mindspore.dataset.Dataset.bucket_batch_by_length
- mindspore.dataset.Dataset.bucket_batch_by_length(column_names, bucket_boundaries, bucket_batch_sizes, element_length_function=None, pad_info=None, pad_to_bucket_boundary=False, drop_remainder=False)[源代码]
根据数据的长度进行分桶。每个桶将在数据填满的时候进行填充和批处理操作。
对数据集中的每一条数据进行长度计算。根据该条数据的长度计算结果和每个分桶的范围将该数据归类到特定的桶里面。 当某个分桶中数据条数达到指定的大小 bucket_batch_sizes 时,将根据 pad_info 的信息对分桶进行填充,再进行批处理。
执行流程参考下图:
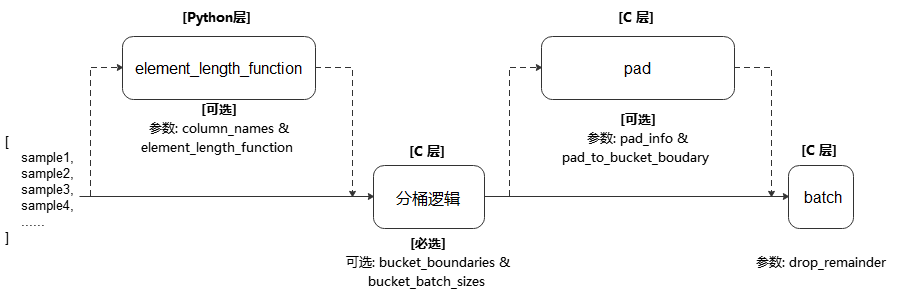
- 参数:
column_names (list[str]) - 传递给参数 element_length_function 的数据列,用于计算数据的长度。
bucket_boundaries (list[int]) - 指定各个分桶的上边界值,列表的数值必须严格递增。 如果有n个边界,则会创建n+1个桶,分配后桶的边界如下:[0, bucket_boundaries[0]),[bucket_boundaries[i], bucket_boundaries[i+1]),[bucket_boundaries[n-1], inf),其中,0<i<n-1。
bucket_batch_sizes (list[int]) - 指定每个分桶的批数据大小,必须包含 len(bucket_boundaries)+1 个元素。
element_length_function (Callable, 可选) - 长度计算函数。要求接收 len(column_names) 个输入参数,并返回一个整数代表该条数据的长度。 如果未指定该参数,则参数 column_names 的长度必须为1,此时该列数据的shape[0]值将被当做数据长度。默认值:
None,不指定。pad_info (dict, 可选) - 对指定数据列进行填充。通过传入dict来指定列信息与填充信息,要求dict的键是要填充的数据列名,dict的值是包含2个元素的元组。 元组中第1个元素表示要扩展至的目标shape,第2个元素表示要填充的值。 如果某一个数据列未指定将要填充后的shape和填充值,则该列中的每条数据都将填充至该批次中最长数据的长度,且填充值为0。 注意,pad_info 中任何填充shape为None的列,其每条数据长度都将被填充为当前批处理中最长数据的长度,除非指定 pad_to_bucket_boundary 为
True。默认值:None,不填充。pad_to_bucket_boundary (bool, 可选) - 如果为
True,则 pad_info 中填充shape为None的列,会被填充至由参数 bucket_batch_sizes 指定的对应分桶长度-1的长度。 如果有任何数据落入最后一个分桶中,则将报错。默认值:False。drop_remainder (bool, 可选) - 当每个分桶中的最后一个批处理数据数据条目小于 bucket_batch_sizes 时,是否丢弃该批处理数据。默认值:
False,不丢弃。
- 返回:
Dataset,按长度进行分桶和批处理操作后的数据集对象。
样例:
>>> # Create a dataset where certain counts rows are combined into a batch >>> # and drops the last incomplete batch if there is one. >>> import mindspore.dataset as ds >>> import numpy as np >>> def generate_2_columns(n): ... for i in range(n): ... yield (np.array([i]), np.array([j for j in range(i + 1)])) >>> >>> column_names = ["col1", "col2"] >>> dataset = ds.GeneratorDataset(generate_2_columns(8), column_names) >>> bucket_boundaries = [5, 10] >>> bucket_batch_sizes = [2, 1, 1] >>> element_length_function = (lambda col1, col2: max(len(col1), len(col2))) >>> # Will pad col2 to shape [bucket_boundaries[i]] where i is the >>> # index of the bucket that is currently being batched. >>> pad_info = {"col2": ([None], -1)} >>> pad_to_bucket_boundary = True >>> dataset = dataset.bucket_batch_by_length(column_names, bucket_boundaries, ... bucket_batch_sizes, ... element_length_function, pad_info, ... pad_to_bucket_boundary)