多模态理解模型开发
![]()
多模态理解模型(Multimodal Model)是指能够处理并结合来自不同模态(如文字、图像、音频、视频等)的信息进行学习和推理的人工智能模型。 传统的单一模态模型通常只关注单一数据类型,如文本分类模型只处理文本数据,图像识别模型只处理图像数据。而多模态理解模型则通过融合不同来源的数据来完成更复杂的任务,从而能够理解和生成更加丰富、全面的内容。
本文档旨在介绍MindSpore Transformers中的多模态理解模型,文档提供详细的步骤和示例指导用户使用MindSpore Transformers构建自定义的多模态理解模型和数据处理等模块。此外,用户还可以根据文档内容,完成模型的训练和推理等任务。
MindSpore Transformers中多模态理解模型统一架构主要包括如下几个部分的内容:
数据集构建
在训练多模态理解模型之前,通常需要先完成多模态数据集的构建,MindSpore Transformers目前提供多模态数据的dataset类和dataloader类,用户可直接使用:
BaseMultiModalDataLoader是多模态数据集加载类,主要完成从
json文件中读取数据的功能;ModalToTextSFTDataset是多模态数据集处理类,主要完成多模态数据处理,以及数据集批处理、数据集重复等操作,具体多模态数据处理可参考数据处理模块;
以下是Cogvlm2-Video模型的训练数据集json文件部分内容示例:
[{
"id": "v_p1QGn0IzfW0.mp4",
"conversations": [
{
"from": "user",
"value": "<|reserved_special_token_3|>/path/VideoChatGPT/convert/v_p1QGn0IzfW0.mp4<|reserved_special_token_4|>What equipment is visible in the gym where the boy is doing his routine?"
},
{
"from": "assistant",
"value": "There is other equipment visible in the gym like a high bar and still rings."
}
]
}]
其中,<|reserved_special_token_3|>和<|reserved_special_token_3|>是Cogvlm2-Video模型中视频路径的标识符。
用户可根据需要构造自定义的json文件,文件格式为一个包含多个字典的列表,每个字典代表一个数据样本,样本中id字段表示数据标识符,conversations字段表示多轮对话内容。
在构造json文件之后,可运行下面的示例代码查看数据集中的数据样本:
from mindformers.dataset.dataloader.multi_modal_dataloader import BaseMultiModalDataLoader
# build data loader
dataset_loader = BaseMultiModalDataLoader(
annotation_file = '/path/dataset.json', shuffle=False
)
print(dataset_loader[0])
# ([['user', '<|reserved_special_token_3|>/path/VideoChatGPT/convert/v_p1QGn0IzfW0.mp4<|reserved_special_token_4|>What equipment is visible in the gym where the boy is doing his routine?'], ['assistant', 'There is other equipment visible in the gym like a high bar and still rings.']],)
数据处理模块
在多模态理解模型的训练和推理过程中,都需要使用数据处理模块实现对多模态数据的预处理,该模块在训练时会在ModalToTextSFTDataset中被调用,推理时则是在MultiModalToTextPipeline中被调用。
下图是多模态数据的处理流程图,图中的自定义模块需要用户根据实际需求实现,其他模块直接调用即可。
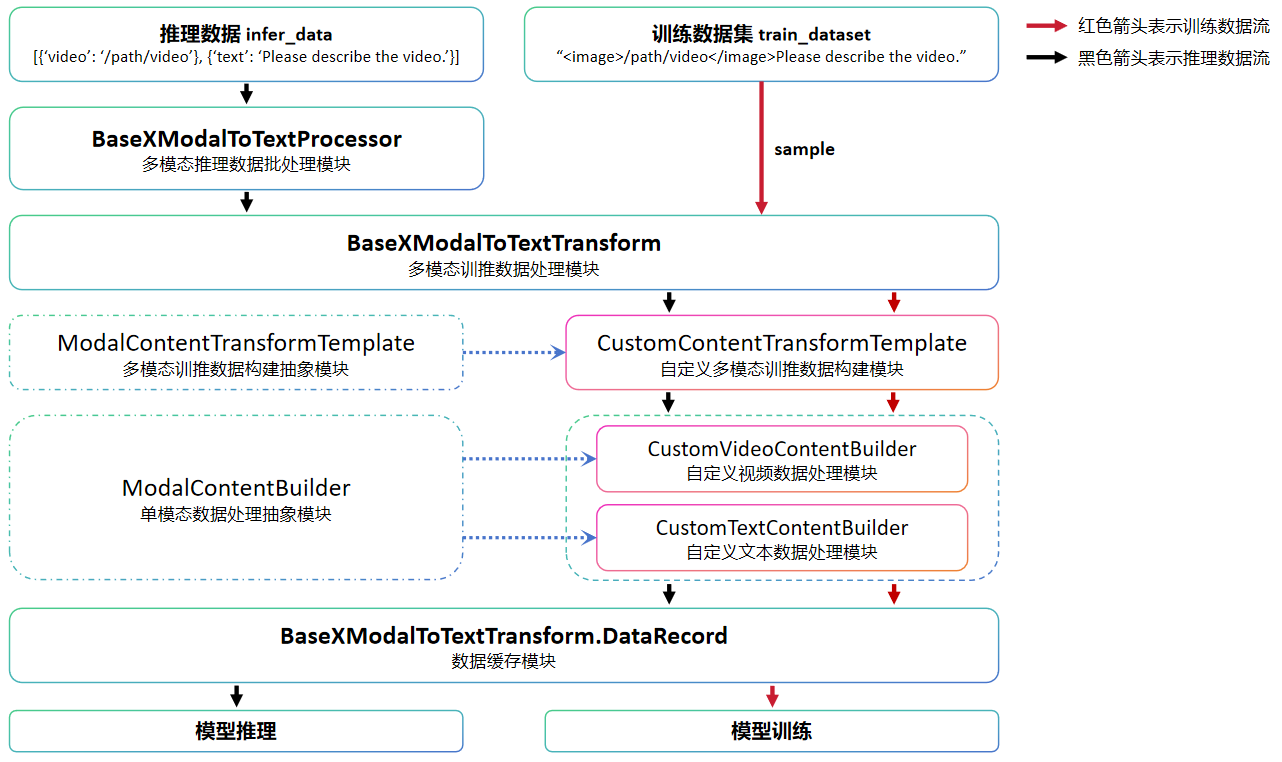
下面以CogVLm2-Video模型数据预处理模块为例,介绍多模态数据处理模块中各组成部分的功能。
BaseXModalToTextProcessor主要用于接收用于推理的多模态原始数据并对进行预处理操作,同时也实现了推理结果后处理操作,该类用户可直接使用;
BaseXModalToTextTransform主要用于将
BaseXModalToTextProcessor或多模态数据集返回的数据分别处理为推理或训练数据,该类用户可直接使用;ModalContentTransformTemplate是所有模态训推数据构建模块的抽象类,由于数据具体操作与模型相关,因此用户需要根据需求实现对应的自定义数据构建类,在
Cogvlm2-Video模型中实现了CogVLM2ContentTransformTemplate类,实现了对视频以及文本数据的处理;ModalContentBuilder是所有单模态数据处理的抽象类,如果模型要处理多个模态的数据,就需要在自定义数据构建类初始化时创建多个对应的单模态数据处理类,在
Cogvlm2-Video模型中实现了CogVLM2VideoContentBuilder类用于处理视频数据,并使用通用文本数据处理类BaseTextContentBuilder类处理文本数据。
下面是Cogvlm2-Video模型训练、推理数据预处理的示例代码。
模型训练数据处理
在多模态理解模型训练任务中,数据预处理的配置通常会写在train_dataset中,Cogvlm2-Video模型训练配置文件中数据集相关配置如下:
finetune_cogvlm2_video_llama3_chat_13b_lora.yaml
train_dataset: &train_dataset
data_loader:
type: BaseMultiModalDataLoader
annotation_file: "/path/train_data.json"
shuffle: True
modal_to_text_transform:
type: BaseXModalToTextTransform
max_length: 2048
model_transform_template:
type: CogVLM2ContentTransformTemplate
output_columns: [ "input_ids", "images", "video_context_pos", "position_ids", "labels" ]
signal_type: "chat"
mode: 'train'
pos_pad_length: 2048
tokenizer:
add_bos_token: False
add_eos_token: False
max_length: 2048
pad_token: "<|reserved_special_token_0|>"
vocab_file: "/path/tokenizer.model"
type: CogVLM2Tokenizer
其中,annotation_file为训练数据的json文件路径,modal_to_text_transform与tokenizer都应该与推理配置中processor中的类似。
from mindformers.tools.register.config import MindFormerConfig
from mindformers.dataset.modal_to_text_sft_dataset import ModalToTextSFTDataset
# load configs
configs = MindFormerConfig("configs/cogvlm2/finetune_cogvlm2_video_llama3_chat_13b_lora.yaml")
# build dataset
multi_modal_dataset = ModalToTextSFTDataset(**configs.train_dataset)
# iterate dataset
for item in multi_modal_dataset:
print(len(item))
break
# 5, output 5 columns
模型推理数据处理
Cogvlm2-Video模型推理配置文件中数据处理模块的配置如下:
predict_cogvlm2_video_llama3_chat_13b.yaml
processor:
type: BaseXModalToTextProcessor
model_transform_template:
type: CogVLM2ContentTransformTemplate
output_columns: [ "input_ids", "position_ids", "images", "video_context_pos" ]
vstack_columns: [ "images", "video_context_pos" ]
signal_type: "chat"
pos_pad_length: 2048
tokenizer:
add_bos_token: False
add_eos_token: False
max_length: 2048
pad_token: "<|reserved_special_token_0|>"
vocab_file: "/path/tokenizer.model"
type: CogVLM2Tokenizer
其中,vocab_file为实际使用词表文件路径,其他参数为模型相关配置,用户可按需进行自定义配置。
下面是多模态数训练据处理示例代码,与训练数据不同的是,通过数据处理可以得到一个包含input_ids等处理后的数据的字典,而不是一个列表。
from mindformers.tools.register.config import MindFormerConfig
from mindformers.models.multi_modal.base_multi_modal_processor import BaseXModalToTextProcessor
from mindformers.models.cogvlm2.cogvlm2_tokenizer import CogVLM2Tokenizer
# build processor
configs = MindFormerConfig("configs/cogvlm2/predict_cogvlm2_video_llama3_chat_13b.yaml")
configs.processor.tokenizer = tokenizer = CogVLM2Tokenizer(**configs.processor.tokenizer)
processor = BaseXModalToTextProcessor(**configs.processor)
# process data
multi_modal_data = [
{'video': "/path/video.mp4"},
{'text': "Please describe this video."}
]
print(processor(multi_modal_data).keys())
# dict_keys(['input_ids', 'position_ids', 'images', 'video_context_pos'])
在实现多模态数据集构建以及数据处理模块之后,就可以得到多模态理解模型可以处理的数据,下面将介绍如何构建多模态大模型。
模型构建
多模态大模型通常包括非文本模态处理模块、跨模态交互模块以及文本生成模块三个部分,其中非文本模态处理模块通常为经过大规模数据预训练后的视觉模型, 文本生成模块通常为文本生成大模型,跨模态交互模块通常由多个线性层组成。
模型配置类
MindSpore Transformers中多模态理解模型相关参数主要通过模型配置类进行控制,下面以CogVLM2Config类为例介绍如何构建模型配置类,
具体实现可参考CogVLM2Config。
@MindFormerRegister.register(MindFormerModuleType.CONFIG)
class CogVLM2Config(PretrainedConfig):
def __init__(self,
vision_model: PretrainedConfig,
llm_model: PretrainedConfig,
**kwargs):
super().__init__(**kwargs)
self.vision_model = vision_model
self.llm_model = llm_model
参数说明:
@MindFormerRegister.register(MindFormerModuleType.CONFIG)主要用于注册自定义的模型配置类,注册后的模型配置类可在yaml文件中通过名称进行调用;vision_model和llm_model分别表示视觉模型以及文本生成模型的配置类,作为多模态理解模型配置类的入参,并在类初始化过程中对其进行处理;PretrainedConfig是所有模型配置的基类,具体可参考PretrainedConfig。
在配置文件中,按如下结构对模型进行配置, 具体实现可参考predict_cogvlm2_video_llama3_chat_13b.yaml。
model:
model_config:
type: MultiModalConfig
vision_model:
arch:
type: EVAModel
model_config:
type: EVA02Config
image_size: 224
patch_size: 14
hidden_size: 1792
num_hidden_layers: 63
...
llm_model:
arch:
type: CogVLM2VideoLM
model_config:
type: LlamaConfig
seq_length: 2048
hidden_size: 4096
num_layers: 32
...
arch:
type: CogVLM2ForCausalLM
在该配置文件中,将EVAModel、EVA02Config作为vision_model模型及其配置类,将CogVLM2VideoLM、LlamaConfig作为llm_model模型及其配置类,
由此构成多模态理解模型CogVLM2ForCausalLM,这些类都是MindSpore Transformers已实现的模块,下面将介绍如何实现自定义模块。
非文本模态处理模块
MindSpore Transformers提供ViT、EVA02等模型作为视觉信息处理模块,下面以EVA02模型为例介绍如何构建非文本模态处理模块,
具体可参考EVAModel
和EVA02Config。
from mindformers.tools.register import MindFormerRegister, MindFormerModuleType
from mindformers.models.modeling_utils import PreTrainedModel
from mindformers.models.eva02.eva_config import EVA02Config
class EVA02PreTrainedModel(PreTrainedModel):
config_class = EVA02Config
base_model_prefix = "eva02"
@MindFormerRegister.register(MindFormerModuleType.MODELS)
class EVAModel(EVA02PreTrainedModel):
def __init__(self, config=None):
config = config if config else EVA02Config()
super().__init__(config)
参数说明:
@MindFormerRegister.register(MindFormerModuleType.MODELS)主要用于注册自定义的模型类,注册后的模型类可在yaml文件中通过名称进行调用;EVA02PreTrainedModel继承自PreTrainedModel类,主要用于指定模型配置类以及模型参数名的前缀,EVAModel作为模型的具体实现,承自EVA02PreTrainedModel类,相关API说明可参考PreTrainedModel;EVAModel主要对数据中的视觉信息进行处理,将处理后的视觉特征输入跨模态交互模块。
跨模态交互模块
文本生成模块通常为经过预训练的大语言模型,而非文本模态处理模块为经过大规模非文本数据预训练后的模型,其输出特征和与文本特征中所包含的信息差异过大,无法直接输入到文本生成模块中进行推理,因此需要构造与文本生成模块相匹配的跨模态交互模块,将视觉特征处理为文本生成模块可处理的向量。
下面以CogVLM2-Video模型中的VisionMLPAdapter为例,介绍跨模态交互模块的结构与功能。
class VisionMLPAdapter(nn.Cell):
def __init__(self, vision_grid_size, vision_hidden_size, text_hidden_size, text_intermediate_size,
compute_dtype=ms.float16, param_init_type=ms.float16):
super().__init__()
self.grid_size = vision_grid_size
self.linear_proj = GLU(in_features=vision_hidden_size,
hidden_size=text_hidden_size,
intermediate_size=text_intermediate_size,
compute_dtype=compute_dtype, param_init_type=param_init_type)
self.conv = nn.Conv2d(in_channels=vision_hidden_size, out_channels=vision_hidden_size,
kernel_size=2, stride=2, dtype=param_init_type, has_bias=True).to_float(compute_dtype)
在VisionMLPAdapter中会将EVAModel的输出通过Linear、Conv2D等操作处理成与文本特征相同的维度,其中vision_hidden_size和text_hidden_size分别表示视觉和文本特征维度。
文本生成模块
MindSpore Transformers提供Llama2、Llama3等语言大模型作为文本生成模块,与非文本模态处理模块、跨模态交互模块共同构成多模态理解模型。
@MindFormerRegister.register(MindFormerModuleType.MODELS)
class MultiModalForCausalLM(BaseXModalToTextModel):
def __init__(self, config: MultiModalConfig, **kwargs):
super().__init__(config, **kwargs)
self.config = config
self.vision_model = build_network(config.vision_model)
self.llm_model = build_network(config.llm_model)
self.mlp_adapter = VisionMLPAdapter(**kwargs)
def prepare_inputs_for_generation(self, input_ids, **kwargs):
"""Prepare inputs for generation in inference."""
def prepare_inputs_for_predict_layout(self, input_ids, **kwargs):
"""Prepare inputs for generation in inference."""
def set_dynamic_inputs(self, **kwargs):
"""Set dynamic inputs for model."""
def construct(self, input_ids, **kwargs):
"""Model forward."""
参数说明:
MultiModalForCausalLM作为多模态理解模型类,继承自基类BaseXModalToTextModel,在该类构建过程中通过build_network和对应模块的配置,对非文本模态处理模块vision_model、文本生成模块llm_model以及跨模态交互模块VisionMLPAdapter进行初始化;prepare_inputs_for_generation方法可以对输入数据进行预处理,要求处理后的数据可通过construct方法实现模型推理;prepare_inputs_for_predict_layout方法用于构造模型可处理的数据,其返回值与construct方法入参对应,通过构造后的数据可实现模型编译;set_dynamic_inputs方法可以为模型入参中的部分数据配置动态shape;construct方法为所有模型通用接口,也是模型前向执行函数。
多模态理解模型实践
在实现多模态数据集、数据处理模块以及多模态理解模型构建之后,就可以通过模型配置文件启动模型预训练、微调、推理等任务,为此需要构建对应的模型配置文件。
具体模型配置文件可参考predict_cogvlm2_video_llama3_chat_13b.yaml和finetune_cogvlm2_video_llama3_chat_13b_lora.yaml分别对应模型推理和微调,其中参数具体含义可查阅配置文件说明。
在用户自定义的配置文件中model、processor、train_dataset等部分内容需要对应用户自定义的数据集、数据处理模块以及多模态理解模型进行设置。
编辑自定义的配置文件之后,参考CogVLM2-Video模型文档启动模型推理和微调任务即可。