Network Constructing Comparison
This chapter will introduce the related contents of MindSpore scripting, including datasets, network models and loss functions, optimizers, training processes, inference processes from the basic modules needed for training and inference. It will include some functional techniques commonly used in network migration, such as network writing specifications, training and inference process templates, and dynamic shape mitigation strategies.
Network Training Principle
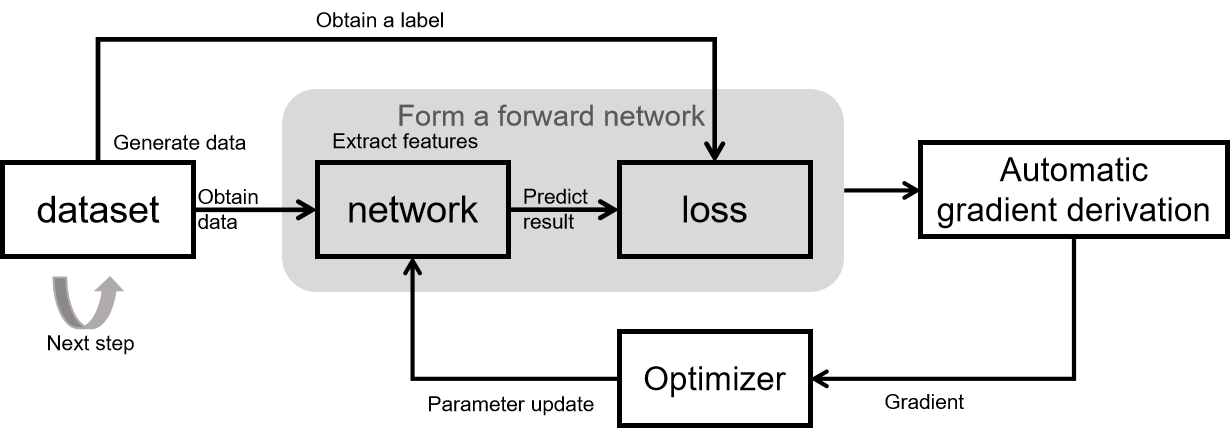
The basic principle of network training is shown in the figure above.
The training process of the whole network consists of 5 modules:
dataset: for obtaining data, containing input of network and labels. MindSpore provides a basic common dataset processing interface, and also supports constructing datasets by using python iterators.
network: network model implementation, typically encapsulated by using Cell. Declare the required modules and operators in init, and implement graph construction in construct.
loss: loss function. Used to measure the degree of difference between the predicted value and the true value. In deep learning, model training is the process of shrinking the loss function value by iterating continuously. Defining a good loss function can help the loss function value converge faster to achieve better precision. MindSpore provides many common loss functions, but of course you can define and implement your own loss function.
Automatic gradient derivation: Generally, network and loss are encapsulated together as a forward network and the forward network is given to the automatic gradient derivation module for gradient calculation. MindSpore provides an automatic gradient derivation interface, which shields the user from a large number of derivation details and procedures and greatly reduces the threshold of framework. When you need to customize the gradient, MindSpore also provides interface to freely implement the gradient calculation.
Optimizer: used to calculate and update network parameters during model training. MindSpore provides a number of general-purpose optimizers for users to choose, and also supports users to customize the optimizers.
Principles of Network Inference

The basic principles of network inference are shown in the figure above.
The inference process of the whole network consists of 3 modules:
dataset: used to obtain data, including the input of the network and labels. Since entire inference dataset needs to be inferred during inference process, batchsize is recommended to set to 1. If batchsize is not 1, note that when adding batch, add drop_remainder=False. In addition the inference process is a fixed process. Loading the same parameters every time has the same inference results, and the inference process should not have random data augmentation.
network: network model implementation, generally encapsulated by using Cell. The network structure during inference is generally the same as the network structure during training. It should be noted that Cell is tagged with set_train(False) for inference and set_train(True) for training, just like PyTorch model.eval() (model evaluation mode) and model.train() (model training mode).
metrics: When the training task is over, evaluation metrics (Metrics) and evaluation functions are used to assess whether the model works well. Commonly used evaluation metrics include Confusion Matrix, Accuracy, Precision, and Recall. The mindspore.nn module provides the common evaluation functions, and users can also define their own evaluation metrics as needed. Customized Metrics functions need to inherit train.Metric parent class and reimplement the clear method, update method and eval method of the parent class.
Constructing Network
After understanding the process of network training and inference, the following describes the process of implementing network training and inference on MindSpore.
Note
When doing network migration, we recommend doing inference validation of the model as a priority after completing the network scripting. This has several benefits:
Compared with training, the inference process is fixed and able to be compared with the reference implementation.
Compared with training, the time required for inference is relatively short, enabling rapid verification of the correctness of the network structure and inference process.
The trained results need to be validated through the inference process to verify results of the model. It is necessary that the correctness of the inference be ensured first, then to prove that the training is valid.
Before constructing a network, please first understand the differences between MindSpore and PyTorch in data objects, network architecture interfaces, and specified backend device codes:
Tensor/Parameter
In PyTorch, there are four types of objects that can store data: Tensor, Variable, Parameter, and Buffer. The default behaviors of the four types of objects are different. When the gradient is not required, the Tensor and Buffer data objects are used. When the gradient is required, the Variable and Parameter data objects are used. When PyTorch designs the four types of data objects, the functions are redundant. (In addition, Variable will be discarded.)
MindSpore optimizes the data object design logic and retains only two types of data objects: Tensor and Parameter. The Tensor object only participates in calculation and does not need to perform gradient derivation or parameter update on it. The Parameter data object has the same meaning as the Parameter data object of PyTorch. The requires_grad attribute determines whether to perform gradient derivation or parameter update on the Parameter data object. During network migration, all data objects that are not updated in PyTorch can be declared as Tensor in MindSpore.
nn.Module/nn.Cell
When PyTorch is used to build a network structure, the nn.Module class is used. Generally, network elements are defined and initialized in the __init__ function, and the graph structure expression of the network is defined in the forward function. Objects of these classes are invoked to build and train the entire model. nn.Module not only provides us with graph building interfaces, but also provides us with some common Module APIs to help us execute more complex logic.
The nn.Cell class in MindSpore plays the same role as the nn.Module class in PyTorch. Both classes are used to build graph structures. MindSpore also provides various Cell APIs for developers. Although the names are not the same, the mapping of common functions in nn.Module can be found in nn.Cell. nn.Cell is the inference mode by default. For a class that inherits nn.Cell, if the training and inference have different structures, the subclass performs the inference branch by default. The nn.Module of PyTorch is training mode by default.
The following uses several common methods as examples:
Common Method
nn.Module
nn.Cell
Obtain child elements
named_children
cells_and_names
Add subelements
add_module
insert_child_to_cell
Obtain parameters of an element
parameters
get_parameters
backend device
When building a model, PyTorch usually uses torch.device to specify the device to which the model and data are bound, that is, whether the device is on the CPU or GPU. If multiple GPUs are supported, you can also specify the GPU sequence number. After binding a device, you need to deploy the model and data to the device.
In MindSpore, the device_target parameter in context specifies the device bound to the model, and the device_id parameter specifies the device sequence number. Different from PyTorch, once the device is successfully set, the input data and model are copied to the specified device for execution by default. You do not need to and cannot change the type of the device where the data and model run. In addition, the Tensor returned after the network runs is copied to the CPU device by default. You can directly access and modify the Tensor, including converting the Tensor to the numpy format. Unlike PyTorch, you do not need to run the tensor.cpu command and then convert the Tensor to the NumPy format.
The sample codes are as follows:
PyTorch
MindSpore
import os import torch from torch import nn # bind to the GPU 0 if GPU is available, otherwise bind to CPU device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # Single GPU or CPU # deploy model to specified hardware model.to(device) # deploy data to specified hardware data.to(device) # distribute training on multiple GPUs if torch.cuda.device_count() > 1: model = nn.DataParallel(model, device_ids=[0,1,2]) model.to(device) # set available device os.environ['CUDA_VISIBLE_DEVICE']='1' model.cuda()
import mindspore as ms ms.set_device("Ascend", 0) # define net Model = .. # define dataset dataset = .. # training, automatically deploy to Ascend according to device_target Model.train(1, dataset)