Host&Device Heterogeneous
![]()
Overview
In deep learning, one usually has to deal with the huge model problem, in which the total size of parameters in the model is beyond the device memory capacity. To efficiently train a huge model, one solution is to employ homogeneous accelerators (e.g., Atlas training series and GPU) for distributed training. When the size of a model is hundreds of GBs or several TBs, the number of required accelerators is too overwhelming for people to access, resulting in this solution inapplicable. One alternative is Host+Device hybrid training. This solution simultaneously leveraging the huge memory in hosts and fast computation in accelerators, is a promisingly efficient method for addressing huge model problem.
In MindSpore, users can easily implement hybrid training by configuring trainable parameters and necessary operators to run on hosts, and other operators to run on accelerators.
Related interfaces:
mindspore.ops.Primitive.set_device(): Set Primitive to execute the backend.mindspore.nn.Optimizer.target: This attribute specifies whether the parameter should be updated on the host or on the device. The input type is str and can only be “CPU”, “Ascend” or “GPU”.
Basic Principle
Pipeline parallel and operator-level parallel are suitable for the model to have a large number of operators, and the parameters are more evenly distributed among the operators. What if the number of operators in the model is small, and the parameters are concentrated in only a few operators? Wide & Deep is an example of this, as shown in the image below. The Embedding table in Wide & Deep can be trained as a parameter of hundreds of GIGabytes or even a few terabytes. If it is executed on an accelerator (device), the number of accelerators required is huge, and the training cost is expensive. On the other hand, if you use accelerator computing, the training acceleration obtained is limited, and it will also trigger cross-server traffic, and the end-to-end training efficiency will not be very high.
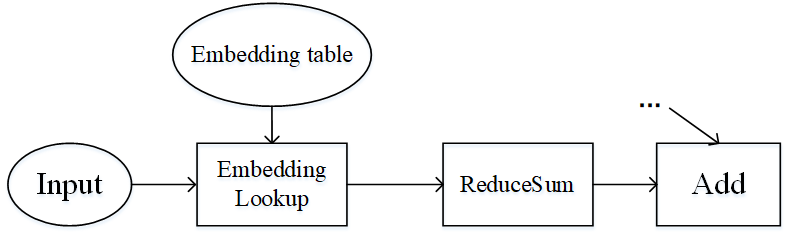
Figure: Part of the structure of the Wide & Deep model
A careful analysis of the special structure of the Wide & Deep model can be obtained: although the Embedding table has a huge amount of parameters, it participates in very little computation, and the Embedding table and its corresponding operator, the EmbeddingLookup operator, can be placed on the Host side, by using the CPU for calculation, and the rest of the operators are placed on the accelerator side. This can take advantage of the large amount of memory on the Host side and the fast computing of the accelerator side, while taking advantage of the high bandwidth of the Host to accelerator of the same server. The following diagram shows how Wide & Deep heterogeneous slicing works:
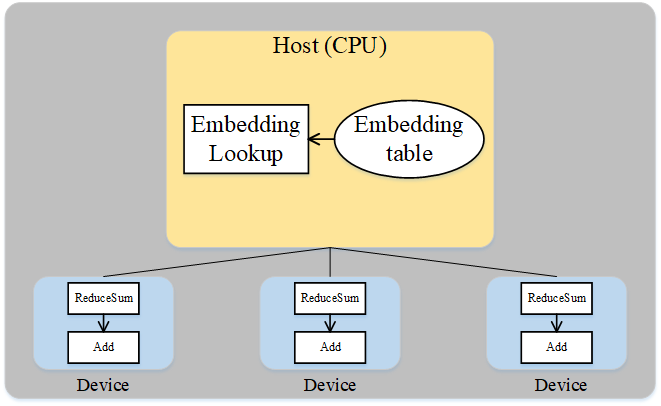
Figure: Wide & Deep Heterogeneous Approach
Operator Practices
The following is an illustration of Host&Device heterogeneous operation using Ascend or GPU stand-alone 8-card as an example:
Sample Code Description
Download the complete example code: host_device.
The directory structure is as follows:
└─ sample_code
├─ host_device
├── train.py
└── run.sh
...
train.py is the script that defines the network structure and the training process. run.sh is the execution script.
Configuring a Distributed Environment
Specify the run mode, run device, run card number via the context interface. Parallel mode is the data parallel mode and initialize HCCL or NCCL communication via init. The device_target is automatically specified as the backend hardware device corresponding to the MindSpore package.
import mindspore as ms
from mindspore.communication import init
ms.set_context(mode=ms.GRAPH_MODE)
ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.DATA_PARALLEL, gradients_mean=True)
init()
ms.set_seed(1)
Loading the Dataset
The dataset is loaded and the data is parallelized consistently with the following code:
import os
import mindspore.dataset as ds
def create_dataset(batch_size):
dataset_path = os.getenv("DATA_PATH")
rank_id = get_rank()
rank_size = get_group_size()
dataset = ds.MnistDataset(dataset_path, num_shards=rank_size, shard_id=rank_id)
image_transforms = [
ds.vision.Rescale(1.0 / 255.0, 0),
ds.vision.Normalize(mean=(0.1307,), std=(0.3081,)),
ds.vision.HWC2CHW()
]
label_transform = ds.transforms.TypeCast(ms.int32)
dataset = dataset.map(image_transforms, 'image')
dataset = dataset.map(label_transform, 'label')
dataset = dataset.batch(batch_size)
return dataset
data_set = create_dataset(32)
Defining the Network
The network definition differs from a single-card network in that the ops.Add() operator is configured to run on the host side with the following code:
import mindspore as ms
from mindspore import nn, ops
from mindspore.common.initializer import initializer
class Dense(nn.Cell):
def __init__(self, in_channels, out_channels):
super().__init__()
self.weight = ms.Parameter(initializer("normal", [in_channels, out_channels], ms.float32))
self.bias = ms.Parameter(initializer("normal", [out_channels], ms.float32))
self.matmul = ops.MatMul()
self.add = ops.Add()
def construct(self, x):
x = self.matmul(x, self.weight)
x = self.add(x, self.bias)
return x
class Network(nn.Cell):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.layer1 = Dense(28*28, 512)
self.relu1 = nn.ReLU()
self.layer2 = Dense(512, 512)
self.relu2 = nn.ReLU()
self.layer3 = Dense(512, 10)
def construct(self, x):
x = self.flatten(x)
x = self.layer1(x)
x = self.relu1(x)
x = self.layer2(x)
x = self.relu2(x)
logits = self.layer3(x)
return logits
net = Network()
# Configurethe matmul and add operators to run on the CPU side
net.layer1.matmul.set_device("CPU")
net.layer1.add.set_device("CPU")
net.layer2.matmul.set_device("CPU")
net.layer2.add.set_device("CPU")
net.layer3.matmul.set_device("CPU")
net.layer3.add.set_device("CPU")
Training the Network
The loss function, optimizer, and training process are consistent with those in the data parallel:
from mindspore import nn
import mindspore as ms
optimizer = nn.SGD(net.trainable_params(), 1e-2)
loss_fn = nn.CrossEntropyLoss()
def forward_fn(data, target):
logits = net(data)
loss = loss_fn(logits, target)
return loss, logits
grad_fn = ms.value_and_grad(forward_fn, None, net.trainable_params(), has_aux=True)
grad_reducer = nn.DistributedGradReducer(optimizer.parameters)
for epoch in range(5):
i = 0
for image, label in data_set:
(loss_value, _), grads = grad_fn(image, label)
grads = grad_reducer(grads)
optimizer(grads)
if i % 100 == 0:
print("epoch: %s, step: %s, loss is %s" % (epoch, i, loss_value))
i += 1
Running Stand-alone 8-card Script
In order to save enough log information, you need to set the log level to INFO by adding the command export GLOG_v=1 to the executing script. Next, the corresponding script is called by the command, and the distributed training script with mpirun startup method and 8 cards is used as an example for distributed training:
bash run.sh
After training, the part of results about the Loss are saved in log_output/1/rank.*/stdout, and the example is as follows:
...
epoch: 0, step: 0, loss is 2.3029172
...
epoch: 0, step: 100, loss is 2.2896261
...
epoch: 0, step: 200, loss is 2.2694492
...
Search for the keyword CPU and find the following information:
...
[INFO] PRE_ACT(3533591,7f5e5d1e8740,python):2023-09-01-15:14:11.164.420 [mindspore/ccsrc/backend/common/pass/convert_const_input_to_attr.cc:44] Process] primitive target does not match backend: GPU, primitive_target: CPU, node name: Default/Add-op108
...
Indicates that the Add operator is configured to run on the CPU side.