Development Migration
![]()
This document describes how to develop and build foundation models based on MindFormers and complete basic adaptation to start the training and inference processes.
Building a Foundation Model Based on MindFormers
The basic components of a foundation model in MindFormers include the configurations, models, and tokenizers for large language models (LLMs). In addition, to use the run_mindformer.py unified script to start the training or inference process, you need to prepare the YAML configuration file for training or inference.
Writing Configurations
A model configuration is an instance that contains all information about a model. The __init__ methods of all models in MindFormers receive a model configuration instance as the input parameter. All submodules of the model are initialized based on the information contained in the configuration instance.
MindFormers provides the PretrainedConfig class, which provides some common configuration methods. The configuration classes of all models should be inherited from the PretrainedConfig class. Developers only need to define all configuration parameters that help build foundation models. Foundation models of the Transformer type have configuration parameters such as seq_length, hidden_size, num_layers, and num_heads, and foundation models of the text type have vocab_size in addition.
For details, see the configuration class LlamaConfig of the Llama model in MindFormers.
If your model is similar to a model in the library, you can reuse the same configurations as the model.
Writing a Model
The MindFormers foundation model is developed based on the MindSpore framework. If your model has been implemented based on PyTorch, see MindSpore Network Construction. Developers only need to pay attention to the implementation of the model network.
MindFormers provides the PretrainedModel class, which is responsible for storage model configurations and processing the methods of loading and saving models. All model classes must be inherited from the PretrainedModel class, and the model input must be the same. That is, the input parameters of the construct method of the model must be the same. For details about the input parameters and meanings, see the Llama model class LlamaForCausalLM in MindFormers. In addition, the model class must implement some abstract methods of the base class, including:
prepare_inputs_for_generation: method for building input for model inference.prepare_inputs_for_predict_layout: method for building virtual input for the distributed loading model weight.
For specific meanings, refer to the descriptions in LlamaForCausalLM.
If your model structure is similar to that of a model in the library, you can reuse the model.
Writing a Tokenizer (for LLMs)
A tokenizer is used to process input and output of LLMs. It is required in the workflow of LLMs.
MindFormers provides the PretrainedTokenizer and PretrainedTokenizerFast classes, which use Python only and use the Rust library, respectively. The features of the latter one are as follows:
Faster batch processing.
Additional methods for mapping between text strings and lexical spaces. For example, the indexes of the lexical element containing a given character or the character spans corresponding to the given lexical element are obtained.
All tokenizer classes must be inherited from the PretrainedTokenizer or PretrainedTokenizerFast class. For details, see LlamaTokenizer and LlamaTokenizerFast.
If your tokenizer is similar to that in the library, you can reuse that in the library.
Preparing a Weight and a Dataset
If a PyTorch-based model weight already exists, you can convert the weight to that in the MindSpore format by referring to Weight Conversion.
For details about how to prepare a dataset, see Dataset or the model document, for example, Llama2 Description Document > Dataset Preparation.
Preparing a YAML File
MindFormers uses a YAML file to configure all parameters required by a task, including model parameters, training parameters (such as optimizer, learning rate, and dataset), inference parameters (such as tokenizer), distributed parallel parameters, and context environment parameters.
The code of the customized model is not in the MindFormers library, and the customized module in the code is not registered with MindFormers. Therefore, the customized model cannot be automatically instantiated. The code is also called external code (for example, the code in the research directory). Therefore, you need to add the auto_register configuration item for automatically registering any module to the corresponding module configuration in the YAML file and set the configuration items to the relative import paths of the API to be registered. When the run_mindformer.py script is executed to start the task, you need to add the input parameter --register_path of the registration path and set it to the relative path of the directory where the external code is located.
For example, in the YAML file research/llama3_1/predict_llama3_1_8b.yaml of the Llama3.1-8B model inference in the research directory, the configuration item auto_register is added for automatic registration to register the customized Llama3Tokenizer in research/llama3_1/llama3_1_tokenizer.py.
...
processor:
return_tensors: ms
tokenizer:
model_max_length: 8192
vocab_file: "/path/tokenizer.json"
pad_token: "<|reserved_special_token_0|>"
type: Llama3Tokenizer
auto_register: llama3_1_tokenizer.Llama3Tokenizer
type: LlamaProcessor
...
The relative import path auto_register: llama3_1_tokenizer.Llama3Tokenizer of Llama3Tokenizer is configured under tokenizer.
Run the following command to start the inference job:
python run_mindformer.py --config research/llama3_1/predict_llama3_1_8b.yaml --load_checkpoint path/to/llama3_1_8b.ckpt --register_path research/llama3_1 --predict_data "hello"
Parameters
Parameter |
Description |
|---|---|
config |
Path of the |
load_checkpoint |
Loaded weight path. |
register_path |
Path of the directory where the external code is located. |
predict_data |
Input data for inference. |
register_path is set to research/llama3_1 (path of the directory where the external code is located). For details about how to prepare the model weight, see Llama3.1 Description Document > Model Weight Download.
For details about the configuration file and configurable items, see Configuration File Descriptions. When compiling a configuration file, you can refer to an existing configuration file in the library, for example, Llama2-7B fine-tuning configuration file.
After all the preceding basic elements are prepared, you can refer to other documents in the MindFormers tutorial to perform model training, fine-tuning, and inference. For details about subsequent model debugging and optimization, see Large Model Accuracy Optimization Guide and Large Model Performance Optimization Guide.
Contributing Models to the MindFormers Open Source Repository
You can contribute models to the MindFormers open source repository for developers to research and use. For details, see MindFormers Contribution Guidelines.
MindFormers Model Migration Practice
Migration from Llama2-7B to Llama3-8B
Llama3-8B and Llama2-7B have the same model structure but different model parameters, tokenizers, and weights.
Model Configurations
The following compares the model configurations between Llama2-7B and Llama3-8B.
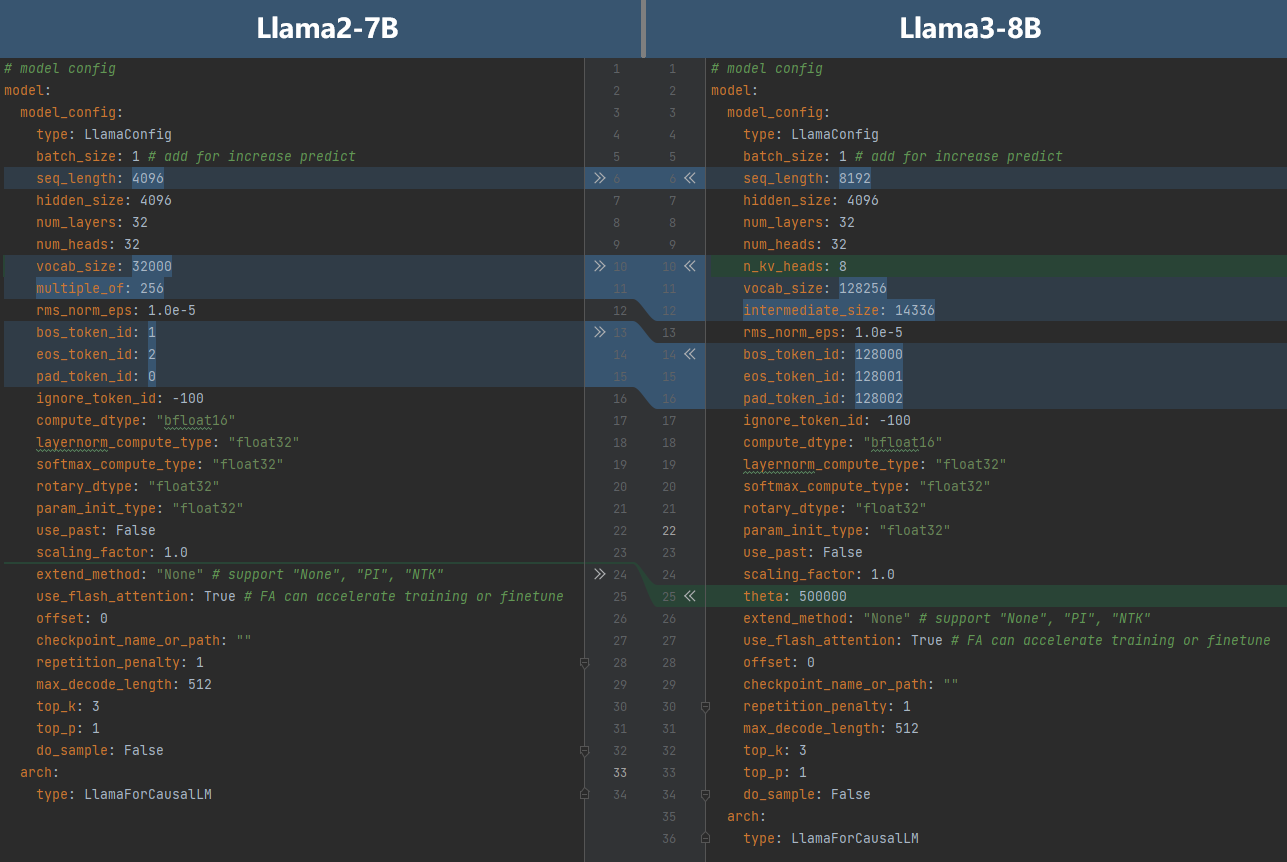
The differences are as follows:
The sequence length of Llama3-8B is 8192. Therefore,
seq_lengthis set to8192.Llama3-8B uses GQA and the number of heads in each key-value group is 8. Therefore,
n_kv_headis set to8.The size of the Llama3-8B vocabulary is 128,256. Therefore,
vocab_sizeis set to128256.Llama3-8B expands the hidden layer size of the feed-forward network to 14,336. Therefore,
intermediate_sizeis set to14336.In Llama3-8B, the special word metaindex is modified. Therefore,
bos_token_idis set to128000,eos_token_idis set to128001, andpad_token_idis set to128002.In Llama3-8B, the value of theta in the rotation position code is changed to 500000. Therefore,
thetais set to500000.
After modifying the corresponding content in the YAML file of Llama2-7B, you can obtain the Llama3-8B configuration file.
Tokenizer
Llama3-8B re-implements the tokenizer. According to the official implementation, PretrainedTokenizer is inherited from MindFormers to implement Llama3Tokenizer, which is written in llama3_tokenizer.py.
Weight Conversion
The parameters of Llama3-8B are the same as those of Llama2-7B. Therefore, the weight conversion process of Llama2-7B can be reused. For details, see Llama3 Document > Weight Conversion.
Dataset Processing
The tokenizer of Llama3-8B is different from that of Llama2-7B. Therefore, you need to replace the tokenizer of Llama3-8B to preprocess data based on the dataset processing script of Llama2-7B. For details, see conversation.py and llama_preprocess.py.
For details about the implementation of Llama3 in MindFormers, see Llama3 folder in the MindFormers repository. For details about how to use Llama3 in MindFormers, see LLama3 documents.