Performing Cloud-side Distributed Inference Using C++ Interface
![]()
Overview
For scenarios where large-scale neural network models have many parameters and cannot be fully loaded into a single device for inference, distributed inference can be performed using multiple devices. This tutorial describes how to perform MindSpore Lite cloud-side distributed inference using the C++ interface. Cloud-side distributed inference is roughly the same process as Cloud-side single-card inference and can be cross-referenced. For the basic concept of distributed inference, please refer to MindSpore Distributed inference, and MindSpore Lite cloud-side distributed inference has more optimization for performance aspects.
MindSpore Lite cloud-side distributed inference is only supported to run in Linux environment deployments with Ascend 910 and Nvidia GPU as the supported device types. As shown in the figure below, the distributed inference is currently initiated by a multi-process approach, where each process corresponds to a Rank in the communication set, loading, compiling and executing the respective sliced model, with the same input data for each process.
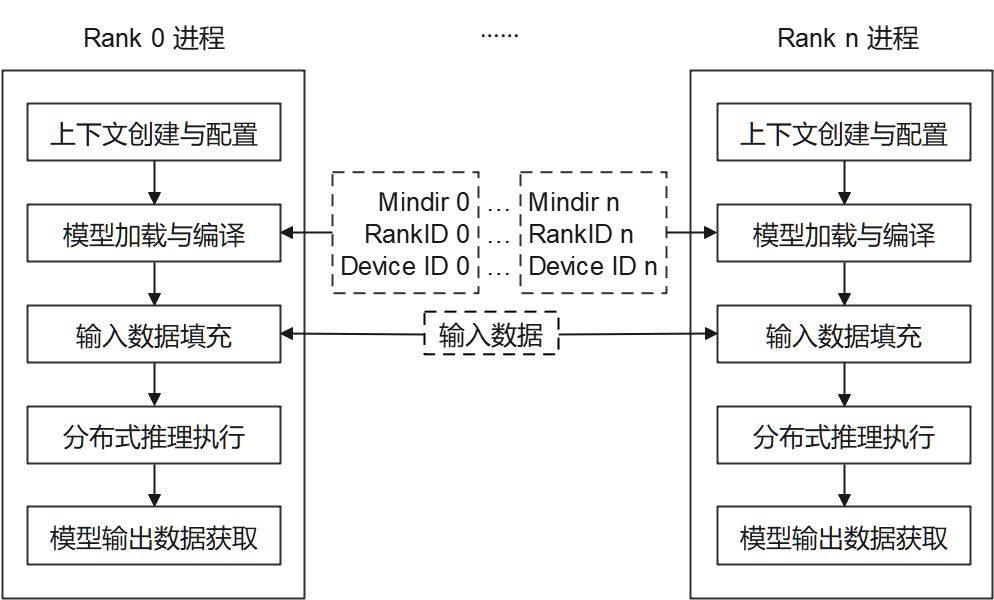
Each process consists of the following main steps:
Model reading: Slice and export the distributed MindIR model via MindSpore. The number of MindIR models is the same as the number of devices for loading to each device for inference.
Context creation and configuration: Create and configure the Context, and hold the distributed inference parameters to guide distributed model compilation and model execution.
Model loading and compilation: Use the Model::Build interface for model loading and model compilation. The model loading phase parses the file cache into a runtime model. The model compilation phase optimizes the front-end computational graph into a high-performance back-end computational graph. The process is time-consuming and it is recommended to compile once and inference multiple times.
Model input data padding.
Distributed inference execution: use the Model::Predict interface for model distributed inference.
Model output data obtaining.
Compilation and multi-process execution of distributed inference programs.
Preparation
To download the cloud-side distributed inference C++ sample code, please select the device type: Ascend or GPU. The directory will be referred to later as the example code directory.
Slice and export the distributed MindIR model via MindSpore and store it to the sample code directory. For a quick experience, you can download the two sliced Matmul model files Matmul0.mindir, Matmul1.mindir.
For Ascend device type, get the group network information file (such as
rank_ table_xxx.json) from Distributed parallel training base sample code. Refer to the Distributed Parallel Training Basic Sample for configuration, and store it in the sample code directory, and fill in the path of the file into the configuration fileconfig_file.iniin the sample code directory.Download the MindSpore Lite cloud-side inference installation package mindspore-lite-{version}-linux-{arch}.tar.gz and store it to the sample code directory. Unzip this installation package and refer to the Environment Variables section in the Quick Start to set environment variables.
The main steps of MindSpore Lite cloud-side distributed inference will be described in the subsequent sections in conjunction with the code, and please refer to main.cc in the sample code directory for the complete code.
Creating Contextual Configuration
The contextual configuration holds the required basic configuration parameters and distributed inference parameters to guide model compilation and model distributed execution. The following sample code demonstrates how to create a context through Context and specify a running device through Context:. MutableDeviceInfo to specify the running device.
// Create and init context, add Ascend device info
auto context = std::make_shared<mindspore::Context>();
if (context == nullptr) {
std::cerr << "New context failed." << std::endl;
return nullptr;
}
auto &device_list = context->MutableDeviceInfo();
Distributed inference scenarios support AscendDeviceInfo, GPUDeviceInfo, which are used to set Ascend and Nvidia GPU context information respectively.
Configuring Ascend Device Context
When the device type is Ascend (Ascend910 is currently supported by distributed inference), a new AscendDeviceInfo is created, and set DeviceID, RankID respectively by AscendDeviceInfo::SetDeviceID, AscendDeviceInfo::SetRankID. Since Ascend provides multiple inference engine backends, currently only the ge backend supports distributed inference, and the Ascend inference engine backend is specified as ge by DeviceInfoContext::SetProvider. The sample code is as follows.
// for Ascend 910
auto device_info = std::make_shared<mindspore::AscendDeviceInfo>();
if (device_info == nullptr) {
std::cerr << "New AscendDeviceInfo failed." << std::endl;
return nullptr;
}
// Set Ascend 910 device id, rank id and provider.
device_info->SetDeviceID(device_id);
device_info->SetRankID(rank_id);
device_info->SetProvider("ge");
// Device context needs to be push_back into device_list to work.
device_list.push_back(device_info);
Configuring GPU Device Context
When the device type is GPU, new GPUDeviceInfo is created. The distributed inference multi-process application for GPU devices is pulled up by mpi, which automatically sets the RankID of each process, and the user only needs to specify CUDA_VISIBLE_DEVICES in the environment variable, without specifying the group information file. Therefore, the RankID of each process can be used as DeviceID. In addition, GPU also provides multiple inference engine backends. Currently only tensorrt backend supports distributed inference, and the GPU inference engine backend is specified as tensorrt by DeviceInfoContext::SetProvider. The sample code is as follows.
// for GPU
auto device_info = std::make_shared<mindspore::GPUDeviceInfo>();
if (device_info == nullptr) {
std::cerr << "New GPUDeviceInfo failed." << std::endl;
return -1;
}
// set distributed info
auto rank_id = device_info->GetRankID(); // rank id is returned from mpi
device_info->SetDeviceID(rank_id); // as we set visible device id in env, we use rank id as device id
device_info->SetProvider("tensorrt");
device_list.push_back(device_info);
Model Creation, Loading and Compilation
Consistent with MindSpore Lite Cloud-side Single Card Inference, the main entry point for distributed inference is the Model interface for model loading, compilation and execution. For Ascend devices, use the Model::LoadConfig interface to load the configuration file config_file.ini, which is not required for GPU devices. Finally, call the Model::Build interface to implement model loading and model compilation, and the sample code is as follows.
mindspore::Model model;
// Load config file for Ascend910
if (!config_path.empty()) {
if (model.LoadConfig(config_path) != mindspore::kSuccess) {
std::cerr << "Failed to load config file " << config_path << std::endl;
return -1;
}
}
// Build model
auto build_ret = model.Build(model_path, mindspore::kMindIR, context);
if (build_ret != mindspore::kSuccess) {
std::cerr << "Build model error " << build_ret << std::endl;
return -1;
}
Model Input Data Padding
First, use the Model::GetInputs method to get all the input Tensor, and fill in the Host data through the MSTensor-related interface. The sample code is as follows.
// helper function
template <typename T, typename Distribution>
void GenerateRandomData(int size, void *data, Distribution distribution) {
std::mt19937 random_engine;
int elements_num = size / sizeof(T);
(void)std::generate_n(static_cast<T *>(data), elements_num,
[&distribution, &random_engine]() { return static_cast<T>(distribution(random_engine)); });
}
// Get input tensor pointer and write random data
int GenerateInputDataWithRandom(std::vector<mindspore::MSTensor> inputs) {
for (auto tensor : inputs) {
auto input_data = tensor.MutableData();
if (input_data == nullptr) {
std::cerr << "MallocData for inTensor failed." << std::endl;
return -1;
}
GenerateRandomData<float>(tensor.DataSize(), input_data, std::uniform_real_distribution<float>(1.0f, 1.0f));
}
return 0;
}
// Get Input
auto inputs = model.GetInputs();
// Generate random data as input data.
if (GenerateInputDataWithRandom(inputs) != 0) {
std::cerr << "Generate Random Input Data failed." << std::endl;
return -1;
}
Distributed Inference Execution
Create a model output Tensor of type MSTensor. Call the Model::Predict interface to perform distributed inference, with the following sample code.
// Model Predict
std::vector<mindspore::MSTensor> outputs;
auto predict_ret = model.Predict(inputs, &outputs);
if (predict_ret != mindspore::kSuccess) {
std::cerr << "Predict error " << predict_ret << std::endl;
return -1;
}
Model Output Data Obtaining
The model output data is stored in the output Tensor defined in the previous step, and the output data is accessible through the MSTensor-related interface. The following example code shows how to access the output data and print it.
// Print Output Tensor Data.
constexpr int kNumPrintOfOutData = 10;
for (auto &tensor : outputs) {
std::cout << "tensor name is:" << tensor.Name() << " tensor size is:" << tensor.DataSize()
<< " tensor elements num is:" << tensor.ElementNum() << std::endl;
auto out_data = reinterpret_cast<const float *>(tensor.Data().get());
std::cout << "output data is:";
for (int i = 0; i < tensor.ElementNum() && i <= kNumPrintOfOutData; i++) {
std::cout << out_data[i] << " ";
}
std::cout << std::endl;
}
Compiling and Performing Distributed Inference Example
In the sample code directory, compile the sample in the following way. Please refer to build.sh in the sample code directory for the complete command.
mkdir -p build
cd build || exit
cmake ..
make
After successful compilation, the {device_type}_{backend}_distributed_cpp executable programs is obtained in the build directory, and the distributed inference is started in the following multi-process manner. Please refer to run.sh in the sample code directory for the complete run command. When run successfully, the name, data size, number of elements and the first 10 elements of each output Tensor will be printed.
# for Ascend, run the executable file for each rank using shell commands
./build/ascend_ge_distributed /your/path/to/Matmul0.mindir 0 0 ./config_file.ini &
./build/ascend_ge_distributed /your/path/to/Matmul1.mindir 1 1 ./config_file.ini
# for GPU, run the executable file for each rank using mpi
RANK_SIZE=2
mpirun -n $RANK_SIZE ./build/gpu_trt_distributed /your/path/to/Matmul.mindir
Multiple Models Sharing Weights
In the Ascend device GE scenario, a single card can deploy multiple models, and models deployed to the same card can share weights. For details, please refer to Advanced Usage - Multiple Model Sharing Weights.