数据准备异构加速
![]()
概述
MindSpore提供了一种运算负载均衡的技术,可以将MindSpore的Tensor运算分配到不同的异构硬件上,一方面均衡不同硬件之间的运算开销,另一方面利用异构硬件的优势对运算进行加速。
目前该异构硬件加速技术仅支持将数据处理操作均衡到网络侧,均衡数据处理管道与网络运算的计算开销。具体来说,目前数据处理管道的操作均在CPU侧运算,该功能将部分数据操作从CPU侧“移动”到网络端,利用昇腾Ascend或GPU的计算资源对数据数据处理的操作进行加速。
该功能仅支持将作用于特定数据输入列末端的数据增强操作移至异构侧进行加速,输入列末端指的是作用于该数据的map操作所持有的位于末端且连续的数据增强操作。
当前支持异构加速功能的数据增强操作有:
操作名 |
操作位置 |
操作功能 |
|---|---|---|
HWC2CHW |
mindspore.dataset.vision.transforms.py |
将图像的维度从(H,W,C) 转换为 (C,H,W) |
Normalize |
mindspore.dataset.vision.transforms.py |
对图像进行标准化 |
RandomColorAdjust |
mindspore.dataset.vision.transforms.py |
对图像进行随机颜色调整 |
RandomHorizontalFlip |
mindspore.dataset.vision.transforms.py |
对图像进行随机水平翻转 |
RandomSharpness |
mindspore.dataset.vision.transforms.py |
对图像进行随机锐化 |
RandomVerticalFlip |
mindspore.dataset.vision.transforms.py |
对图像进行随机垂直翻转 |
Rescale |
mindspore.dataset.vision.transforms.py |
对图像的像素值进行缩放 |
TypeCast |
mindspore.dataset.transforms.transforms.py |
将张量强制转换为给定的MindSpore数据类型 |
流程
下图显示了给定数据处理管道使用异构加速的典型计算过程。
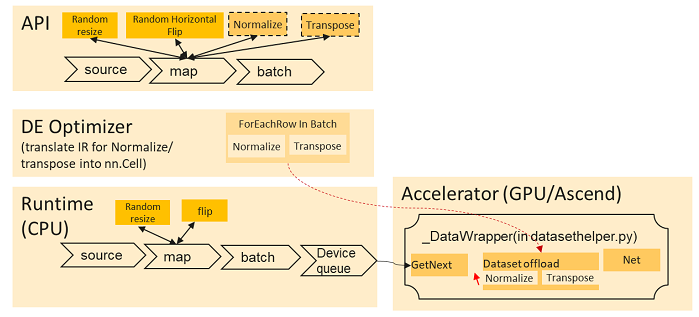
异构加速功能提供了两个API以允许用户启用此功能:
map操作中提供offload入参,
数据集全局配置mindspore.dataset.config中提供set_auto_offload接口。
如需检查数据增强操作是否移动至加速器,用户可以保存并检查计算图IR文件。在异构加速功能被启动后,相关计算算子会被写入IR文件中。异构加速功能同时适用于数据集下沉模式(dataset_sink_mode=True)和数据集非下沉模式(dataset_sink_mode=False)。
如何使用数据准备异构加速
MindSpore提供两种方式供用户启用数据准备异构加速功能。
方法 1
使用全局配置设置自动异构加速。在这种情况下,所有map操作的offload参数将设置为True(默认为None)。值得注意的是,如果用户指定特定map操作的offload为False,该map操作将直接应用该配置而不是全局配置。
import mindspore.dataset as ds
ds.config.set_auto_offload(True)
方法 2
在map操作中将参数offload设置为True(offload默认值为None)。
import mindspore.dataset as ds
import mindspore.common.dtype as mstype
import mindspore.dataset.vision as vision
import mindspore.dataset.transforms as transforms
dataset = ds.ImageFolder(dir)
type_cast_op = transforms.TypeCast(mstype.int32)
image_ops = [vision.RandomCropDecodeResize(train_image_size),
vision.RandomHorizontalFlip(prob=0.5),
vision.Normalize(mean=mean, std=std),
vision.HWC2CHW()]
dataset = dataset.map(operations=type_cast_op, input_columns="label", offload=True)
dataset = dataset.map(operations=image_ops, input_columns="image", offload=True)
异构硬件加速技术支持应用于具有多个数据输入列的数据集,如下例所示。
dataset = dataset.map(operations=type_cast_op, input_columns="label")
dataset = dataset.map(operations=copy_column,
input_columns=["image", "label"],
output_columns=["image1", "image2", "label"])
dataset = dataset.map(operations=image_ops, input_columns=["image1"], offload=True)
dataset = dataset.map(operations=image_ops, input_columns=["image2"], offload=True)
约束条件
异构加速器功能目前仍处于开发阶段。当前的功能使用受到以下条件限制:
该功能目前不支持经过数据管道操作concat和zip处理后的数据集。
异构加速操作必须是作用于特定数据输入列的最后一个或多个连续的数据增强操作,但数据输入列的处理顺序无限制,如
dataset = dataset.map(operations=type_cast_op, input_columns="label", offload=True)
可以在
dataset = dataset.map(operations=image_ops, input_columns="image", offload=False)
之前,也就是说即使作用于”image”列的map操作未设置offload,作用于”label”列的map操作也可以执行offload。
该功能目前不支持用户在map操作中指定输出列。