensors
// Definition of a callback function that will be called before forwarding operator
bool before_callback(const std::vector<mindspore::tensor::MSTensor *> &inputs,
const std::vector<mindspore::tensor::MSTensor *> &outputs,
const mindspore::CallBackParam &call_param) {
std::cout << call_param.node_name << std::endl;
std::cout << "Before forwarding: input size is " << inputs.size() << std::endl;
return true;
};
// Definition of callback function that will be called after forwarding operator
bool after_callback(const std::vector<mindspore::tensor::MSTensor *> &inputs,
const std::vector<mindspore::tensor::MSTensor *> &outputs,
const mindspore::CallBackParam &call_param) {
std::cout << "After forwarding: output size is " << outputs.size() << std::endl;
return true;
};
// Hand over the callback functions to RunGraph when performing the training or inference
ret = session_->RunGraph(before_callback, after_callback);
if (ret != RET_OK) {
MS_LOG(ERROR) << "Run graph failed.";
return RET_ERROR;
}
获取输出
获取输出张量
MindSpore Lite提供下列方法来获取模型的输入张量:
使用
GetOutputByNodeName方法获取一个确定节点的输出张量。/// \brief Get output MindSpore Lite MSTensors of model by node name. /// /// \param[in] node_name Define node name. /// /// \return The vector of MindSpore Lite MSTensor. virtual std::vector<tensor::MSTensor *> GetOutputsByNodeName(const std::string &node_name) const = 0;
使用
GetOutputByTensorName方法,依据张量名称获取输出张量。/// \brief Get output MindSpore Lite MSTensors of model by tensor name. /// /// \param[in] tensor_name Define tensor name. /// /// \return Pointer of MindSpore Lite MSTensor. virtual mindspore::tensor::MSTensor *GetOutputByTensorName(const std::string &tensor_name) const = 0;
使用
GetOutputs方法,根据张量名称排序的所有输出张量。/// \brief Get output MindSpore Lite MSTensors of model mapped by tensor name. /// /// \return The map of output tensor name and MindSpore Lite MSTensor. virtual std::unordered_map<std::string, mindspore::tensor::MSTensor *> GetOutputs() const = 0;
获取模型输出张量后,用户需要将数据导入张量中。使用MSTensor的Size方法获取将要导入张量中的数据大小,使用data_type方法获取 MSTensor的数据类型,并且使用MutableData方法写指针。
/// \brief Get byte size of data in MSTensor.
///
/// \return Byte size of data in MSTensor.
virtual size_t Size() const = 0;
/// \brief Get data type of the MindSpore Lite MSTensor.
///
/// \note TypeId is defined in mindspore/mindspore/core/ir/dtype/type_id.h. Only number types in TypeId enum are
/// suitable for MSTensor.
///
/// \return MindSpore Lite TypeId of the MindSpore Lite MSTensor.
virtual TypeId data_type() const = 0;
/// \brief Get the pointer of data in MSTensor.
///
/// \note The data pointer can be used to both write and read data in MSTensor.
///
/// \return The pointer points to data in MSTensor.
virtual void *MutableData() const = 0;
使用示例
下列代码展示了如何使用GetOutputs方法从会话中获取输出张量,并打印前10个数据或每个输出张量的数据记录。
// Assume that session is a vlaid TrainSession object
auto output_map = session->GetOutputs();
// Assume that the model has only one output node.
auto out_node_iter = output_map.begin();
std::string name = out_node_iter->first;
// Assume that the unique output node has only one output tensor.
auto out_tensor = out_node_iter->second;
if (out_tensor == nullptr) {
std::cerr << "Output tensor is nullptr" << std::endl;
return -1;
}
// Assume that the data format of output data is float 32.
if (out_tensor->data_type() != mindspore::TypeId::kNumberTypeFloat32) {
std::cerr << "Output of lenet should in float32" << std::endl;
return -1;
}
auto *out_data = reinterpret_cast<float *>(out_tensor->MutableData());
if (out_data == nullptr) {
std::cerr << "Data of out_tensor is nullptr" << std::endl;
return -1;
}
// Print the first 10 float data or all output data of the output tensor.
std::cout << "Output data: ";
for (size_t i = 0; i < 10 && i < out_tensor->ElementsNum(); i++) {
std::cout << " " << out_data[i];
}
std::cout << std::endl;
// The elements in outputs do not need to be free by users, because outputs are managed by the MindSpore Lite.
用户无需手动释放
GetOutputsByNodeName、GetOutputByTensorName和GetOutputs函数返回的数组或是哈希表。
下列代码展示了如何使用GetOutputsByNodeName方法从当前会话中获取输出张量:
// Assume that session is a vlaid TrainSession instance
// Assume that model has a output node named output_node_name_0.
auto output_vec = session->GetOutputsByNodeName("output_node_name_0");
// Assume that output node named output_node_name_0 has only one output tensor.
auto out_tensor = output_vec.front();
if (out_tensor == nullptr) {
std::cerr << "Output tensor is nullptr" << std::endl;
return -1;
}
下列代码展示了如何使用GetOutputsByTensorName方法从当前会话中获取输出张量:
// Assume that session is a vlaid TrainSession instance
// We can use GetOutputTensorNames method to get the names of all the output tensors of the model
auto tensor_names = session->GetOutputTensorNames();
// Use output tensor name returned by GetOutputTensorNames as key
for (auto tensor_name : tensor_names) {
auto out_tensor = session->GetOutputByTensorName(tensor_name);
if (out_tensor == nullptr) {
std::cerr << "Output tensor is nullptr" << std::endl;
return -1;
}
}
获取版本号
使用示例
下列代码展示了如何使用Version方法获取版本号:
#include "include/version.h"
std::string version = mindspore::lite::Version();
保存训练后模型
MindSpore Lite提供了下面的方法保存训练好的模型:
/// \brief Save the trained model into a flatbuffer file
///
/// \param[in] filename Filename to save flatbuffer to
///
/// \return 0 on success or -1 in case of error
virtual int SaveToFile(const std::string &filename) const = 0;
保存下来的模型可以用于继续训练或者使用TrainSesson的Eval模式执行推理。
MindSpore Lite训练出来的模型,必须使用训练框架的接口进行推理,即创建
TrainSession并调用Eval()方法设置为推理模式。benchmark工具不支持运行训练出的模型,请使用benchmark_train工具。