深度卷积对抗生成网络
![]()
![]()
![]()
概述
GAN(生成对抗网络)
生成对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。最初,GAN由Ian Goodfellow 于2014年发明,并在论文Generative Adversarial Nets中首次进行了描述。GAN由两个不同的模型组成:生成器和判别器。生成器的任务是生成看起来像训练图像的“假”图像。判别器需要判断从生成器输出的图像是真实的训练图像还是生成的假图像。在训练过程中,生成器会不断尝试通过生成更好的假图像来骗过判别器,而判别器在这过程中也会逐步提升判别能力。这种博弈的平衡点是,当生成器生成的假图像看起来像训练数据时,判别器拥有50%的真假判断置信度。
本篇基于MindSpore v1.3.0,CPU/GPU/Ascend环境运行。
在教程开始前,首先定义一些在整个过程中需要用到的符号:
\(x\):代表图像的数据;
\(D(x)\):判别器网络,给出图像判定为真实图像的概率,其中\(x\)来自于训练数据而非生成器; 由于我们在判别过程中需要处理图像,因此要为\(D(x)\)提供CHW格式且大小为
3x64x64的图像。当\(x\)来自训练数据时,\(D(x)\)数值应该为高,而当\(x\)来自生成器时,\(D(x)\)数值应该为低。 因此\(D(x)\)也可以被认为是传统的二分类器;
接下来我们来定义生成器的表示方法:
\(z\):标准正态分布中提取出的隐向量;
\(G(z)\):表示将隐向量\(z\)映射到数据空间的生成器函数;
函数\(G(z)\)的目标是将一个随机高斯噪声\(z\)通过一个生成网络生成一个和真实数据分布\(pdata(x)\)差不多的数据分布,其中\(θ\)是网络参数,我们希望找到\(θ\)使得\(pG(x;θ)\)和\(pdata(x)\)尽可能的接近。
\(D(G(z))\)是生成器\(G\)生成的假图像被判定为真实图像的概率;
如Goodfellow 的论文中所述,D和G在进行一场博弈,D想要最大程度的正确分类真图像与假图像,也就是参数\(log D(x)\);而G试图欺骗D来最小化假图像被识别到的概率,也就是参数\(log(1−D(G(z)))\)。GAN的损失函数为
从理论上讲,此博弈游戏的平衡点是\(pG(x;θ) = pdata(x)\),此时判别器会随机猜测输入是真图像还是假图像。然而,GAN的收敛可行性仍在研究当中,在实际场景中模型并不会被训练到这一步。
DCGAN(深度卷积对抗生成网络)
DCGAN是上述GAN的直接扩展。不同之处在于,DCGAN会分别在判别器和生成器中使用卷积和卷积转置层。它最早由Radford等人在论文Unsupervised Representation Learning With Deep Convolutional Generative Adversarial Networks中进行描述。判别器由分层的卷积层、BatchNorm层和LeakyReLU激活层组成。输入是3x64x64的图像,输出是该图像为真图像的概率。生成器则是由转置卷积层、BatchNorm层和ReLU激活层组成。输入是标准正态分布中提取出的隐向量\(z\),输出是3x64x64的RGB图像。在下面的教程中,提供了有关如何设置优化器、如何计算损失函数以及如何初始化模型权重的说明。
本教程将使用真实名人的照片来训练一个生成对抗网络(GAN),接着产生虚假名人图片。
为了节省运行时间,建议用户使用GPU/Ascend来运行本实验。
准备环节
导入模块
[1]:
import numpy as np
import matplotlib.pyplot as plt
import mindspore.dataset as ds
import mindspore.dataset.vision.c_transforms as vision
from mindspore.common.initializer import Initializer
from mindspore import nn, ops, Tensor, context
from mindspore import dtype as mstype
配置环境
本教程我们在Ascend环境下,使用图模式运行实验。
[2]:
context.set_context(mode=context.GRAPH_MODE, device_target="Ascend")
准备数据
在本教程中,我们将使用Celeb-A Faces
数据集,该数据集为人脸属性数据集,其包含10,177个名人身份的202,599张人脸图片。官网提供了多个下载链接,我们选择Align&Cropped Images下的img_align_celeba.zip,是202,599张经过人脸对齐和裁剪了的图像。因数据集较大,本教程为了节省下载和训练时间,所以采用了部分的数据集。为了完整流畅地运行程序,需要在当前路径下创建一个data目录,并在data目录下创建一个名为celeba的目录,并将压缩文件解压缩到该目录中。最后,将此教程的dataroot输入设置为刚创建的celeba目录。
在Jupyter Notebook中执行如下命令下载数据集。
[3]:
!mkdir -p ./data/celeba
!wget -NP ./data/celeba https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/intermediate/img_align_celeba.rar
!unrar x ./data/celeba/img_align_celeba.rar
目录结构如下:
./data/celeba
-> img_align_celeba
-> 188242.jpg
-> 173822.jpg
-> 284702.jpg
-> 537394.jpg
...
数据处理
首先为执行过程定义一些输入:
dataroot:数据集文件夹根目录;workers:加载数据的线程数;batch_size:训练中使用的批量大小,DCGAN论文使用的批量大小为128;image_size:训练图像的大小,此实现默认为64x64,如果需要其他尺寸,则必须同时更改D和G的结构;nc:输入图像中的彩色通道数,因为此次是彩色图像所以设为3;nz:隐向量的长度;ngf:设置通过生成器的特征图的深度;ndf:设置通过判别器传播的特征图的深度;num_epochs:要运行的训练周期数,训练更长的时间可能会导致更好的结果,但也会花费更长的时间;lr:训练的学习率,如DCGAN论文中所述,此数字应为0.0001;beta1:Adam优化器的beta1超参数。如DCGAN论文所述,该数字应为0.5;
[4]:
# 数据集根目录
dataroot = "./data/celeba"
# 载入数据线程数
workers = 4
# 批量大小
batch_size = 128
# 训练图像空间大小,所有图像都将调整为该大小
image_size = 64
# 图像彩色通道数,对于彩色图像为3
nc = 3
# 隐向量的长度
nz = 100
# 特征图在生成器中的大小
ngf = 64
# 特征图在判别器中的大小
ndf = 64
# 训练周期数
num_epochs = 10
# 学习率
lr = 0.0001
# Beta1 超参数
beta1 = 0.5
定义
create_dataset_imagenet函数对数据进行处理和增强操作。
[5]:
def create_dataset_imagenet(dataset_path, num_parallel_workers=None):
# 数据加载
data_set = ds.ImageFolderDataset(dataset_path, num_parallel_workers=num_parallel_workers, shuffle=True)
# 数据增强操作
transform_img = [
vision.Decode(),
vision.Resize(image_size),
vision.CenterCrop(image_size),
vision.HWC2CHW()
]
# 数据映射操作
data_set = data_set.map(input_columns="image", num_parallel_workers=num_parallel_workers, operations=transform_img,
output_columns="image")
data_set = data_set.map(input_columns="image", num_parallel_workers=num_parallel_workers,
operations=lambda x: ((x - 255) / 255).astype("float32"))
data_set = data_set.map(
input_columns="image",
operations=lambda x: (
x,
np.random.normal(size=(nz, 1, 1)).astype("float32")
),
output_columns=["image", "latent_code"],
column_order=["image", "latent_code"],
num_parallel_workers=num_parallel_workers
)
# 批量操作
data_set = data_set.batch(batch_size)
return data_set
# 获取处理后的数据集
data = create_dataset_imagenet(dataroot, num_parallel_workers=workers)
# 获取数据集大小
size = data.get_dataset_size()
通过
create_dict_iterator函数将数据转换成字典迭代器,然后使用matplotlib模块可视化部分训练数据。
[6]:
data_iter = next(data.create_dict_iterator(output_numpy=True, num_epochs=num_epochs))
images = data_iter['image']
count = 1
# 可视化36张图片
for i in images[:36]:
plt.subplot(6, 6, count)
plt.imshow(i.transpose(1, 2, 0))
plt.axis("off")
plt.xticks([])
count += 1
plt.show()

创建网络
当处理完数据后,就可以来进行网络的搭建了。网络搭建将以权重初始化策略为起点,逐一详细讨论生成器、判别器和损失函数。
权重初始化
教程遵循DCGAN论文中的内容,所有模型权重均应从mean为0,sigma为0.02的正态分布中随机初始化。
[7]:
def _assignment(arr, num):
if arr.shape == ():
arr = arr.reshape((1))
arr[:] = num
arr = arr.reshape(())
else:
if isinstance(num, np.ndarray):
arr[:] = num[:]
else:
arr[:] = num
return arr
class Normal(Initializer):
"""将模型权重从均值为0,标准差为0.02的正态分布中随机初始化"""
def __init__(self, mean=0.0, sigma=0.02):
super(Normal, self).__init__()
self.sigma = sigma
self.mean = mean
def _initialize(self, arr):
np.random.seed(999)
arr_normal = np.random.normal(self.mean, self.sigma, arr.shape)
_assignment(arr, arr_normal)
生成器
生成器G的功能是将隐向量z映射到数据空间。由于数据是图像,这一过程也会创建与真实图像大小相同的 RGB 图像。在实践场景中,该功能是通过一系列Conv2dTranspose转置卷积层来完成的,每个层都与BatchNorm2d层和ReLu激活层配对,输出数据会经过tanh函数,使其返回[-1,1]的数据范围内。
DCGAN论文生成图像如下所示。
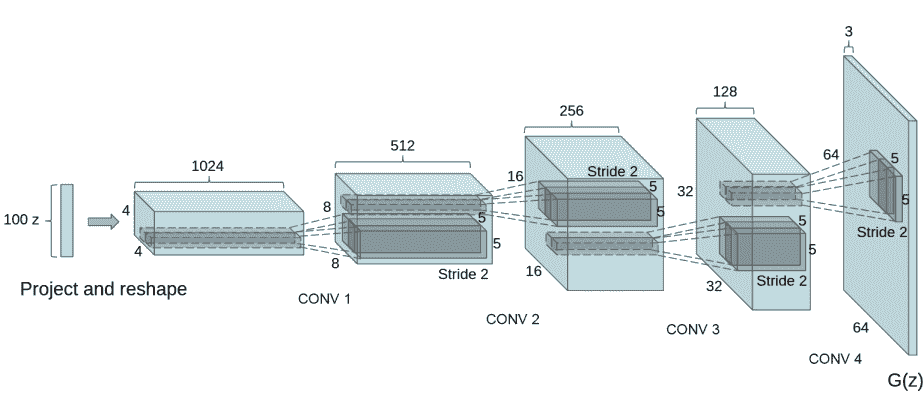
我们通过输入部分中设置的nz、ngf和nc来影响代码中的生成器结构。nz是隐向量z的长度,ngf与通过生成器传播的特征图的大小有关,nc是输出图像中的通道数。
以下是生成器的代码实现:
[8]:
def convt(in_channels, out_channels, kernel_size, stride=1, padding=0, pad_mode="pad"):
"""定义转置卷积层"""
weight_init = Normal(mean=0, sigma=0.02)
return nn.Conv2dTranspose(in_channels, out_channels,
kernel_size=kernel_size, stride=stride, padding=padding,
weight_init=weight_init, has_bias=False, pad_mode=pad_mode)
def bn(num_features):
"""定义BatchNorm2d层"""
gamma_init = Normal(mean=1, sigma=0.02)
return nn.BatchNorm2d(num_features=num_features, gamma_init=gamma_init)
class Generator(nn.Cell):
"""DCGAN网络生成器"""
def __init__(self):
super(Generator, self).__init__()
self.generator = nn.SequentialCell()
self.generator.append(convt(nz, ngf * 8, 4, 1, 0))
self.generator.append(bn(ngf * 8))
self.generator.append(nn.ReLU())
self.generator.append(convt(ngf * 8, ngf * 4, 4, 2, 1))
self.generator.append(bn(ngf * 4))
self.generator.append(nn.ReLU())
self.generator.append(convt(ngf * 4, ngf * 2, 4, 2, 1))
self.generator.append(bn(ngf * 2))
self.generator.append(nn.ReLU())
self.generator.append(convt(ngf * 2, ngf, 4, 2, 1))
self.generator.append(bn(ngf))
self.generator.append(nn.ReLU())
self.generator.append(convt(ngf, nc, 4, 2, 1))
self.generator.append(nn.Tanh())
def construct(self, x):
return self.generator(x)
实例化生成器,并打印出生成器的结构。
[9]:
netG = Generator()
print(netG)
Generator<
(generator): SequentialCell<
(0): Conv2dTranspose<input_channels=100, output_channels=512, kernel_size=(4, 4),stride=(1, 1), pad_mode=pad, padding=0, dilation=(1, 1), group=1, has_bias=False,weight_init=<__main__.Normal object at 0x7fdaf3c14b50>, bias_init=zeros>
(1): BatchNorm2d<num_features=512, eps=1e-05, momentum=0.09999999999999998, gamma=Parameter (name=1.gamma, shape=(512,), dtype=Float32, requires_grad=True), beta=Parameter (name=1.beta, shape=(512,), dtype=Float32, requires_grad=True), moving_mean=Parameter (name=1.moving_mean, shape=(512,), dtype=Float32, requires_grad=False), moving_variance=Parameter (name=1.moving_variance, shape=(512,), dtype=Float32, requires_grad=False)>
(2): ReLU<>
(3): Conv2dTranspose<input_channels=512, output_channels=256, kernel_size=(4, 4),stride=(2, 2), pad_mode=pad, padding=1, dilation=(1, 1), group=1, has_bias=False,weight_init=<__main__.Normal object at 0x7fdaf3bf8d90>, bias_init=zeros>
(4): BatchNorm2d<num_features=256, eps=1e-05, momentum=0.09999999999999998, gamma=Parameter (name=4.gamma, shape=(256,), dtype=Float32, requires_grad=True), beta=Parameter (name=4.beta, shape=(256,), dtype=Float32, requires_grad=True), moving_mean=Parameter (name=4.moving_mean, shape=(256,), dtype=Float32, requires_grad=False), moving_variance=Parameter (name=4.moving_variance, shape=(256,), dtype=Float32, requires_grad=False)>
(5): ReLU<>
(6): Conv2dTranspose<input_channels=256, output_channels=128, kernel_size=(4, 4),stride=(2, 2), pad_mode=pad, padding=1, dilation=(1, 1), group=1, has_bias=False,weight_init=<__main__.Normal object at 0x7fdaf18340d0>, bias_init=zeros>
(7): BatchNorm2d<num_features=128, eps=1e-05, momentum=0.09999999999999998, gamma=Parameter (name=7.gamma, shape=(128,), dtype=Float32, requires_grad=True), beta=Parameter (name=7.beta, shape=(128,), dtype=Float32, requires_grad=True), moving_mean=Parameter (name=7.moving_mean, shape=(128,), dtype=Float32, requires_grad=False), moving_variance=Parameter (name=7.moving_variance, shape=(128,), dtype=Float32, requires_grad=False)>
(8): ReLU<>
(9): Conv2dTranspose<input_channels=128, output_channels=64, kernel_size=(4, 4),stride=(2, 2), pad_mode=pad, padding=1, dilation=(1, 1), group=1, has_bias=False,weight_init=<__main__.Normal object at 0x7fdaf1844450>, bias_init=zeros>
(10): BatchNorm2d<num_features=64, eps=1e-05, momentum=0.09999999999999998, gamma=Parameter (name=10.gamma, shape=(64,), dtype=Float32, requires_grad=True), beta=Parameter (name=10.beta, shape=(64,), dtype=Float32, requires_grad=True), moving_mean=Parameter (name=10.moving_mean, shape=(64,), dtype=Float32, requires_grad=False), moving_variance=Parameter (name=10.moving_variance, shape=(64,), dtype=Float32, requires_grad=False)>
(11): ReLU<>
(12): Conv2dTranspose<input_channels=64, output_channels=3, kernel_size=(4, 4),stride=(2, 2), pad_mode=pad, padding=1, dilation=(1, 1), group=1, has_bias=False,weight_init=<__main__.Normal object at 0x7fdaf1844810>, bias_init=zeros>
(13): Tanh<>
>
>
判别器
如前所述,判别器D是一个二分类网络模型,输出判定该图像为真实图的概率。通过一系列的Conv2d、BatchNorm2d和LeakyReLU层对其进行处理,最后通过Sigmoid激活函数得到最终概率。
DCGAN论文提到,使用卷积而不是通过池化来进行下采样是一个好习惯,因为它可以让网络学习自己的池化特征。
判别器的代码实现如下:
[10]:
def conv(in_channels, out_channels, kernel_size, stride=1, padding=0, pad_mode="pad"):
'''定义卷积层'''
weight_init = Normal(mean=0, sigma=0.02)
return nn.Conv2d(in_channels, out_channels,
kernel_size=kernel_size, stride=stride, padding=padding,
weight_init=weight_init, has_bias=False, pad_mode=pad_mode)
class Discriminator(nn.Cell):
"""
DCGAN网络判别器
"""
def __init__(self):
super(Discriminator, self).__init__()
self.discriminator = nn.SequentialCell()
self.discriminator.append(conv(nc, ndf, 4, 2, 1))
self.discriminator.append(nn.LeakyReLU(0.2))
self.discriminator.append(conv(ndf, ndf * 2, 4, 2, 1))
self.discriminator.append(bn(ndf * 2))
self.discriminator.append(nn.LeakyReLU(0.2))
self.discriminator.append(conv(ndf * 2, ndf * 4, 4, 2, 1))
self.discriminator.append(bn(ndf * 4))
self.discriminator.append(nn.LeakyReLU(0.2))
self.discriminator.append(conv(ndf * 4, ndf * 8, 4, 2, 1))
self.discriminator.append(bn(ndf * 8))
self.discriminator.append(nn.LeakyReLU(0.2))
self.discriminator.append(conv(ndf * 8, 1, 4, 1))
self.discriminator.append(nn.Sigmoid())
def construct(self, x):
return self.discriminator(x)
实例化判别器,并打印出判别器的结构。
[11]:
netD = Discriminator()
print(netD)
Discriminator<
(discriminator): SequentialCell<
(0): Conv2d<input_channels=3, output_channels=64, kernel_size=(4, 4),stride=(2, 2), pad_mode=pad, padding=1, dilation=(1, 1), group=1, has_bias=Falseweight_init=<__main__.Normal object at 0x7fdaf17989d0>, bias_init=zeros, format=NCHW>
(1): LeakyReLU<>
(2): Conv2d<input_channels=64, output_channels=128, kernel_size=(4, 4),stride=(2, 2), pad_mode=pad, padding=1, dilation=(1, 1), group=1, has_bias=Falseweight_init=<__main__.Normal object at 0x7fdaf1798b90>, bias_init=zeros, format=NCHW>
(3): BatchNorm2d<num_features=128, eps=1e-05, momentum=0.09999999999999998, gamma=Parameter (name=3.gamma, shape=(128,), dtype=Float32, requires_grad=True), beta=Parameter (name=3.beta, shape=(128,), dtype=Float32, requires_grad=True), moving_mean=Parameter (name=3.moving_mean, shape=(128,), dtype=Float32, requires_grad=False), moving_variance=Parameter (name=3.moving_variance, shape=(128,), dtype=Float32, requires_grad=False)>
(4): LeakyReLU<>
(5): Conv2d<input_channels=128, output_channels=256, kernel_size=(4, 4),stride=(2, 2), pad_mode=pad, padding=1, dilation=(1, 1), group=1, has_bias=Falseweight_init=<__main__.Normal object at 0x7fdaf18ba350>, bias_init=zeros, format=NCHW>
(6): BatchNorm2d<num_features=256, eps=1e-05, momentum=0.09999999999999998, gamma=Parameter (name=6.gamma, shape=(256,), dtype=Float32, requires_grad=True), beta=Parameter (name=6.beta, shape=(256,), dtype=Float32, requires_grad=True), moving_mean=Parameter (name=6.moving_mean, shape=(256,), dtype=Float32, requires_grad=False), moving_variance=Parameter (name=6.moving_variance, shape=(256,), dtype=Float32, requires_grad=False)>
(7): LeakyReLU<>
(8): Conv2d<input_channels=256, output_channels=512, kernel_size=(4, 4),stride=(2, 2), pad_mode=pad, padding=1, dilation=(1, 1), group=1, has_bias=Falseweight_init=<__main__.Normal object at 0x7fdaf1798c10>, bias_init=zeros, format=NCHW>
(9): BatchNorm2d<num_features=512, eps=1e-05, momentum=0.09999999999999998, gamma=Parameter (name=9.gamma, shape=(512,), dtype=Float32, requires_grad=True), beta=Parameter (name=9.beta, shape=(512,), dtype=Float32, requires_grad=True), moving_mean=Parameter (name=9.moving_mean, shape=(512,), dtype=Float32, requires_grad=False), moving_variance=Parameter (name=9.moving_variance, shape=(512,), dtype=Float32, requires_grad=False)>
(10): LeakyReLU<>
(11): Conv2d<input_channels=512, output_channels=1, kernel_size=(4, 4),stride=(1, 1), pad_mode=pad, padding=0, dilation=(1, 1), group=1, has_bias=Falseweight_init=<__main__.Normal object at 0x7fdaf1798bd0>, bias_init=zeros, format=NCHW>
(12): Sigmoid<>
>
>
连接网络和损失函数
MindSpore将损失函数、优化器等操作都封装到了Cell中,因为GAN结构上的特殊性,其损失是判别器和生成器的多输出形式,这就导致它和一般的分类网络不同。所以我们需要自定义WithLossCell类,将网络和Loss连接起来。
[12]:
class WithLossCellG(nn.Cell):
"""连接生成器和损失"""
def __init__(self, netD, netG, loss_fn):
super(WithLossCellG, self).__init__(auto_prefix=True)
self.netD = netD
self.netG = netG
self.loss_fn = loss_fn
def construct(self, latent_code):
"""构建生成器损失计算结构"""
ones = ops.Ones()
fake_data = self.netG(latent_code)
out = self.netD(fake_data)
label = ones(out.shape, mstype.float32)
loss = self.loss_fn(out, label)
return loss
class WithLossCellD(nn.Cell):
"""连接判别器和损失"""
def __init__(self, netD, netG, loss_fn):
super(WithLossCellD, self).__init__(auto_prefix=True)
self.netD = netD
self.netG = netG
self.loss_fn = loss_fn
def construct(self, real_data, latent_code):
"""构建判别器损失计算结构"""
ones = ops.Ones()
zeros = ops.Zeros()
out1 = self.netD(real_data)
label1 = ones(out1.shape, mstype.float32)
loss1 = self.loss_fn(out1, label1)
fake_data = self.netG(latent_code)
fake_data = ops.stop_gradient(fake_data)
out2 = self.netD(fake_data)
label2 = zeros(out2.shape, mstype.float32)
loss2 = self.loss_fn(out2, label2)
return loss1 + loss2
损失函数和优化器
当定义了D和G后,接下来将使用MindSpore中定义的二进制交叉熵损失函数BCELoss ,为D和G加上损失函数和优化器。
这里设置了两个单独的优化器,一个用于D,另一个用于G。这两个都是lr = 0.0002和beta1 = 0.5的Adam优化器。为此将真实标签定义为1,将虚假标签定义为0,该标签在分别计算D和G的损失时使用。
为了跟踪生成器的学习进度,将生成一批固定的遵循高斯分布的隐向量 fixed_noise。在训练的过程中,定期将fixed_noise输入到G中,可以看到隐向量生成的图像。
[13]:
# 定义损失函数
criterion = nn.BCELoss(reduction='mean')
# 创建一批隐向量用来观察G
np.random.seed(1)
fixed_noise = Tensor(np.random.randn(64, nz, 1, 1),dtype=mstype.float32)
# 为生成器和判别器设置优化器
optimizerD = nn.Adam(netD.trainable_params(), learning_rate=lr, beta1=beta1)
optimizerG = nn.Adam(netG.trainable_params(), learning_rate=lr, beta1=beta1)
训练
训练分为两个主要部分:训练判别器和训练生成器。
训练判别器
训练判别器的目的是最大程度地提高判别图像真伪的概率。按照Goodfellow的方法,是希望通过提高其随机梯度来更新判别器,所以我们要最大化\(log D(x) + log(1 - D(G(z))\)的值。
训练生成器
如DCGAN论文所述,我们希望通过最小化\(log(1 - D(G(z)))\)来训练生成器,以产生更好的虚假图像。
在这两个部分中,分别获取训练过程中的损失,并在每个周期结束时进行统计,将fixed_noise批量推送到生成器中,以直观地跟踪G的训练进度。
下面进行训练:
定义DCGAN网络。
[14]:
class DCGAN(nn.Cell):
def __init__(self, myTrainOneStepCellForD, myTrainOneStepCellForG):
super(DCGAN, self).__init__(auto_prefix=True)
self.myTrainOneStepCellForD = myTrainOneStepCellForD
self.myTrainOneStepCellForG = myTrainOneStepCellForG
def construct(self, real_data, latent_code):
output_D = self.myTrainOneStepCellForD(real_data, latent_code).view(-1)
netD_loss = output_D.mean()
output_G = self.myTrainOneStepCellForG(latent_code).view(-1)
netG_loss = output_G.mean()
return netD_loss, netG_loss
实例化生成器和判别器的
WithLossCell和TrainOneStepCell。
[15]:
# 实例化WithLossCell
netD_with_criterion = WithLossCellD(netD, netG, criterion)
netG_with_criterion = WithLossCellG(netD, netG, criterion)
# 实例化TrainOneStepCell
myTrainOneStepCellForD = nn.TrainOneStepCell(netD_with_criterion, optimizerD)
myTrainOneStepCellForG = nn.TrainOneStepCell(netG_with_criterion, optimizerG)
循环训练网络,每经过50次迭代,就收集生成器和判别器的损失,以便于后面绘制训练过程中损失函数的图像。
[16]:
# 实例化DCGAN网络
dcgan = DCGAN(myTrainOneStepCellForD, myTrainOneStepCellForG)
dcgan.set_train()
#创建迭代器
data_loader = data.create_dict_iterator(output_numpy=True, num_epochs=num_epochs)
G_losses = []
D_losses = []
iters = 0
image_list = []
# 开始循环训练
print("Starting Training Loop...")
for epoch in range(num_epochs):
# 为每轮训练读入数据
for i, d in enumerate(data_loader):
real_data = Tensor(d['image'])
latent_code = Tensor(d["latent_code"])
netD_loss, netG_loss = dcgan(real_data, latent_code)
if i % 50 == 0:
# 输出训练记录
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f'% (epoch + 1, num_epochs, i, size, netD_loss.asnumpy(), netG_loss.asnumpy()))
D_losses.append(netD_loss.asnumpy())
G_losses.append(netG_loss.asnumpy())
if (iters % 100) == 0 or ((epoch == num_epochs) and (i == size-1)):
img = netG(fixed_noise)
image_list.append(img)
iters += 1
[1/10][0/54] Loss_D: 2.4556 Loss_G: 3.0041
[1/10][50/54] Loss_D: 0.1433 Loss_G: 7.6950
[2/10][0/54] Loss_D: 0.1365 Loss_G: 8.8596
[2/10][50/54] Loss_D: 0.1310 Loss_G: 8.7747
[3/10][0/54] Loss_D: 0.0504 Loss_G: 10.5596
[3/10][50/54] Loss_D: 0.8163 Loss_G: 8.0759
[4/10][0/54] Loss_D: 0.3023 Loss_G: 5.7986
[4/10][50/54] Loss_D: 0.5194 Loss_G: 4.3674
[5/10][0/54] Loss_D: 0.3352 Loss_G: 3.4594
[5/10][50/54] Loss_D: 0.4974 Loss_G: 4.4283
[6/10][0/54] Loss_D: 0.3801 Loss_G: 4.0097
[6/10][50/54] Loss_D: 0.8006 Loss_G: 6.6378
[7/10][0/54] Loss_D: 0.3117 Loss_G: 4.2992
[7/10][50/54] Loss_D: 0.2790 Loss_G: 4.5312
[8/10][0/54] Loss_D: 0.2849 Loss_G: 3.6189
[8/10][50/54] Loss_D: 0.2666 Loss_G: 3.8770
[9/10][0/54] Loss_D: 0.4683 Loss_G: 5.4351
[9/10][50/54] Loss_D: 0.5192 Loss_G: 1.4136
[10/10][0/54] Loss_D: 1.4602 Loss_G: 9.7650
[10/10][50/54] Loss_D: 0.5070 Loss_G: 5.3808
结果
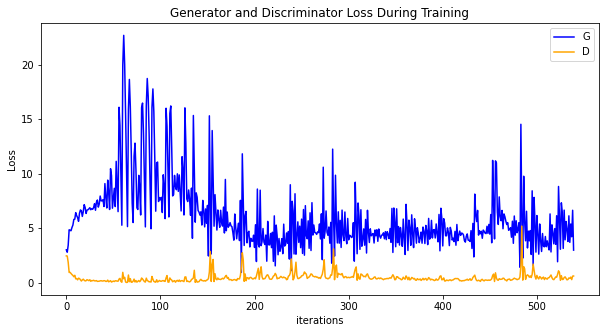
运行下面代码,描绘
D和G损失与训练迭代的关系图:
[17]:
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses,label="G",color='blue')
plt.plot(D_losses,label="D",color='orange')
plt.xlabel("iterations")
plt.ylabel("Loss")
plt.legend()
plt.show()
可视化训练过程中通过隐向量
fixed_noise生成的图像,每次只取9张图像展示。

由上图可见训练过的网络成功生成了虚假名人图像。