Applying the SCOP Algorithm
Background
Deep learning models such as a convolutional neural network (CNN) have been widely applied to multiple fields such as computer vision and natural language processing and have achieved great success. Due to that a neural network has high requirements on a computing capability and memory, it is difficult to directly deploy a neural network with powerful performance on an edge device such as a mobile phone or a wearable device. Therefore, a model compression method such as neural network pruning is very important for deploying a model on an edge device.
Pruning Method
Neural network pruning is a general model compression method. It reduces the number of parameters and computation workload by removing some parameters from the neural network. It is classified into unstructured pruning and structured pruning. Take the convolutional neural network (CNN) as an example. Unstructured pruning is to remove some weights from the convolution kernel. Although it can achieve a high compression ratio, the actual acceleration depends on the special hardware design. It is difficult to obtain benefits on the Ascend, GPU, and CPU platforms. Structured pruning directly removes the complete convolution kernel from the CNN without damaging the network topology. It can directly accelerate model inference without specific software and hardware design.
Finding a redundant convolution kernel is a key step in structured pruning. There are two common methods: In the first method, no training data is required, and the importance of different convolution kernels is determined by defining some assumptions about importance of the convolution kernels. A typical assumption is that a convolution kernel with a small norm is not important, and cutting off some convolution kernels with small norm does not affect network performance too much. Another method is data driven, in which training data is introduced to learn importance of different convolution kernels. For example, an additional control coefficient is introduced for each convolution kernel, and importance of different convolution kernels is measured by learning their control coefficients. A convolution kernel that corresponds to a small control coefficient is considered unimportant.
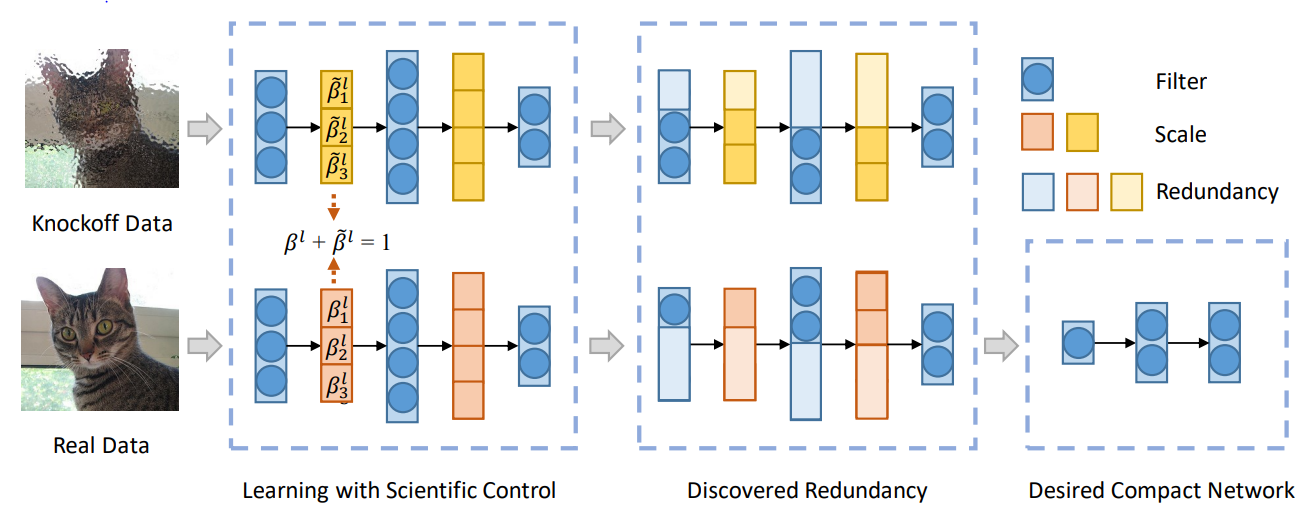
A typical neural network pruning method: Reliable Neural Network Pruning (SCOP) based on Scientific Control is driven by data. It introduces knockoff features as a reference, sets up control experiments to reduce the interference of various irrelevant factors to the pruning process and improve the reliability of pruning results. As shown in the preceding figure, real data and knockoff data are input to the network at the same time to generate real features and knockoff features separately. If the knockoff feature corresponding to a convolution kernel suppresses the real feature, the convolution kernel is considered redundant and should be deleted.
SCOP Training
The data-driven SCOP introduces training data to learn importance of different convolution kernels, thereby improving pruning reliability.
Table 1: SCOP training specifications
Specifications |
Description |
|---|---|
Hardware |
GPU and Atlas training series hardware platforms |
Networks |
ResNet series networks. For details, see https://gitee.com/mindspore/models/tree/master. |
Algorithms |
Structured pruning algorithms |
Data types |
The Ascend and the GPU platforms support pruning training on FP32 networks. |
Running modes |
Graph mode and PyNative mode |
SCOP Training Example
SCOP training consists of the knockoff and fine-tuning phases. In the knockoff phase, redundant convolution kernels are removed by using the knockoff feature. In the fine-tuning phase, the network is completely trained after the redundant convolution kernels are removed. The complete process is as follows:
Load the dataset and process data.
Initialize the ResNet-50.
Use PrunerKfCompressAlgo to replace nodes, define the optimizer and loss function, and perform training in the knockoff phase.
Use PrunerFtCompressAlgo to replace nodes, define the optimizer and loss function, perform training in the fine-tuning phase, and save the model.
Load the saved model for evaluation.
Then, ResNet-50 is used as an example to describe steps related to SCOP training in detail.
You can find the complete executable sample code here: https://gitee.com/mindspore/models/tree/master/official/cv/ResNet/golden_stick/pruner/scop.
Knockoff Data
Initialize the ResNet-50, load the pre-trained model, replace nodes using PrunerKfCompressAlgo to obtain the network in the knockoff phase (For details, users can refer to API), and train the network. (Note: dataset_sink_mode in Knockoff Data phase must be set to False, because SCOP will modify dataset in Knockoff Data phase)
from mindspore import ModelCheckpoint, CheckpointConfig, LossMonitor, TimeMonitor
from mindspore import FixedLossScaleManager
from mindspore_gs import PrunerKfCompressAlgo
from mindspore.models.resnet import resnet50
import mindspore.nn as nn
from copy import deepcopy
net = resnet50(10)
load_checkpoint(config.pre_trained, net=net)
algo_kf = PrunerKfCompressAlgo({})
net = algo_kf.apply(net) # Get knockoff stage network
lr = get_lr(lr_init=config.lr_init,
lr_end=0.0,
lr_max=config.lr_max_kf,
warmup_epochs=config.warmup_epochs,
total_epochs=config.epoch_kf,
steps_per_epoch=step_size,
lr_decay_mode='cosine')
optimizer = nn.Momentum(filter(lambda p: p.requires_grad, net.get_parameters()),
learning_rate=lr,
momentum=0.9,
loss_scale=1024
)
loss_fn = SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
time_cb = TimeMonitor(data_size=step_size)
loss_cb = LossMonitor()
algo_cb_list = algo_kf.callbacks()
cb = [loss_cb, time_cb]
cb += algo_cb_list
model = ms.Model(net, loss_fn=loss_fn, optimizer=optimizer)
model.train(config.epoch_kf, dataset, callbacks=cb, dataset_sink_mode=False)
The result is as follows:
step_0: loss=3.5922117
step_1: loss=5.259112
step_2: loss=5.152421
step_3: loss=3.2383142
step_4: loss=5.3319235
step_5: loss=4.715785
Fine-tuning
Determine the redundant convolution kernels in the knockoff phase. Use PrunerFtCompressAlgo to replace nodes (For details, users can refer to API) and delete redundant convolution kernels. Perform the complete training and save the model.
from mindspore_gs import PrunerFtCompressAlgo
...
algo_ft = PrunerFtCompressAlgo(prune_rate=config.prune_rate)
net = algo_ft.apply(net) # Get Finetune stage network
lr_ft_new = ms.Tensor(get_lr(lr_init=config.lr_init,
lr_end=config.lr_ft_end,
lr_max=config.lr_ft_max,
warmup_epochs=config.warmup_epochs,
total_epochs=config.epochs_ft,
steps_per_epoch=dataset.get_dataset_size(),
lr_decay_mode='poly'))
optimizer_ft = nn.Momentum(filter(lambda p: p.requires_grad, net.get_parameters()),
learning_rate=lr_ft_new,
momentum=config.momentum,
loss_scale=config.loss_scale
)
net.set_train()
metrics = {"acc"}
loss_scale = FixedLossScaleManager(1024, drop_overflow_update=False)
model_ft = ms.Model(net, loss_fn=loss_fn, optimizer=optimizer_ft, loss_scale_manager=loss_scale,
metrics=metrics,
amp_level="O2", boost_level="O0", keep_batchnorm_fp32=False) # Get Finetune stage model
step_size = dataset.get_dataset_size()
time_cb = TimeMonitor(data_size=step_size)
loss_cb = LossMonitor()
config_ck = CheckpointConfig(save_checkpoint_steps=5 * step_size,
keep_checkpoint_max=10)
ckpt_cb = ModelCheckpoint(prefix="resnet", directory=config.output_path,
config=config_ck)
ft_cb = [time_cb, loss_cb, ckpt_cb]
model_ft.train(config.epochs_ft, dataset, callbacks=ft_cb,
sink_size=dataset.get_dataset_size(), dataset_sink_mode=True)
The result is as follows:
epoch: 1 step: 1, loss is 1.776729941368103
epoch: 1 step: 2, loss is 2.481227159500122
epoch: 1 step: 3, loss is 2.010404586791992
epoch: 1 step: 4, loss is 1.852586030960083
epoch: 1 step: 5, loss is 1.4738214015960693
epoch: 1 step: 6, loss is 1.6637545824050903
epoch: 1 step: 7, loss is 1.7006491422653198
epoch: 1 step: 8, loss is 1.6532130241394043
epoch: 1 step: 9, loss is 1.5730770826339722
epoch: 1 step: 10, loss is 1.4364683628082275
epoch: 1 step: 11, loss is 1.572392225265503
Loading the Saved Model for Evaluation
from mindspore import Tensor, set_context, load_checkpoint, load_param_into_net, export
if __name__ == "__main__":
...
net = resnet(class_num=config.class_num)
net = PrunerKfCompressAlgo({}).apply(net)
net = PrunerFtCompressAlgo({}).apply(net)
# load checkpoint
param_dict = load_checkpoint(config.ckpt_path)
load_param_into_net(net, param_dict)
total_params = 0
for param in net.trainable_params():
total_params += np.prod(param.shape)
model = ms.Model(net, loss_fn=loss, metrics={'top_1_accuracy'})
# eval model
res = model.eval(dataset)
print("result:", res, "prune_rate=", config.prune_rate, "ckpt=", config.checkpoint_file_path, "params=", total_params)
The following are the accuracy (top_1_accuracy), pruning rate (prune_rate), model storage location (ckpt), and parameters (params) evaluated by the model:
result:{'top_1_accuracy': 0.9273838141025641} prune_rate=0.45 ckpt=~/resnet50_cifar10/train_parallel0/resnet-400_390.ckpt params=10587835
Exporting a Pruned Model
The quantization model deployed on the device-side hardware platform is in the general model format (such as AIR and MindIR). The export procedure is as follows:
Define a pruned network.
Load the checkpoint file saved during pruning-based training.
Export the pruned model.
from mindspore import Tensor, set_context, load_checkpoint, load_param_into_net, export
if __name__ == "__main__":
...
# define fusion network
net = resnet(class_num=config.class_num)
net = PrunerKfCompressAlgo({}).apply(net)
net = PrunerFtCompressAlgo({}).apply(net)
# load quantization aware network checkpoint
param_dict = load_checkpoint(config.ckpt_path)
load_param_into_net(net, param_dict)
# export network
inputs = Tensor(np.ones([1, 1, cfg.image_height, cfg.image_width]), mindspore.float32)
export(network, inputs, file_name="ResNet_SCOP", file_format='MINDIR')
After the pruned model is exported, use MindSpore for inference.
Summary
indicates not test yet, NS indicates not supported yet.
Summary of Training
Training in graph mode based on MindSpore, MindSpore Golden Stick, MindSpore Models.
algorithm |
network |
dataset |
CUDA11 Top1Acc |
CUDA11 Top5Acc |
Ascend910 Top1Acc |
Ascend910 Top5Acc |
pruning rate |
parameter size(MB) |
|---|---|---|---|---|---|---|---|---|
baseline |
resnet50 |
CIFAR10 |
94.20% |
99.88% |
- |
- |
NA |
24 |
SCOP |
resnet50 |
CIFAR10 |
92.74% |
- |
92.84% |
- |
45% |
11 |
baseline |
resnet50 |
Imagenet2012 |
77.16% |
93.47% |
- |
- |
NA |
- |
SCOP |
resnet50 |
Imagenet2012 |
NS |
NS |
NS |
NS |
NS |
NS |
It can be found that in the current task, compared with the original model, when the pruning rate is 45%, the model after SCOP greatly reduces the parameters of the model, and the accuracy loss is within 0.5%.