使用C++接口执行云侧推理
![]()
概述
本教程介绍如何使用C++接口执行MindSpore Lite云侧推理。
MindSpore Lite云侧推理仅支持在Linux环境部署运行。支持Atlas 200/300/500推理产品、Atlas推理系列产品(配置Ascend310P AI 处理器)、Atlas训练系列产品、Nvidia GPU和CPU硬件后端。
如需体验MindSpore Lite端侧推理流程,请参考文档使用C++接口执行端侧推理。
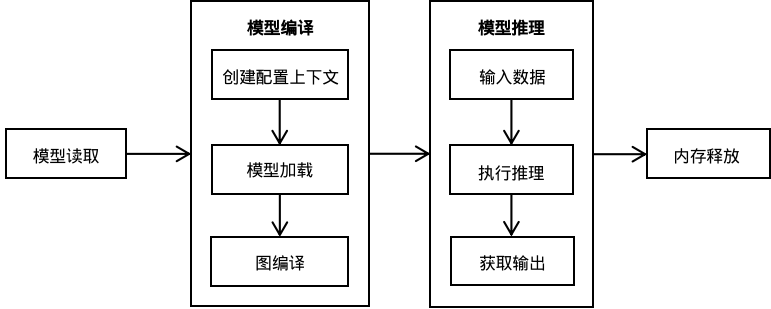
使用MindSpore Lite推理框架主要包括以下步骤:
模型读取:通过MindSpore导出MindIR模型,或者由模型转换工具转换获得MindIR模型。
创建配置上下文:创建配置上下文Context,保存需要的一些基本配置参数,用于指导模型编译和模型执行。
模型加载与编译:执行推理之前,需要调用Model的Build接口进行模型加载和模型编译。模型加载阶段将文件缓存解析成运行时的模型。模型编译阶段会耗费较多时间所以建议Model创建一次,编译一次,多次推理。
输入数据:模型执行之前需要填充输入数据。
准备工作
以下代码样例来自于使用C++接口执行云侧推理示例代码。
通过MindSpore导出MindIR模型,或者由模型转换工具转换获得MindIR模型,并将其拷贝到
mindspore/lite/examples/cloud_infer/runtime_cpp/model目录,可以下载MobileNetV2模型文件mobilenetv2.mindir。从官网下载Ascend、Nvidia GPU、CPU三合一的MindSpore Lite云侧推理包
mindspore-lite-{version}-linux-{arch}.tar.gz,并存放到mindspore/lite/examples/cloud_infer/runtime_cpp目录。
创建配置上下文
上下文会保存一些所需的基本配置参数,用于指导模型编译和模型执行。
下面示例代码演示了如何创建Context。
auto context = std::make_shared<mindspore::Context>();
if (context == nullptr) {
std::cerr << "New context failed." << std::endl;
return nullptr;
}
auto &device_list = context->MutableDeviceInfo();
通过MutableDeviceInfo返回后端信息列表的引用,指定运行的设备。MutableDeviceInfo中支持用户设置设备信息,包括CPUDeviceInfo、GPUDeviceInfo、AscendDeviceInfo。设置的设备个数当前只能为其中一个。
配置使用CPU后端
当需要执行的后端为CPU时,需要设置CPUDeviceInfo为推理后端。通过SetEnableFP16使能float16推理。
auto context = std::make_shared<mindspore::Context>();
if (context == nullptr) {
std::cerr << "New context failed." << std::endl;
return nullptr;
}
auto &device_list = context->MutableDeviceInfo();
auto cpu_device_info = std::make_shared<mindspore::CPUDeviceInfo>();
if (cpu_device_info == nullptr) {
std::cerr << "New CPUDeviceInfo failed." << std::endl;
return nullptr;
}
// CPU use float16 operator as priority.
cpu_device_info->SetEnableFP16(true);
device_list.push_back(cpu_device_info);
可选择性地额外设置线程数、线程亲和性、并行策略等特性。
配置线程数
Context通过SetThreadNum配置线程数:
// Configure the number of worker threads in the thread pool to 2, including the main thread. context->SetThreadNum(2);
配置线程亲和性
Context通过SetThreadAffinity配置线程和CPU绑定。 通过参数
const std::vector<int> &core_list设置绑核列表。// Configure the thread to be bound to the core list. context->SetThreadAffinity({0,1});
配置并行策略
Context通过SetInterOpParallelNum设置运行时的算子并行推理数目。
// Configure the inference supports parallel. context->SetInterOpParallelNum(2);
配置使用GPU后端
当需要执行的后端为GPU时,需要设置GPUDeviceInfo为推理后端。其中GPUDeviceInfo通过SetDeviceID来设置设备ID,通过SetEnableFP16或者SetPrecisionMode使能float16推理。
下面示例代码演示如何创建GPU推理后端,同时设备ID设置为0:
auto context = std::make_shared<mindspore::Context>();
if (context == nullptr) {
std::cerr << "New context failed." << std::endl;
return nullptr;
}
auto &device_list = context->MutableDeviceInfo();
auto gpu_device_info = std::make_shared<mindspore::GPUDeviceInfo>();
if (gpu_device_info == nullptr) {
std::cerr << "New GPUDeviceInfo failed." << std::endl;
return nullptr;
}
// Set NVIDIA device id.
gpu_device_info->SetDeviceID(0);
// GPU use float16 operator as priority.
gpu_device_info->SetEnableFP16(true);
// The GPU device context needs to be push_back into device_list to work.
device_list.push_back(gpu_device_info);
SetEnableFP16属性是否设置成功取决于当前设备的CUDA计算能力。
用户可通过调用 SetPrecisionMode()接口配置精度模式,设置 SetPrecisionMode("preferred_fp16") 时,同时 SetEnableFP16(true) 会自动设置,反之亦然。
SetPrecisionMode() |
SetEnableFP16() |
|---|---|
enforce_fp32 |
false |
preferred_fp16 |
true |
配置使用Ascend后端
当需要执行的后端为Ascend时(目前支持Atlas 200/300/500推理产品、Atlas推理系列产品(配置Ascend310P AI 处理器)、Atlas训练系列产品),需要设置AscendDeviceInfo为推理后端。其中AscendDeviceInfo通过SetDeviceID来设置设备ID。Ascend默认使能float16精度,可通过AscendDeviceInfo.SetPrecisionMode更改精度模式。
下面示例代码演示如何创建Ascend推理后端,同时设备ID设置为0:
auto context = std::make_shared<mindspore::Context>();
if (context == nullptr) {
std::cerr << "New context failed." << std::endl;
return nullptr;
}
auto &device_list = context->MutableDeviceInfo();
// for Atlas 200/300/500 inference product, Atlas inference series (with Ascend 310P AI processor), Atlas training series
auto device_info = std::make_shared<mindspore::AscendDeviceInfo>();
if (device_info == nullptr) {
std::cerr << "New AscendDeviceInfo failed." << std::endl;
return nullptr;
}
// Set Atlas 200/300/500 inference product, Atlas inference series (with Ascend 310P AI processor), Atlas training series device id.
device_info->SetDeviceID(device_id);
// The Ascend device context needs to be push_back into device_list to work.
device_list.push_back(device_info);
在Ascend弹性加速服务(拉远模式)环境运行推理:
// Set the provider to ge.
device_info->SetProvider("ge");
用户可通过调用 SetPrecisionMode()接口配置精度模式,使用场景如下表所示:
用户配置precision mode参数 |
ACL实际获取precision mode参数 |
ACL使用场景说明 |
|---|---|---|
enforce_fp32 |
force_fp32 |
强制使用 fp32 |
preferred_fp32 |
allow_fp32_to_fp16 |
优先使用 fp32 |
enforce_fp16 |
force_fp16 |
强制使用 fp16 |
enforce_origin |
must_keep_origin_dtype |
强制使用 初始类型 |
preferred_optimal |
allow_mix_precision |
优先使用 fp16+精度权衡 |
模型创建加载与编译
使用MindSpore Lite执行推理时,Model是推理的主入口,通过Model可以实现模型加载、模型编译和模型执行。采用上一步创建得到的Context,调用Model的复合Build接口来实现模型加载与模型编译。
下面示例代码演示了Model创建、加载与编译的过程:
std::shared_ptr<mindspore::Model> BuildModel(const std::string &model_path, const std::string &device_type,
int32_t device_id) {
// Create and init context, add CPU device info
auto context = std::make_shared<mindspore::Context>();
if (context == nullptr) {
std::cerr << "New context failed." << std::endl;
return nullptr;
}
auto &device_list = context->MutableDeviceInfo();
std::shared_ptr<mindspore::DeviceInfoContext> device_info = nullptr;
if (device_type == "CPU") {
device_info = CreateCPUDeviceInfo();
} else if (device_type == "GPU") {
device_info = CreateGPUDeviceInfo(device_id);
} else if (device_type == "Ascend") {
device_info = CreateAscendDeviceInfo(device_id);
}
if (device_info == nullptr) {
std::cerr << "Create " << device_type << "DeviceInfo failed." << std::endl;
return nullptr;
}
device_list.push_back(device_info);
// Create model
auto model = std::make_shared<mindspore::Model>();
if (model == nullptr) {
std::cerr << "New Model failed." << std::endl;
return nullptr;
}
// Build model
auto build_ret = model->Build(model_path, mindspore::kMindIR, context);
if (build_ret != mindspore::kSuccess) {
std::cerr << "Build model failed." << std::endl;
return nullptr;
}
return model;
}
针对大模型,使用model buffer进行加载编译的时候需要单独设置权重文件的路径,通过LoadConfig或UpdateConfig接口设置模型路径,其中
section为model_file,key为mindir_path;使用model path进行加载编译的时候不需要设置其他参数,会自动读取权重参数。
输入数据
在模型执行前,需要设置输入数据,使用GetInputs方法,直接获取所有的模型输入Tensor的vector。可以通过MSTensor的DataSize方法来获取Tensor应该填入的数据大小,通过DataType方法来获取Tensor的数据类型,通过SetData方法设置输入host数据。
当前有两种指定输入数据的方式:
通过SetData设置输入数据,可以避免host之间的拷贝,输入数据将最终直接拷贝到推理设备上。
int SetTensorHostData(std::vector<mindspore::MSTensor> *tensors, std::vector<MemBuffer> *buffers) { if (!tensors || !buffers) { std::cerr << "Argument tensors or buffers cannot be nullptr" << std::endl; return -1; } if (tensors->size() != buffers->size()) { std::cerr << "tensors size " << tensors->size() << " != " << " buffers size " << buffers->size() << std::endl; return -1; } for (size_t i = 0; i < tensors->size(); i++) { auto &tensor = (*tensors)[i]; auto &buffer = (*buffers)[i]; if (tensor.DataSize() != buffer.size()) { std::cerr << "Tensor data size " << tensor.DataSize() << " != buffer size " << buffer.size() << std::endl; return -1; } // set tensor data, and the memory should be freed by user tensor.SetData(buffer.data(), false); tensor.SetDeviceData(nullptr); } return 0; } auto inputs = model->GetInputs(); // Set the input data of the model, this inference input will be copied directly to the device. SetTensorHostData(&inputs, &input_buffer);
将输入数据拷贝到MutableData返回的Tensor缓存中。注意,如果已通过
SetData设置过数据地址,则MutableData返回的将是SetData的数据地址,此时需要先调用SetData(nullptr)。int CopyTensorHostData(std::vector<mindspore::MSTensor> *tensors, std::vector<MemBuffer> *buffers) { for (size_t i = 0; i < tensors->size(); i++) { auto &tensor = (*tensors)[i]; auto &buffer = (*buffers)[i]; if (tensor.DataSize() != buffer.size()) { std::cerr << "Tensor data size " << tensor.DataSize() << " != buffer size " << buffer.size() << std::endl; return -1; } auto dst_mem = tensor.MutableData(); if (dst_mem == nullptr) { std::cerr << "Tensor MutableData return nullptr" << std::endl; return -1; } memcpy(tensor.MutableData(), buffer.data(), buffer.size()); } return 0; } auto inputs = model->GetInputs(); // Set the input data of the model, copy data to the tensor buffer of Model.GetInputs. CopyTensorHostData(&inputs, &input_buffer);
执行推理
调用Model.Predict接口执行推理,并对返回的输出结果进行后续处理。
int SpecifyInputDataExample(const std::string &model_path, const std::string &device_type, int32_t device_id,
int32_t batch_size) {
auto model = BuildModel(model_path, device_type, device_id);
if (model == nullptr) {
std::cerr << "Create and build model failed." << std::endl;
return -1;
}
auto inputs = model->GetInputs();
// InferenceApp is user-defined code. Users need to obtain inputs and process outputs based on
// the actual situation.
InferenceApp app;
// Obtain inputs. The input data for inference may come from the preprocessing result.
auto &input_buffer = app.GetInferenceInputs(inputs);
if (input_buffer.empty()) {
return -1;
}
// Set the input data of the model, this inference input will be copied directly to the device.
SetTensorHostData(&inputs, &input_buffer);
std::vector<mindspore::MSTensor> outputs;
auto predict_ret = model->Predict(inputs, &outputs);
if (predict_ret != mindspore::kSuccess) {
std::cerr << "Predict error " << predict_ret << std::endl;
return -1;
}
// Process outputs.
app.OnInferenceResult(outputs);
return 0;
}
编译和执行
按照快速入门环境变量一节所述,设置环境变量。接着按如下方式编译程序:
mkdir build && cd build
cmake ../
make
在编译成功后,可以在build目录下得到runtime_cpp可执行程序。执行程序runtime_cpp运行样例:
./runtime_cpp --model_path=../model/mobilenetv2.mindir --device_type=CPU
高级用法
动态shape输入
Lite云侧推理框架支持动态shape输入的模型,GPU和Ascend硬件后端,需要在模型转换和模型推理时配置动态输入信息。
动态输入信息的配置与离线和在线场景有关。离线场景,模型转换工具参数--optimize=general,--optimize=gpu_oriented或--optimize=ascend_oriented,即经历和硬件相关的融合和优化,产生的MindIR模型仅能在对应硬件后端上运行,比如,在Atlas 200/300/500推理产品环境上,模型转换工具指定--optimize=ascend_oriented,则产生的模型仅支持在Atlas 200/300/500推理产品上运行,如果指定--optimize=general,则支持在GPU和CPU上运行。在线场景,加载的MindIR没有经历和硬件相关的融合和优化,支持在Ascend、GPU和CPU上运行,模型转换工具参数--optimize=none,或MindSpore导出的MindIR模型没有经过转换工具处理。
Ascend硬件后端离线场景下,需要在模型转换阶段配置动态输入信息。Ascend硬件后端在线场景下,以及GPU硬件后端离线和在线场景下,需要在模型加载阶段通过LoadConfig接口配置动态输入信息。
通过LoadConfig加载的配置文件示例如下所示:
[ascend_context]
input_shape=input_1:[-1,3,224,224]
dynamic_dims=[1~4],[8],[16]
[gpu_context]
input_shape=input_1:[-1,3,224,224]
dynamic_dims=[1~16]
opt_dims=[1]
[ascend_context]和[gpu_context]分别作用于Ascend和GPU硬件后端。
Ascend和GPU硬件后端需要通过动态输入信息进行图的编译和优化,CPU硬件后端不需要配置动态维度信息。
input_shape用于指示输入shape信息,格式为input_name1:[shape1];input_name2:[shape2],如果有动态输入,则需要将相应的维度设定为-1,多个输入通过英文分号;隔开。dynamic_dims用于指示动态维度的值范围,多个非连续的值范围通过英文逗号,隔开。上例子中,Ascend的batch维度值范围为1,2,3,4,8,16,GPU的batch维度值范围为1到16。Ascend硬件后端,动态输入为多档模式,动态输入范围越大,模型编译时间越长。对于GPU硬件后端,需要额外配置
opt_dims用于指示dynamic_dims范围中最优的值。如果
input_shape配置的为静态shape,则不需要配置dynamic_dims和opt_dims。
在模型Build前,通过LoadConfig加载配置文件信息:
// Create model
auto model = std::make_shared<mindspore::Model>();
if (model == nullptr) {
std::cerr << "New Model failed." << std::endl;
return nullptr;
}
if (!config_file.empty()) {
if (model->LoadConfig(config_file) != mindspore::kSuccess) {
std::cerr << "Failed to load config file " << config_file << std::endl;
return nullptr;
}
}
// Build model
auto build_ret = model->Build(model_path, mindspore::kMindIR, context);
if (build_ret != mindspore::kSuccess) {
std::cerr << "Build model failed." << std::endl;
return nullptr;
}
在模型推理时,如果模型的输入是动态的,通过GetInputs和GetOutputs返回的输入输出shape可能包括-1,即为动态shape,则需要通过Resize接口指定输入shape。如果输入Shape需要发生变化,比如batch维度发生变化,则需要重新调用Resize接口调整输入shape。
调用Resize接口后,已调用和后续调用的GetInputs和GetOutputs中的Tensor的shape将发生变化。
下面示例代码演示如何对MindSpore Lite的输入Tensor进行Resize:
int ResizeModel(std::shared_ptr<mindspore::Model> model, int32_t batch_size) {
std::vector<std::vector<int64_t>> new_shapes;
auto inputs = model->GetInputs();
for (auto &input : inputs) {
auto shape = input.Shape();
shape[0] = batch_size;
new_shapes.push_back(shape);
}
if (model->Resize(inputs, new_shapes) != mindspore::kSuccess) {
std::cerr << "Failed to resize to batch size " << batch_size << std::endl;
return -1;
}
return 0;
}
指定输入输出host内存
指定设备内存支持CPU、Asend和GPU硬件后端。指定的输入host内存,缓存中的数据将直接拷贝到设备(device)内存上,指定的输出host内存,设备(device)内存的数据将直接拷贝到这块缓存中。避免了额外的host之间的数据拷贝,提升推理性能。
通过SetData可单独或者同时指定输入和输出host内存。建议参数own_data为false,当own_data为false,用户需要维护host内存的生命周期,负责host内存的申请和释放。当参数own_data为true时,在MSTensor析构时释放指定的内存。
指定输入host内存
输入host内存的值,一般来源于host侧的C++、Python等预处理的结果。
std::vector<void *> host_buffers; // ... get host buffer from preprocessing etc. // Get Input auto inputs = model->GetInputs(); for (size_t i = 0; i < tensors.size(); i++) { auto &tensor = tensors[i]; auto host_data = host_buffers[i]; tensor.SetData(host_data, false); tensor.SetDeviceData(nullptr); } std::vector<mindspore::MSTensor> outputs; if (model->Predict(inputs, &outputs) != 0) { return -1; }
指定输出host内存
// Get Output from model auto outputs = model->GetOutputs(); std::vector<void *> output_buffers; ResourceGuard output_device_rel([&output_buffers]() { for (auto &item : output_buffers) { free(item); } }); for (auto &tensor : outputs) { auto buffer = malloc(tensor.DataSize()); tensor.SetData(buffer, false); tensor.SetDeviceData(nullptr); output_buffers.push_back(buffer); // for free } if (model->Predict(inputs, &outputs) != 0) { return -1; }
指定输入输出设备(device)内存
指定设备内存支持Asend和GPU硬件后端。指定输入输出设备内存可以避免device到host内存之间的相互拷贝,比如经过芯片dvpp预处理产生的device内存输入直接作为模型推理的输入,避免预处理结果从device内存拷贝到host内存,host结果作为模型推理输入,推理前重新拷贝到device上。
指定输入输出设备内存样例可参考设备内存样例。
通过SetDeviceData可单独或者同时指定输入和输出设备内存。用户需要维护设备内存的生命周期,负责设备内存的申请和释放。
指定输入设备内存
样例中,输入设备内存的值拷贝自host,一般设备内存的值来自于芯片预处理的结果或另一个模型的输出。
int SetDeviceData(std::vector<mindspore::MSTensor> tensors, const std::vector<uint8_t *> &host_data_buffer, std::vector<void *> *device_buffers) { for (size_t i = 0; i < tensors.size(); i++) { auto &tensor = tensors[i]; auto host_data = host_data_buffer[i]; auto data_size = tensor.DataSize(); if (data_size == 0) { std::cerr << "Data size cannot be 0, tensor shape: " << ShapeToString(tensor.Shape()) << std::endl; return -1; } auto device_data = MallocDeviceMemory(data_size); if (device_data == nullptr) { std::cerr << "Failed to alloc device data, data size " << data_size << std::endl; return -1; } device_buffers->push_back(device_data); if (CopyMemoryHost2Device(device_data, data_size, host_data, data_size) != 0) { std::cerr << "Failed to copy data to device, data size " << data_size << std::endl; return -1; } tensor.SetDeviceData(device_data); tensor.SetData(nullptr, false); } return 0; } // Get Input auto inputs = model->GetInputs(); std::vector<void *> device_buffers; ResourceGuard device_rel([&device_buffers]() { for (auto &item : device_buffers) { FreeDeviceMemory(item); } }); SetDeviceData(inputs, host_buffers, &device_buffers); std::vector<mindspore::MSTensor> outputs; if (Predict(model, inputs, &outputs) != 0) { return -1; }
指定输出设备内存
样例中,输出设备内存拷贝到host打印输出,一般输出设备内存可作为其他模型的输入。
int SetOutputDeviceData(std::vector<mindspore::MSTensor> tensors, std::vector<void *> *device_buffers) { for (size_t i = 0; i < tensors.size(); i++) { auto &tensor = tensors[i]; auto data_size = tensor.DataSize(); if (data_size == 0) { std::cerr << "Data size cannot be 0, tensor shape: " << ShapeToString(tensor.Shape()) << std::endl; return -1; } auto device_data = MallocDeviceMemory(data_size); if (device_data == nullptr) { std::cerr << "Failed to alloc device data, data size " << data_size << std::endl; return -1; } device_buffers->push_back(device_data); tensor.SetDeviceData(device_data); tensor.SetData(nullptr, false); } return 0; } // Get Output from model auto outputs = model->GetOutputs(); std::vector<void *> output_device_buffers; ResourceGuard output_device_rel([&output_device_buffers]() { for (auto &item : output_device_buffers) { FreeDeviceMemory(item); } }); if (SetOutputDeviceData(outputs, &output_device_buffers) != 0) { std::cerr << "Failed to set output device data" << std::endl; return -1; } if (Predict(model, inputs, &outputs) != 0) { return -1; }
Ascend后端GE推理
Ascend推理当前有两种对接方式。
一种为默认的ACL推理,ACL接口仅有全局和模型(图)级别的选项配置,多个图无法指示关联关系,多个图之间相对独立,不可共享权重(包括常量和变量)。如果模型存在可以变更的权重,即变量,变量需要先执行初始化,需要额外构建和执行初始化图,与计算图共享变量,由于多个图相对独立,使用默认的ACL推理时,模型不能存在变量。
ACL接口支持提前构建模型,加载时使用已构建的模型。
另一种为GE推理,GE接口存在全局、Session和模型(图)级别的选项配置,多个图可以在同一个Session中,在同一个Session中的图可以使能共享权重。在同一个Session中,可针对变量创建初始化图,与计算图共享变量。使用默认的GE推理时,模型可以存在变量。
当前GE接口不支持提前构建模型,加载时需要构建模型。
可以通过指定 provider 为 ge 使能GE。
import mindspore_lite as mslite
context = mslite.Context()
context.target = ["Ascend"]
context.ascend.device_id = 0
context.ascend.rank_id = 0
context.ascend.provider = "ge"
model = mslite.Model()
model.build_from_file("seq_1024.mindir", mslite.ModelType.MINDIR, context, "config.ini")
auto device_info = std::make_shared<mindspore::AscendDeviceInfo>();
if (device_info == nullptr) {
std::cerr << "New AscendDeviceInfo failed." << std::endl;
return -1;
}
// Set Atlas training series device id, rank id and provider.
device_info->SetDeviceID(0);
device_info->SetRankID(0);
device_info->SetProvider("ge");
// Device context needs to be push_back into device_list to work.
device_list.push_back(device_info);
mindspore::Model model;
if (model.LoadConfig("config.ini") != mindspore::kSuccess) {
std::cerr << "Failed to load config file " << "config.ini" << std::endl;
return -1;
}
// Build model
auto build_ret = model.Build("seq_1024.mindir", mindspore::kMindIR, context);
if (build_ret != mindspore::kSuccess) {
std::cerr << "Build model error " << build_ret << std::endl;
return -1;
}
在配置文件中,来自 [ge_global_options] 、 [ge_sesion_options] 和 [ge_graph_options] 中的选项将作为GE接口的全局、Session和模型(图)级别的选项,详情可参考GE选项。比如:
[ge_global_options]
ge.opSelectImplmode=high_precision
[ge_session_options]
ge.externalWeight=1
[ge_graph_options]
ge.exec.precision_mode=allow_fp32_to_fp16
ge.inputShape=x1:-1,3,224,224;x2:-1,3,1024,1024
ge.dynamicDims=1,1;2,2;3,3;4,4
ge.dynamicNodeType=1
多线程加载模型
硬件后端为Ascend,provider为默认时,支持多线程并发加载多个Ascend优化后模型,以提升模型加载性能。使用模型转换工具,指定 --optimize=ascend_oriented 可将MindSpore导出的 MindIR 模型、TensorFlow和ONNX等第三方框架模型转换为Ascend优化后模型。MindSpore导出的 MindIR 模型未进行Ascend优化,对于第三方框架模型,转换工具中如果指定 --optimize=none 产生的 MindIR 模型也未进行Ascend优化。
多模型共享权重
Ascend推理时,运行时指定 provider 为 ge 时,支持部署到同一张卡的多个模型共享权重,支持模型中存在可以被更新的权重。
针对相同的模型脚本,不同的条件分支或者不同的输入shape,使用相同的权重,可以导出不同的模型。多个模型共享权重时,在推理过程中,部分权重可以不再更新,我们将解析为常量,多个模型将拥有相同的常量权重。部分权重也可以发生变化,我们解析为变量,其中一个模型修改权重,本模型下次推理或其他模型推理可以使用和更新修改后的权重。
可以通过 ModelGroup 接口关联多个模型的共享权重的关系。
Python实现:
def load_model(model_path0, model_path1, config_file_0, config_file_1, rank_id, device_id):
context = mslite.Context()
context.ascend.device_id = device_id
context.ascend.rank_id = rank_id # for distributed model
context.ascend.provider = "ge"
context.target = ["Ascend"]
model0 = mslite.Model()
model1 = mslite.Model()
model_group = mslite.ModelGroup(mslite.ModelGroupFlag.SHARE_WEIGHT)
model_group.add_model([model0, model1])
model0.build_from_file(model_path0, mslite.ModelType.MINDIR, context, config_file_0)
model1.build_from_file(model_path1, mslite.ModelType.MINDIR, context, config_file_1)
return model0, model1
C++实现:
std::vector<Model> LoadModel(const std::string &model_path0, const std::string &model_path1,
const std::string &config_file_0, const std::string &config_file_1,
uint32_t rank_id, uint32_t device_id) {
auto context = std::make_shared<mindspore::Context>();
if (context == nullptr) {
std::cerr << "New context failed." << std::endl;
return {};
}
auto &device_list = context->MutableDeviceInfo();
auto device_info = std::make_shared<mindspore::AscendDeviceInfo>();
if (device_info == nullptr) {
std::cerr << "New AscendDeviceInfo failed." << std::endl;
return {};
}
device_info->SetDeviceID(device_id);
device_info->SetRankID(rank_id);
device_info->SetProvider("ge");
device_list.push_back(device_info);
mindspore::Model model0;
mindspore::Model model1;
mindspore::ModelGroup model_group(mindspore::ModelGroupFlag::kShareWeight);
model_group.AddModel({model0, model1});
if (!model0.LoadConfig(config_file_0).IsOk()) {
std::cerr << "Failed to load config file " << config_file_0 << std::endl;
return {};
}
if (!model0.Build(model_path0, mindspore::ModelType::kMindIR, context).IsOk()) {
std::cerr << "Failed to load model " << model_path0 << std::endl;
return {};
}
if (!model1.LoadConfig(config_file_1).IsOk()) {
std::cerr << "Failed to load config file " << config_file_1 << std::endl;
return {};
}
if (!model1.Build(model_path1, mindspore::ModelType::kMindIR, context).IsOk()) {
std::cerr << "Failed to load model " << model_path1 << std::endl;
return {};
}
return {model0, model1};
}
上述配置的默认情况下多个模型仅共享了变量,共享常量时,需要在配置文件中配置权重外置选项。配置文件即上述例子的 config_file_0 和 config_file_1 。
[ge_session_options]
ge.externalWeight=1
实验特性
多后端异构能力
MindSpore Lite云侧推理正在支持多后端异构场景,可以通过在运行期间指定环境变量‘export ENABLE_MULTI_BACKEND_RUNTIME=on’来使能该特性,其他接口的使用方式与原流程一致。当前该特性为实验特性,不保证特性的正确性,稳定性和后续的兼容性。