云侧部署
![]()
本文档以LeNet网络为例,讲解如何使用MindSpore部署联邦学习集群。
可以在这里下载本文档中的完整Demo。
MindSpore Federated Learning (FL) Server集群物理架构如图所示:
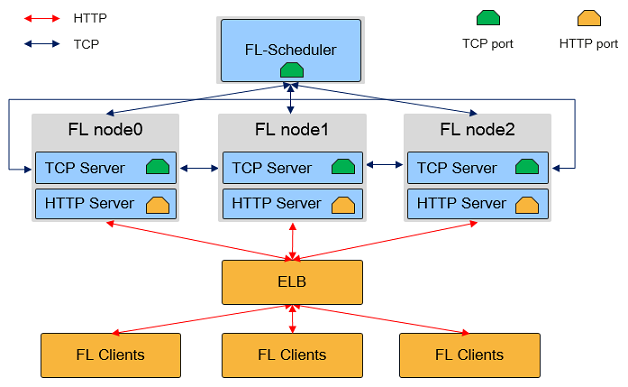
如上图所示,在联邦学习云侧集群中,有两种角色的MindSpore进程:Federated Learning Scheduler和Federated Learning Server:
Federated Learning Scheduler
Scheduler的功能主要包括:协助集群组网:在集群初始化阶段,由
Scheduler负责收集Server信息,并保障集群一致性。`开放管理面:向用户提供
RESTful接口,实现对集群的管理。
在一个联邦学习任务中,只有一个
Scheduler,其与Server通过TCP协议通信。Federated Learning Server
Server为执行联邦学习任务的主体,用于接收和解析端侧设备上传的数据,具有执行安全聚合、限时通信、模型存储等能力。在一个联邦学习任务中,Server可以有多个(用户可配置),Server间通过TCP协议通信,对外开放HTTP端口与端侧设备连接。在MindSpore联邦学习框架中,
Server还支持弹性伸缩以及容灾,能够在训练任务不中断的情况下,动态调配硬件资源。
Scheduler和Server需部署在单网卡的服务器或者容器中,且处于相同网段。MindSpore自动获取首个可用IP地址作为Server地址。
服务器会校验客户端携带的时间戳,需要确保服务器定期同步时钟,避免服务器出现较大的时钟偏移。
准备环节
安装MindSpore
MindSpore联邦学习云侧集群支持在x86 CPU和GPU CUDA硬件平台上部署。可参考MindSpore安装指南安装MindSpore最新版本。
定义模型
为便于部署,MindSpore联邦学习的Scheduler和Server进程可以复用训练脚本,仅通过参数配置选择以不同的角色启动。
本教程选择LeNet网络作为示例,具体的网络结构、损失函数和优化器定义请参考LeNet网络样例脚本。
参数配置
MindSpore联邦学习任务进程复用了训练脚本,用户只需要使用相同的脚本,并通过Python接口set_fl_context传递不同的参数,启动不同角色的MindSpore进程。参数配置说明请参考API文档。
在确定参数配置后,用户需要在执行训练前调用set_fl_context接口,调用方式的示例如下:
import mindspore.context as context
...
enable_fl = True
server_mode = "FEDERATED_LEARNING"
ms_role = "MS_SERVER"
server_num = 4
scheduler_ip = "192.168.216.124"
scheduler_port = 6667
fl_server_port = 6668
fl_name = "LeNet"
scheduler_manage_port = 11202
config_file_path = "./config.json"
fl_ctx = {
"enable_fl": enable_fl,
"server_mode": server_mode,
"ms_role": ms_role,
"server_num": server_num,
"scheduler_ip": scheduler_ip,
"scheduler_port": scheduler_port,
"fl_server_port": fl_server_port,
"fl_name": fl_name,
"scheduler_manage_port": scheduler_manage_port,
"config_file_path": config_file_path
}
context.set_fl_context(**fl_ctx)
...
model.train()
本示例设置了训练任务的模式为联邦学习(即FEDERATED_LEARNING),训练进程角色为Server,需要启动4个Server进行集群组网,集群Scheduler的IP地址为192.168.216.124,集群Scheduler端口为6667,联邦学习HTTP服务端口为6668(由端侧设备连接),任务名为LeNet,集群Scheduler管理端口为11202。
示例中的参数,部分仅被
Scheduler使用,如scheduler_manage_port;部分仅被Server使用,如fl_server_port。为了方便部署,可将这些参数配置统一传入,MindSpore会根据进程角色,选择读取所需的参数配置。
建议将参数配置通过Python argparse模块传入,以下是部分关键参数传入脚本的示例:
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--server_mode", type=str, default="FEDERATED_LEARNING")
parser.add_argument("--ms_role", type=str, default="MS_SERVER")
parser.add_argument("--server_num", type=int, default=4)
parser.add_argument("--scheduler_ip", type=str, default="192.168.216.124")
parser.add_argument("--scheduler_port", type=int, default=6667)
parser.add_argument("--fl_server_port", type=int, default=6668)
parser.add_argument("--fl_name", type=str, default="LeNet")
parser.add_argument("--scheduler_manage_port", type=int, default=11202)
parser.add_argument("--config_file_path", type=str, default="")
args, t = parser.parse_known_args()
server_mode = args.server_mode
ms_role = args.ms_role
server_num = args.server_num
scheduler_ip = args.scheduler_ip
scheduler_port = args.scheduler_port
fl_server_port = args.fl_server_port
fl_name = args.fl_name
scheduler_manage_port = args.scheduler_manage_port
config_file_path = args.config_file_path
每个Python脚本对应一个进程,若要在不同主机部署多个
Server角色,则需要分别建立多个进程,可以通过shell指令配合Python的方式快速启动多Server。可参考**示例**。每个
Server进程需要有一个集群内唯一标志MS_NODE_ID,需要通过环境变量设置此字段。本部署教程中,此变量已在脚本run_mobile_server.py中设置。
启动集群
参考示例,启动集群。参考示例关键目录结构如下:
mobile/
├── config.json
├── finish_mobile.py
├── run_mobile_sched.py
├── run_mobile_server.py
├── src
│ └── model.py
└── test_mobile_lenet.py
config.json:配置文件,用于安全能力配置,容灾等。
finish_mobile.py:由于Server集群为常驻进程,使用本文件手动退出集群。
run_mobile_sched.py:启动Scheduler。
run_mobile_server.py:启动Server。
model.py:网络模型。
test_mobile_lenet.py:训练脚本
启动Scheduler
run_mobile_sched.py是用于启动Scheduler的Python脚本,并支持通过argparse传参修改配置。执行指令的示例如下,代表启动本次联邦学习任务的Scheduler,其TCP端口为6667,联邦学习HTTP服务起始端口为6668,Server数量为4个,集群Scheduler管理端口为11202:python run_mobile_sched.py --scheduler_ip=192.168.216.124 --scheduler_port=6667 --fl_server_port=6668 --server_num=4 --scheduler_manage_port=11202 --config_file_path=$PWD/config.json
启动Server
run_mobile_server.py是用于启动若干Server的Python脚本,并支持通过argparse传参修改配置。执行指令的示例如下,代表启动本次联邦学习任务的Server,其TCP端口为6667,联邦学习HTTP服务起始端口为6668,Server数量为4个,联邦学习任务正常进行需要的端侧设备数量为8个:python run_mobile_server.py --scheduler_ip=192.168.216.124 --scheduler_port=6667 --fl_server_port=6668 --server_num=4 --start_fl_job_threshold=8 --config_file_path=$PWD/config.json
以上指令将启动了4个
Server进程,各Server进程的联邦学习服务端口依次为6668、6669、6670和6671,具体实现详见脚本run_mobile_server.py。若只想在单机部署
Scheduler以及Server,只需将scheduler_ip配置项修改为127.0.0.1即可。若想让
Server分布式部署在不同物理节点,可以使用local_server_num参数,代表在本节点需要执行的Server进程数量:# 在节点1启动3个Server进程 python run_mobile_server.py --scheduler_ip={ip_address_node_1} --scheduler_port=6667 --fl_server_port=6668 --server_num=4 --start_fl_job_threshold=8 --local_server_num=3 --config_file_path=$PWD/config.json
# 在节点2启动1个Server进程 python run_mobile_server.py --scheduler_ip={ip_address_node_2} --scheduler_port=6667 --fl_server_port=6668 --server_num=4 --start_fl_job_threshold=8 --local_server_num=1 --config_file_path=$PWD/config.json
若
Server日志中包含以下内容:Server started successfully.
则表明启动成功。
以上分布式部署的指令中,
server_num均为4,这是因为该参数代表集群全局的Server数量,其不应随物理节点的数量而改变。对于不同节点上的Server而言,其无需感知各自的IP地址,集群的一致性保障和节点发现均由Scheduler完成。停止联邦学习 当前版本联邦学习集群为常驻进程,可执行
finish_mobile.py脚本,以终止联邦学习服务。执行指令的示例如下,其中scheduler_port传参,需与启动服务器时的传参保持一致,代表停止此Scheduler对应的集群。python finish_mobile.py --scheduler_port=6667
若console打印如下内容:
killed $PID1 killed $PID2 killed $PID3 killed $PID4 killed $PID5 killed $PID6 killed $PID7 killed $PID8
则表明停止服务成功。
弹性伸缩
MindSpore联邦学习框架支持Server的弹性伸缩,对外通过Scheduler管理端口提供RESTful服务,使得用户在不中断训练任务的情况下,对硬件资源进行动态调度。目前MindSpore的弹性伸缩仅支持水平伸缩(Scale Out/In),暂不支持垂直伸缩(Scale Up/Down)。在弹性伸缩场景下,Server进程数量将根据用户设置增加/减少。
以下示例介绍了如何通过RESTful原生接口,对控制集群扩容/缩容。
扩容
在集群启动后,进入部署scheduler节点的机器,向
Scheduler发起扩容请求,可使用curl指令构造RESTful扩容请求,代表集群需要扩容2个Server节点:curl -i -X POST \ -H "Content-Type:application/json" \ -d \ '{ "worker_num":0, "server_num":2 }' \ 'http://127.0.0.1:11202/scaleout'
需要拉起
2个新的Server进程,扩容Server的node_id不能与已有Server的node_id相同,并将server_num参数累加扩容的个数,从而保证全局组网信息的正确性,即扩容后,server_num的数量应为6,执行指令的示例如下:python run_mobile_server.py --node_id=scale_node --scheduler_ip=192.168.216.124 --scheduler_port=6667 --fl_server_port=6672 --server_num=6 --start_fl_job_threshold=8 --local_server_num=2 --config_file_path=$PWD/config.json
该指令代表启动两个
Server节点,其联邦学习服务端口分别为6672和6673,总Server数量为6。缩容
在集群启动后,进入部署scheduler节点的机器,向
Scheduler发起缩容请求。由于缩容需要对具体节点进行操作,因此需要先查询节点信息:curl -i -X GET \ 'http://127.0.0.1:11202/nodes'
Scheduler将返回json格式的查询结果:{ "code": 0, "message": "Get nodes info successful.", "nodeIds": [ { "alive": "true", "nodeId": "3", "rankId": "3", "role": "SERVER" }, { "alive": "true", "nodeId": "0", "rankId": "0", "role": "SERVER" }, { "alive": "true", "nodeId": "2", "rankId": "2", "role": "SERVER" }, { "alive": "true", "nodeId": "1", "rankId": "1", "role": "SERVER" }, { "alive": "true", "nodeId": "20", "rankId": "0", "role": "SCHEDULER" } ] }
选择
Rank3和Rank2进行缩容:curl -i -X POST \ -H "Content-Type:application/json" \ -d \ '{ "node_ids": ["2", "3"] }' \ 'http://127.0.0.1:11202/scalein'
在集群扩容/缩容成功后,训练任务会自动恢复,不需要用户进行额外干预。
可以通过集群管理工具(如Kubernetes)创建或者释放
Server资源。缩容后,被缩容节点进程不会退出,需要集群管理工具(如Kubernetes)释放
Server资源或者执行kill -15 $PID来控制进程退出。请注意需要向scheduler节点查询集群状态,等待集群的状态置为CLUSTER_READY,才可以回收被缩容的节点。
容灾
在MindSpore联邦学习集群中某节点下线后,可以保持集群在线而不退出训练任务,在该节点重新被启动后,可以恢复训练任务。目前MindSpore暂时支持Server节点的容灾(Server 0除外)。
想要支持容灾,config_file_path指定的config.json配置文件需要添加如下字段:
{
"recovery": {
"storage_type": 1,
"storge_file_path": "config.json"
}
}
recovery:有此字段则代表需要支持容灾。
storage_type:持久化存储类型,目前只支持值为
1,代表文件存储。storage_file_path:容灾恢复文件路径。
节点重新启动的指令类似扩容指令,在节点被手动下线之后,执行如下指令:
python run_mobile_server.py --scheduler_ip=192.168.216.124 --scheduler_port=6667 --fl_server_port=6673 --server_num=6 --start_fl_job_threshold=8 --local_server_num=1 --config_file_path=$PWD/config.json
此指令代表重新启动了Server,其联邦学习服务端口为6673。
在弹性伸缩命令下发成功后,在扩缩容业务执行完毕前,不支持容灾。
容灾后,重新启动节点的
MS_NODE_ID变量需要和异常退出的节点保持一致,以保证能够恢复组网。
安全
MindSpore联邦学习框架支持Server的SSL安全认证,要开启安全认证,需要在启动命令加上enable_ssl=True,config_file_path指定的config.json配置文件需要添加如下字段:
{
"server_cert_path": "server.p12",
"crl_path": "",
"client_cert_path": "client.p12",
"ca_cert_path": "ca.crt",
"cert_expire_warning_time_in_day": 90,
"cipher_list": "ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-DSS-AES128-GCM-SHA256:kEDH+AESGCM:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA:ECDHE-ECDSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-DSS-AES128-SHA256:DHE-RSA-AES256-SHA256:DHE-DSS-AES256-SHA:DHE-RSA-AES256-SHA:!aNULL:!eNULL:!EXPORT:!DES:!RC4:!3DES:!MD5:!PSK",
"connection_num":10000
}
server_cert_path:服务端包含证书和密钥的密文的p12文件路径。
crl_path:吊销列表的文件。
client_cert_path:客户端包含证书和密钥的密文的p12文件路径。
ca_cert_path:根证书。
cipher_list:密码套件。
cert_expire_warning_time_in_day:证书过期的告警时间。
p12文件中的密钥为密文存储,在启动时需要传入密码,具体参数请参考Python API mindspore.context.set_fl_context中的client_password以及server_password字段。