实现一个端云联邦的图像分类应用(x86)
![]()
根据参与客户端的类型,联邦学习可分为云云联邦学习(cross-silo)和端云联邦学习(cross-device)。在云云联邦学习场景中,参与联邦学习的客户端是不同的组织(例如,医疗或金融)或地理分布的数据中心,即在多个数据孤岛上训练模型。在端云联邦学习场景中,参与的客户端为大量的移动或物联网设备。本框架将介绍如何在MindSpore端云联邦框架上使用网络LeNet实现一个图片分类应用,并提供在x86环境中模拟启动多客户端参与联邦学习的相关教程。
在动手进行实践之前,确保你已经正确安装了MindSpore。如果没有,可以参考MindSpore安装页面完成安装。
准备工作
我们提供了可供用户直接使用的联邦学习图像分类数据集FEMNIST,以及.ms格式的端侧模型文件。用户也可以根据实际需求,参考以下教程自行生成数据集和模型。
数据处理
本示例采用leaf数据集中的联邦学习数据集FEMNIST, 数据集的具体获取方式可参考文档端云联邦学习图像分类数据集处理。
用户也可自行定义数据集,注意,数据集必须为.bin格式文件,且文件中数据维度必须与网络的输入维度保持一致。
生成端侧模型文件
定义网络和训练过程
具体网络和训练过程的定义可参考初学入门。
我们提供了网络定义文件model.py和训练过程定义文件run_export_lenet.py供大家参考。
将模型导出为MindIR格式文件。
运行脚本
run_export_lenet.py获取MindIR格式模型文件,其中代码片段如下:from mindspore import export ... parser = argparse.ArgumentParser(description="export mindir for lenet") parser.add_argument("--device_target", type=str, default="CPU") parser.add_argument("--mindir_path", type=str, default="lenet_train.mindir") # MindIR格式文件路径 ... for _ in range(epoch): data = Tensor(np.random.rand(32, 3, 32, 32).astype(np.float32)) label = Tensor(np.random.randint(0, 61, (32)).astype(np.int32)) loss = train_network(data, label).asnumpy() losses.append(loss) export(train_network, data, label, file_name= mindir_path, file_format='MINDIR') # 在训练过程中添加export语句获取MindIR格式模型文件 print(losses)
具体运行指令如下:
python run_export_lenet.py --mindir_path="ms/lenet/lenet_train.mindir"
参数
--mindir_path用于设置生成的MindIR格式文件路径。将MindIR文件转化为联邦学习端侧框架可用的ms文件。
模型转换可参考训练模型转换教程。
模型转换示例如下:
假设待转换的模型文件为
lenet_train.mindir,执行如下转换命令:./converter_lite --fmk=MINDIR --trainModel=true --modelFile=lenet_train.mindir --outputFile=lenet_train
转换成功输出如下:
CONVERTER RESULT SUCCESS:0
这表明MindSpore模型成功转换为MindSpore端侧模型,并生成了新文件
lenet_train.ms。如果转换失败输出如下:CONVERT RESULT FAILED:
将生成的
.ms格式的模型文件放在某个路径上,在调用联邦学习接口时可设置FLParameter.trainModelPath为该模型文件的路径。
模拟启动多客户端参与联邦学习
为客户端准备好模型文件。
由于真实场景一个客户端只包含一个.ms格式的模型文件,在模拟场景中,需要拷贝多份.ms文件,并按照
lenet_train{i}.ms格式进行命名。其中i代表客户端编号,由于run_client_x86.py中代码逻辑,i需要设置为0, 1, 2, 3, 4, 5 .....等数字。每个客户端各使用一份.ms文件。可参考下面脚本,对原始.ms文件进行拷贝和命名:
import shutil import os def copy_file(raw_path,new_path,copy_num): # Copy the specified number of files from the raw path to the new path for i in range(copy_num): file_name = "lenet_train" + str(i) + ".ms" new_file_path = os.path.join(new_path, file_name) shutil.copy(raw_path ,new_file_path) print('====== copying ',i, ' file ======') print("the number of copy .ms files: ", len(os.listdir(new_path))) if __name__ == "__main__": raw_path = "lenet_train.ms" new_path = "ms/lenet" num = 8 copy_file(raw_path, new_path, num)
其中
raw_path设置原始.ms文件路径,new_path设置拷贝的.ms文件需要放置的路径,num设置拷贝的份数,一般需要模拟启动客户端的数量。比如以上脚本中设置,在路径
ms/lenet中生成了供8个客户端使用的.ms文件,其目录结构如下:ms/lenet ├── lenet_train0.ms # 客户端0使用的.ms文件 ├── lenet_train1.ms # 客户端1使用的.ms文件 ├── lenet_train2.ms # 客户端2使用的.ms文件 │ │ ...... │ └── lenet_train7.ms # 客户端7使用的.ms文件
启动云侧服务
用户可先参考云侧部署教程部署云侧环境,并启动云侧服务。
启动客户端。
启动客户端之前请先参照端侧部署教程中x86环境部分进行端侧环境部署。
我们框架提供了三个类型的联邦学习接口供用户调用,具体的接口介绍可参考API文件:
SyncFLJob.flJobRun()用于启动客户端参与到联邦学习训练任务中,并获取最终训练好的聚合模型。
SyncFLJob.modelInfer()用于获取给定数据集的推理结果。
SyncFLJob.getModel()用于获取云侧最新的模型。
待云侧服务启动成功之后,可编写一个Python脚本,调用联邦学习框架jar包
mindspore-lite-java-flclient.jar和模型脚本对应的jar包quick_start_flclient.jar(可参考端侧部署中编译出包流程获取)来模拟启动多客户端参与联邦学习任务。我们提供了参考脚本run_client_x86.py,可通过相关参数的设置,来启动不同的联邦学习接口。
以LeNet网络为例,
run_client_x86.py脚本中部分入参含义如下,用户可根据实际情况进行设置:--jarPath设置联邦学习jar包路径,x86环境联邦学习jar包获取可参考端侧部署中编译出包流程。
注意,请确保该路径下仅包含该jar包。例如,在上面示例代码中,
--jarPath设置为"libs/jarX86/mindspore-lite-java-flclient.jar",则需确保jarX86文件夹下仅包含一个jar包mindspore-lite-java-flclient.jar。--case_jarPath设置模型脚本所生成的jar包
quick_start_flclient.jar的路径,x86环境联邦学习jar包获取可参考端侧部署中编译出包流程。注意,请确保该路径下仅包含该jar包。例如,在上面示例代码中,
--case_jarPath设置为"case_jar/quick_start_flclient.jar",则需确保case_jar文件夹下仅包含一个jar包quick_start_flclient.jar。--train_dataset训练数据集root路径,LeNet图片分类任务在该root路径中存放的是每个客户端的训练data.bin文件与label.bin文件,例如
data/femnist/3500_clients_bin/。--flName联邦学习使用的模型脚本包路径。我们提供了两个类型的模型脚本供大家参考(有监督情感分类任务、LeNet图片分类任务),对于有监督情感分类任务,该参数可设置为所提供的脚本文件AlBertClient.java 的包路径
com.mindspore.flclient.demo.albert.AlbertClient;对于LeNet图片分类任务,该参数可设置为所提供的脚本文件LenetClient.java 的包路径com.mindspore.flclient.demo.lenet.LenetClient。同时,用户可参考这两个类型的模型脚本,自定义模型脚本,然后将该参数设置为自定义的模型文件ModelClient.java(需继承于类Client.java)的包路径即可。--train_model_path设置联邦学习使用的训练模型路径,为上面教程中拷贝的多份.ms文件所存放的目录,比如
ms/lenet,必须为绝对路径。--train_ms_name设置多客户端训练模型文件名称相同部分,模型文件名需为格式
{train_ms_name}1.ms,{train_ms_name}2.ms,{train_ms_name}3.ms等。--domain_name用于设置端云通信url,目前,可支持https和http通信,对应格式分别为:https://……、http://……,当
if_use_elb设置为true时,格式必须为:https://127.0.0.1:6666 或者http://127.0.0.1:6666 ,其中127.0.0.1对应提供云侧服务的机器ip(即云侧参数--scheduler_ip),6666对应云侧参数--fl_server_port。注意1,当该参数设置为
http://......时代表使用HTTP通信,可能会存在通信安全风险,请知悉。注意2,当该参数设置为
https://......代表使用HTTPS通信。此时必须进行SSL证书认证,需要通过参数--cert_path设置证书路径。--task用于设置本此启动的任务类型,为
train代表启动训练任务,为inference代表启动多条数据推理任务,为getModel代表启动获取云侧模型的任务,设置其他字符串代表启动单条数据推理任务。默认为train。由于初始的模型文件(.ms文件)是未训练过的,建议先启动训练任务,待训练完成之后,再启动推理任务(注意两次启动的client_num保持一致,以保证inference使用的模型文件与train保持一致)。--batch_size设置联邦学习训练和推理时使用的单步训练样本数,即batch size。需与模型的输入数据的batch size保持一致。
--client_num设置client数量, 与启动server端时的
start_fl_job_cnt保持一致,真实场景不需要此参数。
若想进一步了解
run_client_x86.py脚本中其他参数含义,可参考脚本中注释部分。联邦学习接口基本启动指令示例如下:
python run_client_x86.py --jarPath="libs/jarX86/mindspore-lite-java-flclient.jar" --case_jarPath="case_jar/quick_start_flclient.jar" --train_dataset="data/femnist/3500_clients_bin/" --test_dataset="null" --vocal_file="null" --ids_file="null" --flName="com.mindspore.flclient.demo.lenet.LenetClient" --train_model_path="ms/lenet/" --infer_model_path="ms/lenet/" --train_ms_name="lenet_train" --infer_ms_name="lenet_train" --domain_name="http://127.0.0.1:6666" --cert_path="certs/https_signature_certificate/client/CARoot.pem" --use_elb="true" --server_num=4 --client_num=8 --thread_num=1 --server_mode="FEDERATED_LEARNING" --batch_size=32 --task="train"
注意,启动指令中涉及路径的必须给出绝对路径。
以上指令代表启动8个客户端参与联邦学习训练任务,若启动成功,会在当前文件夹生成8个客户端对应的日志文件,查看日志文件内容可了解每个客户端的运行情况:
./ ├── client_0 │ └── client.log # 客户端0的日志文件 │ ...... └── client_7 └── client.log # 客户端7的日志文件针对不同的接口和场景,只需根据参数含义,修改特定参数值即可,比如:
启动联邦学习训练任务SyncFLJob.flJobRun()
当
基本启动指令中--task设置为train时代表启动该任务。可通过指令
grep -r "average loss:" client_0/client.log查看client_0在训练过程中每个epoch的平均loss,会有类似如下打印:INFO: <FLClient> ----------epoch:0,average loss:4.1258564 ---------- ......
也可通过指令
grep -r "evaluate acc:" client_0/client.log查看client_0在每个联邦学习迭代中聚合后模型的验证精度,会有类似如下打印:INFO: <FLClient> [evaluate] evaluate acc: 0.125 ......
启动推理任务SyncFLJob.modelInference()
当
基本启动指令中--task设置为inference时代表启动该任务。可通过指令
grep -r "the predicted labels:" client_0/client.log查看client_0的推理结果:INFO: <FLClient> [model inference] the predicted labels: [0, 0, 0, 1, 1, 1, 2, 2, 2] ......
启动获取云侧最新模型任务SyncFLJob.getModel()
当
基本启动指令中--task设置为getModel时代表启动该任务。在日志文件中若有如下内容代表获取云侧最新模型成功:
INFO: <FLClient> [getModel] get response from server ok!
关闭客户端进程。
可参考finish.py脚本,具体如下:
import argparse import subprocess parser = argparse.ArgumentParser(description="Finish client process") # The parameter `--kill_tag` is used to search for the keyword to kill the client process. parser.add_argument("--kill_tag", type=str, default="mindspore-lite-java-flclient") args, _ = parser.parse_known_args() kill_tag = args.kill_tag cmd = "pid=`ps -ef|grep " + kill_tag cmd += " |grep -v \"grep\" | grep -v \"finish\" |awk '{print $2}'` && " cmd += "for id in $pid; do kill -9 $id && echo \"killed $id\"; done" subprocess.call(['bash', '-c', cmd])
关闭客户端指令如下:
python finish.py --kill_tag=mindspore-lite-java-flclient
其中参数
--kill_tag用于搜索该关键字对客户端进程进行kill,只需要设置--jarPath中的特殊关键字即可。默认为mindspore-lite-java-flclient,即联邦学习jar包名。 用户可通过指令ps -ef |grep "mindspore-lite-java-flclient"查看进程是否还存在。50个客户端参与联邦学习训练任务实验结果。
目前
3500_clients_bin文件夹中包含3500个客户端的数据,本脚本最多可模拟3500个客户端参与联邦学习。下图给出了50个客户端(设置
server_num为16)进行联邦学习的测试集精度: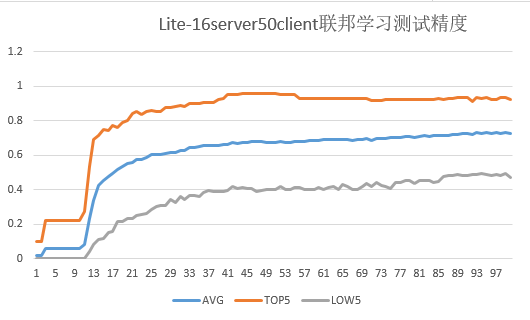
其中联邦学习总迭代数为100,客户端本地训练epoch数为20,batchSize设置为32。
图中测试精度指对于每个联邦学习迭代,各客户端测试集在云侧聚合后的模型上的精度。
AVG:对于每个联邦学习迭代,50个客户端测试集精度的平均值。
TOP5:对于每个联邦学习迭代,测试集精度最高的5个客户端的精度平均值。
LOW5:对于每个联邦学习迭代,测试集精度最低的5个客户端的精度平均值。