异构存储
![]()
概述
近几年基于Transformer的大模型在nlp和视觉的各个下游任务上取得了快速发展,往往模型越大,下游任务取得的精度越高。模型规模从亿级到千亿级发展,然而大模型训练需要消耗大量的计算存储资源,训练开销巨大。
大模型训练受显存大小限制,在单卡上能够存储的模型参数量有限。通过模型并行,我们可以将大模型拆分到不同的机器上,在引入必要的进程间通信后,进行集群协同训练,模型规模跟机器规模成正比。同时模型规模超过单机显存容量时,模型并行进行跨机通信的开销将越来越大,资源利用率将会显著下降,如何在单机上训练更大的模型,避免模型并行跨机通信成为大模型训练性能提升的关键。
通过异构存储管理,能够实现模型参数10倍到100倍的存储扩展,从而打破大模型训练的显存限制,实现低成本的大模型训练。本篇教程将会阐述异构存储管理基本原理并介绍相关配置参数及其使用。使用本特性,开发者可以使用相同的硬件训练更大的模型。
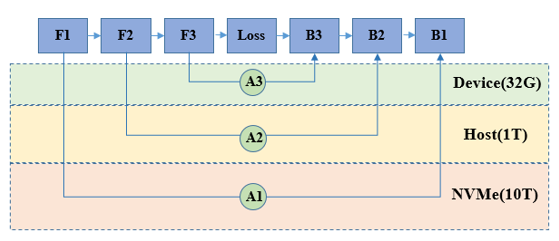
异构存储管理基本原理
在训练过程中,主要的存储数据由参数和中间结果构成:
参数:模型的权重及优化器的状态量等数据,在训练过程中需要一直存储
中间结果:正反向及优化过程中计算产生的数据,在对应计算完成后可以释放删除
通过异构存储管理,可以在训练过程中,将暂时不需要参与计算的参数或中间结果拷贝至Host侧内存,甚至硬盘存储,在需要数据参与计算时,再将其拷贝恢复至设备侧。通过上述手段,可以提升相同硬件设备能够训练的模型规模。
代码示例
以ResNet-50网络为例,代码实现参考示例。目录结构如下所示,其中resnet.py是ResNet-50网络实现,cifa_resnet50.py是训练脚本,run.sh是执行脚本。
└─sample_code
├─memory_offload
│ resnet.py
│ cifa_resnet50.py
│ run.sh
...
bash run.sh Ascend 512 OFF
不开启异构存储的情况下,使用batch_size=512进行训练时,由于显存空间不够,会出现’Out of Memory’报错:
----------------------------------------------------
- Framework Error Message:
----------------------------------------------------
Out of Memory!!! Request memory size: 33100113920B, Memory Statistic:
Device HBM memory size: 32768M
MindSpore Used memory size: 30684M
MindSpore memory base address: 0x124140000000
Total Static Memory size: 496M
Total Dynamic memory size: 0M
Dynamic memory size of this graph: 0M
Please try to reduce 'batch_size' or check whether exists extra large shape. For more details, please refer to 'Out of Memory' at https://www.mindspore.cn .
----------------------------------------------------
- C++ Call Stack: (For framework developers)
----------------------------------------------------
mindspore/ccsrc/plugin/device/ascend/hal/hardware/ascend_kernel_executor.cc:252 PreprocessBeforeRunGraph
mindspore/ccsrc/plugin/device/ascend/hal/device/ascend_memory_adapter.cc:169 MallocDynamicDevMem
开启异构存储后,能够正常使用batch_size=512训练:
bash run.sh Ascend 512 ON
epoch: 1 step: 111, loss is 2.1563000679016113
epoch: 1 step: 112, loss is 2.1421408653259277
epoch: 1 step: 113, loss is 2.129314422607422
epoch: 1 step: 114, loss is 2.127141237258911
epoch: 1 step: 115, loss is 2.1191487312316895
epoch: 1 step: 116, loss is 2.1299633979797363
epoch: 1 step: 117, loss is 2.138218402862549
异构存储配置及开关代码:
import mindspore
offload_config = {"offload_param": "cpu",
"auto_offload": False,
"offload_cpu_size": "512GB",
"offload_disk_size": "1024GB",
"offload_path": "./offload/",
"host_mem_block_size":"1GB",
"enable_aio": True,
"enable_pinned_mem": True}
mindspore.set_context(mode=mindspore.GRAPH_MODE, memory_offload='ON', max_device_memory='30GB')
mindspore.set_offload_context(offload_config=offload_config)
offload_config 是异构存储的配置选项,其中
"offload_param": "cpu"设置模型的参数被存储于cpu内存上,仅在训练过程中需要使用数据时加载至设备侧,使用完成后随即卸载至cpu内存。"auto_offload": False设置关闭自动offload策略,parameter数据将严格安装上一条配置选项执行。"offload_cpu_size": "512GB", "offload_disk_size": "1024GB"分别设置了可用于offload的cpu内存和磁盘大小。"offload_path": "./offload/"设置用于offload的磁盘文件路径。"enable_pinned_mem": True设置开启锁页,开启后可加速片上内存-CPU内存之间的拷贝。"host_mem_block_size":"1GB"设置cpu锁页内存池block大小。"enable_aio": True设置开启文件异步IO,开启后可加速DDR-磁盘之间的拷贝。(需要编译时带上-o选项,且仅支持安装了aio的Linux环境)
本示例中将offload_param参数配置为”cpu”且没有开启auto_offload,在整个训练过程中,参数都将存储在cpu内存中。在需要使用某些参数参与计算时,数据将被拷贝至设备侧,完成计算后,重新拷回cpu内存。
自动生成offload策略
除了严格安装用户"offload_param"的配置进行数据拷贝,MindSpore还支持自动生成异构存储策略。MindSpore可以通过分析网络的显存使用信息,并结合用户配置的"max_device_memory"、"offload_cpu_size"、"offload_disk_size"、"hbm_ratio"、"cpu_ratio"等参数生成异构存储策略,并按照既定策略在多种存储介质中进行数据搬移。
import mindspore
offload_config = {"offload_path": "./offload/",
"auto_offload": True,
"offload_param": "cpu",
"offload_cpu_size": "512GB",
"offload_disk_size": "1024GB",
"host_mem_block_size":"1GB",
"enable_aio": True,
"enable_pinned_mem": True}
mindspore.set_context(mode=mindspore.GRAPH_MODE, memory_offload='ON', max_device_memory='30GB')
mindspore.set_offload_context(offload_config=offload_config)
本示例中设置了"auto_offload": True,"offload_param"只会影响parameter的初始存储位置,计算过程中框架会根据生成的策略来调整权重和中间结果的存放位置。