Distributed Graph Partition
![]()
Overview
In large model training tasks, users often use various types of parallel algorithms to distribute computational tasks to various nodes, to make full use of computational resources, e.g., through MindSpore operator-level parallelism, pipeline parallelism and other features. However, in some scenarios, the user needs to slice the graph into multiple subgraphs based on a custom algorithm and distribute them to different processes for distributed execution. MindSpore distributed graph partition feature provides an operator-granularity Python layer API to allow users to freely perform graph slicing and build distributed training/inference tasks based on custom algorithms.
Distributed graph slicing does not support PyNative mode.
Related interfaces:
mindspore.nn.Cell.place(role, rank_id): Set a label for all operators in this Cell. This label tells the MindSpore compiler on which process this Cell is started. Each label consists of the process roleroleandrank_id, so by setting different labels for different Cells, these Cells will be started on different processes, allowing the user to perform tasks such as distributed training/inference.mindspore.ops.Primitive.place(role, rank_id): Set labels for Primitive operator, with the same function asmindspore.nn.Cell.place(role, rank_id)interface.
Basic Principle
Distributed tasks need to be executed in a cluster. MindSpore reuses built-in Dynamic Networking module of MindSpore in order to have better scalability and reliability in distributed graph partition scenarios.
For distributed graph partition, each process represents a compute node (called Worker), and the scheduling node (called Scheduler) started by the dynamic networking module mentioned above allows discovering each compute node and thus forming a compute cluster.
After dynamic networking, MindSpore assigns role and rank, the role and id of each process, based on the user startup configuration, both of which form a unique tag for each process and are input to the Python layer API place. With the correspondence, the user can set process labels for any operator by calling the place interface, and the MindSpore graph compiler module processes it to slice the computed graph into multiple subgraphs for distribution to different processes for execution. For the detailed use, please refer to Primitive.place and Cell.place interface document.
As an example, the compute topology after distributed graph partition might be as follows:
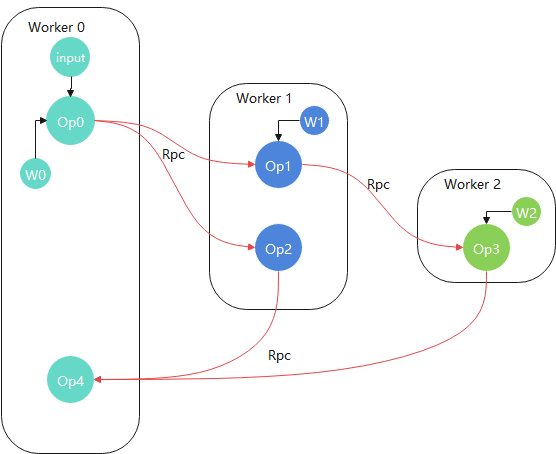
As shown in the figure above, each Worker has a portion of subgraphs that have been sliced by the user, with their own weights and inputs, and each Worker interacts with each other through the built-in Rpc communication operator for data interaction.
To ensure ease of use and user-friendliness, MindSpore also supports users to start dynamic networking and distributed training (without distinguishing between Worker and Scheduler) with a few modifications to a single script. See the following operation practice section for more details.
Operation Practice
Taking LeNet training on GPU based on MNIST dataset as an example, different parts of the graph in the training task are split to different computational nodes for execution.
You can download complete code here:
https://gitee.com/mindspore/docs/tree/r2.4.1/docs/sample_code/distributed_graph_partition.
The directory structure is as follows:
└─ sample_code
├─ distributed_graph_partition
├── lenet.py
├── run.sh
└── train.py
This tutorial does not involve starting across physical nodes, where all processes are on the same node. For MindSpore, there is no difference in the implementation of intra-node and cross-node distributed graph partition: after dynamic networking, graph slicing, and graph compilation processes, data interaction is performed via Rpc communication operators.
Loading the Dataset
import mindspore.dataset as ds
import mindspore.dataset.transforms as C
import mindspore.dataset.vision as CV
from mindspore import dtype as mstype
from mindspore.dataset.vision import Inter
def create_dataset(data_path, batch_size=32, repeat_size=1
num_parallel_workers=1):
"""
create dataset for train or test
"""
# define dataset
mnist_ds = ds.MnistDataset(data_path)
resize_height, resize_width = 32, 32
rescale = 1.0 / 255.0
shift = 0.0
rescale_nml = 1 / 0.3081
shift_nml = -1 * 0.1307 / 0.3081
# define map operations
resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR) # Bilinear mode
rescale_nml_op = CV.Rescale(rescale_nml, shift_nml)
rescale_op = CV.Rescale(rescale, shift)
hwc2chw_op = CV.HWC2CHW()
type_cast_op = C.TypeCast(mstype.int32)
# apply map operations on images
mnist_ds = mnist_ds.map(operations=type_cast_op, input_columns="label", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=resize_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=rescale_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=rescale_nml_op, input_columns="image", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=hwc2chw_op, input_columns="image", num_parallel_workers=num_parallel_workers)
# apply DatasetOps
buffer_size = 10000
mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size)
mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True)
mnist_ds = mnist_ds.repeat(repeat_size)
return mnist_ds
The above code creates the MNIST dataset.
Constructing the LeNet Network
In order to make slicing to a single-machine single-card task, we need to first construct a single-machine single-card copy:
import mindspore.nn as nn
from mindspore.common.initializer import TruncatedNormal
def conv(in_channels, out_channels, kernel_size, stride=1, padding=0):
"""weight initial for conv layer"""
weight = weight_variable()
return nn.Conv2d(in_channels, out_channels,
kernel_size=kernel_size, stride=stride, padding=padding,
weight_init=weight, has_bias=False, pad_mode="valid")
def fc_with_initialize(input_channels, out_channels):
"""weight initial for fc layer"""
weight = weight_variable()
bias = weight_variable()
return nn.Dense(input_channels, out_channels, weight, bias)
def weight_variable():
"""weight initial"""
return TruncatedNormal(0.02)
class LeNet(nn.Cell):
def __init__(self, num_class=10, channel=1):
super(LeNet, self).__init__()
self.num_class = num_class
self.conv1 = conv(channel, 6, 5)
self.conv2 = conv(6, 16, 5)
self.fc1 = fc_with_initialize(16 * 5 * 5, 120)
self.fc2 = fc_with_initialize(120, 84)
self.fc3 = fc_with_initialize(84, self.num_class)
self.relu = nn.ReLU()
self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2)
self.flatten = nn.Flatten()
def construct(self, x):
x = self.conv1(x)
x = self.relu(x)
x = self.max_pool2d(x)
x = self.conv2(x)
x = self.relu(x)
x = self.max_pool2d(x)
x = self.flatten(x)
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
x = self.relu(x)
x = self.fc3(x)
return x
Calling the Interface for Distributed Graph Partition
For this training task we slice fc1 to process Worker 0, fc2 to process Worker 1, fc3 to process Worker 2, conv1 to process Worker 3, and conv2 to process Worker 4.
Distributed graph sharding can be completed by adding the following graph partition statement after initializing the network.
net = LeNet()
net.fc1.place("MS_WORKER", 0)
net.fc2.place("MS_WORKER", 1)
net.fc3.place("MS_WORKER", 2)
net.conv1.place("MS_WORKER", 3)
net.conv2.place("MS_WORKER", 4)
The first parameter of the place interface, role, is the process role, and the second parameter is the process rank, which means that the operator is executed on a process of such role. Currently the place interface only supports the MS_WORKER role, which represents the Worker X process described above.
It follows that a user can quickly implement a distributed training task by simply describing a custom algorithm through a single-machine copy and then setting the label of the compute node where the operator is located through the place interface. The advantages of this approach are:
1.Instead of writing separate execution scripts for each compute node, users can execute distributed tasks with just one script, MindSpore.
2.Provides a more general and user-friendly interface. Through the place interface, users can intuitively describe their distributed training algorithms
Defining the Optimizer and Loss Function
import mindspore.nn as nn
def get_optimizer(net, lr=0.01):
momentum = 0.9
mom_optimizer = nn.Momentum(filter(lambda x: x.requires_grad, net.get_parameters()), lr, momentum)
return mom_optimizer
def get_loss():
return nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
Executing the Training Code
The entry script train.py of training code:
import mindspore as ms
from mindspore import set_seed
from mindspore.train import Accuracy, Model, LossMonitor, TimeMonitor
from mindspore.communication import init, get_rank
ms.set_context(mode=ms.GRAPH_MODE)
init()
net = LeNet()
net.fc1.place("MS_WORKER", 0)
net.fc2.place("MS_WORKER", 1)
net.fc3.place("MS_WORKER", 2)
net.conv1.place("MS_WORKER", 3)
net.conv2.place("MS_WORKER", 4)
opt = get_optimizer(net)
criterion = get_loss()
model = Model(net, criterion, opt, metrics={"Accuracy": Accuracy()})
print("================= Start training =================", flush=True)
ds_train = create_dataset(os.path.join(os.getenv("DATA_PATH"), 'train'))
model.train(10, ds_train, callbacks=[LossMonitor(), TimeMonitor()],dataset_sink_mode=False)
print("================= Start testing =================", flush=True)
ds_eval = create_dataset(os.path.join(os.getenv("DATA_PATH"), 'test'))
acc = model.eval(ds_eval, dataset_sink_mode=False)
if get_rank() == 0:
print("Accuracy is:", acc)
The above code trains first and then infers, where all processes are executed in a distributed manner.
In a distributed graph partition scenario, the user must call
mindspore.communication.init, an interface that is the entry point for MindSporedynamic networkingmodule, which is used to help form compute clusters, and initialize communication operators. If not called, MindSpore performs single-machine single-card training, i.e. theplaceinterface will not take effect.Since only some subgraphs are executed on some processes, their inference precision or loss is not meaningful. The user only needs to focus on the precision on
Worker 0.
Preparation for Training Shell Script
Starting Scheduler and Worker Processes
Since multiple processes are started within a node, only one Scheduler process and multiple Worker processes need to be started via a Shell script. For the meaning of the environment variables in the script and their usage, refer to the dynamic cluster environment variables.
The run.sh execution script is as follows:
execute_path=$(pwd)
if [ ! -d "${execute_path}/MNIST_Data" ]; then
if [ ! -f "${execute_path}/MNIST_Data.zip" ]; then
wget http://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/MNIST_Data.zip
fi
unzip MNIST_Data.zip
fi
self_path=$(dirname $0)
# Set public environment.
export MS_WORKER_NUM=8
export MS_SCHED_HOST=127.0.0.1
export MS_SCHED_PORT=8118
export DATA_PATH=${execute_path}/MNIST_Data/
# Launch scheduler.
export MS_ROLE=MS_SCHED
rm -rf ${execute_path}/sched/
mkdir ${execute_path}/sched/
cd ${execute_path}/sched/ || exit
python ${self_path}/../train.py > sched.log 2>&1 &
# Launch workers.
export MS_ROLE=MS_WORKER
for((i=0;i<$MS_WORKER_NUM;i++));
do
rm -rf ${execute_path}/worker_$i/
mkdir ${execute_path}/worker_$i/
cd ${execute_path}/worker_$i/ || exit
python ${self_path}/../train.py > worker_$i.log 2>&1 &
done
echo "Start training. The output is saved in sched and worker_* folder."
In the above script, export MS_WORKER_NUM=8 means that 8 MS_WORKER processes need to be started for this distributed execution. export MS_SCHED_HOST=127.0.0.1 means the address of Scheduler is 127.0.0.1. export MS_SCHED_PORT=8118 means the open port of Scheduler is 8118, and all processes will connect to this port for dynamic networking.
The above environment variables are exported for both Worker and Scheduler processes, and then the corresponding roles are exported separately to start the processes for the corresponding roles: after export MS_ROLE=MS_SCHED, start the Scheduler process, and after export MS_ROLE=MS_WORKER, start the MS_WORKER_NUM worker process cyclically.
Note that each process is executed in the background, so there will be a wait for the process to exit statement at the end of the script.
Executing instruction
bash run.sh
Viewing the Execution Result
View accuracy execution instruction:
grep -rn "Accuracy" */*.log
Result:
Accuracy is: {'Accuracy': 0.9888822115384616}
It shows that distributed graph Partition has no effect on LeNet training and inference results.
Summary
MindSpore distributed graph partition feature provides users with place interface for operator granularity, which supports users to slice the compute graph according to custom algorithms and perform distributed training in various scenarios through dynamic networking.
The user only needs to make the following modifies to the single-machine single-card copy to initiate the task:
Call the
mindspore.communication.initinterface at the top of the single-machine single-card copy to start dynamic networking.Call the
placeinterface ofops.Primitiveornn.Cellfor the operator or layer in the graph, based on the user algorithm, to set the label of the process where the operator is located.Start
WorkerandSchedulerprocesses via shell scripts to execute distributed tasks.
At present, the place interface is in a limited state of support, and advanced usage is in the development stage. Users are welcome to make various comments or issues on the MindSpore website.
The place interface currently has the following limitations:
The input parameter
roleis only supported to be set toMS_WORKER. This is because each node in the distributed graph partition scenario is a compute nodeWorker, and setting other roles is not required for now.Unable to mix with Parameter Server, Data Parallelism, and Auto Parallelism. The compute graph of each process after distributed graph partition is not consistent, and all three features have copies of inter-process graphs or operators that may cause unknown errors when executed overlaid with this feature. Mixed-use features will be supported in subsequent releases.
Control flow + distributed graph partition is in a limited support state and errors may be reported. This scenario will also be supported in subsequent releases.