Dataset AutoTune for Dataset Pipeline
![]()
Overview
MindSpore provides a tool named Dataset AutoTune to help optimize the dataset pipeline. Dataset AutoTune can automatically tune dataset pipelines to improve performance.
This feature can automatically detect a bottleneck operation in the dataset pipeline and respond by automatically adjusting tunable parameters for dataset operations, like increasing the number of parallel workers or updating the prefetch size of dataset operations.
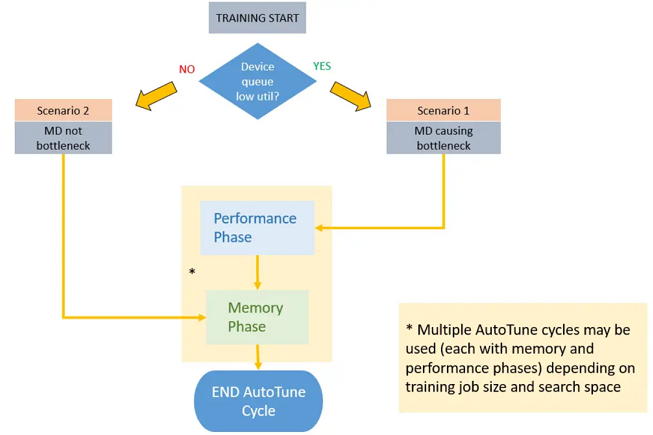
With Dataset AutoTune enabled, MindSpore will sample dataset statistics at a given interval, which is tuneable by the user.
Once Dataset AutoTune collects enough information, it will analyze whether the performance bottleneck is on the dataset side or not. If so, it will adjust the parallelism and speedup the dataset pipeline. If not, Dataset AutoTune will also try to reduce the memory usage of the dataset pipeline to release memory for CPU.
Dataset AutoTune is disabled by default.
Enabling Dataset AutoTune
To enable Dataset AutoTune (without saving the recommended configuration after tuning):
import mindspore.dataset as ds
ds.config.set_enable_autotune(True)
To enable Dataset AutoTune plus save the more efficient dataset pipeline in a configuration file:
import mindspore.dataset as ds
ds.config.set_enable_autotune(True, "/path/to/autotune_out")
Tuning Interval for Dataset AutoTune
The frequency at which Dataset AutoTune will adjust the dataset pipeline can be customized. To set the tuning interval in steps:
import mindspore.dataset as ds
ds.config.set_autotune_interval(100)
To set the tuning interval to be after every epoch, set the tuning interval to 0.
To query the tuning interval for dataset pipeline autotuning:
import mindspore.dataset as ds
print("tuning interval:", ds.config.get_autotune_interval())
Constraints
Both Dataset Profiling and Dataset AutoTune cannot be enabled concurrently, since Profiling's additional processing interferes with Dataset AutoTune's optimization processing. If both of them are enabled at the same time, a warning message will prompt the user to check whether there is a mistake. Do ensure Profiling is disabled when using Dataset AutoTune.
Offload for Dataset and Dataset AutoTune can be enabled simultaneously. If any dataset node has been offloaded for hardware acceleration, the more efficient dataset pipeline configuration file will not be stored and a warning will be logged, because the dataset pipeline that is actually running is not the predefined one.
If the Dataset pipeline consists of a node that does not support deserialization (e.g. user-defined Python functions, GeneratorDataset), any attempt to deserialize the saved and improved dataset pipeline configuration file will report an error. In this case, it is recommended to manually modify the dataset pipeline script based on the contents of the tuning configuration file to achieve the purpose of a more efficient dataset pipeline.
In the distributed training scenario,
set_enable_autotune()must be called after cluster communication has been initialized (mindspore.communication.management.init()), otherwise AutoTune can only detect device with id 0 and create only one tuned file (the number of expected tuned files equal to the number of devices). See the following example:In distributed multi-card training scenarios, Dataset AutoTune needs to be enabled only after cluster initialization is complete:
import mindspore.dataset as ds from mindspore.communication.management import init init() ... def create_dataset(): ds.config.set_enable_autotune(True, "/path/to/autotune_out") ds.Cifar10Dataset() ...
instead of
import mindspore.dataset as ds from mindspore.communication.management import init ds.config.set_enable_autotune(True, "/path/to/autotune_out") init() ... def create_dataset(): ds.Cifar10Dataset() ...
Example
Take ResNet training as example.
Dataset AutoTune Config
To enable Dataset AutoTune, only one statement is needed.
# dataset.py of ResNet in ModelZoo
# models/official/cv/resnet/src/dataset.py
def create_dataset(...)
"""
create dataset for train or test
"""
# enable Dataset AutoTune
ds.config.set_enable_autotune(True, "/path/to/autotune_out")
# no changes required for other dataset codes
data_set = ds.Cifar10Dataset(data_path)
...
Starting Training
Start the training process as described in resnet/README.md. Dataset AutoTune will display its analysis result through log messages.
[INFO] [auto_tune.cc:73 LaunchThread] Launching Dataset AutoTune thread
[INFO] [auto_tune.cc:35 Main] Dataset AutoTune thread has started.
[INFO] [auto_tune.cc:191 RunIteration] Run Dataset AutoTune at epoch #1
[INFO] [auto_tune.cc:203 RecordPipelineTime] Epoch #1, Average Pipeline time is 21.6624 ms. The avg pipeline time for all epochs is 21.6624ms
[INFO] [auto_tune.cc:231 IsDSaBottleneck] Epoch #1, Device Connector Size: 0.0224, Connector Capacity: 1, Utilization: 2.24%, Empty Freq: 97.76%
epoch: 1 step: 1875, loss is 1.1544309
epoch time: 72110.166 ms, per step time: 38.459 ms
[WARNING] [auto_tune.cc:236 IsDSaBottleneck] Utilization: 2.24% < 75% threshold, dataset pipeline performance needs tuning.
[WARNING] [auto_tune.cc:297 Analyse] Op (MapOp(ID:3)) is slow, input connector utilization=0.975806, output connector utilization=0.298387, diff= 0.677419 > 0.35 threshold.
[WARNING] [auto_tune.cc:253 RequestNumWorkerChange] Added request to change "num_parallel_workers" of Operator: MapOp(ID:3)From old value: [2] to new value: [4].
[WARNING] [auto_tune.cc:309 Analyse] Op (BatchOp(ID:2)) getting low average worker cpu utilization 1.64516% < 35% threshold.
[WARNING] [auto_tune.cc:263 RequestConnectorCapacityChange] Added request to change "prefetch_size" of Operator: BatchOp(ID:2)From old value: [1] to new value: [5].
epoch: 2 step: 1875, loss is 0.64530635
epoch time: 24519.360 ms, per step time: 13.077 ms
[WARNING] [auto_tune.cc:236 IsDSaBottleneck] Utilization: 0.0213516% < 75% threshold, dataset pipeline performance needs tuning.
[WARNING] [auto_tune.cc:297 Analyse] Op (MapOp(ID:3)) is slow, input connector utilization=1, output connector utilization=0, diff= 1 > 0.35 threshold.
[WARNING] [auto_tune.cc:253 RequestNumWorkerChange] Added request to change "num_parallel_workers" of Operator: MapOp(ID:3)From old value: [4] to new value: [6].
[WARNING] [auto_tune.cc:309 Analyse] Op (BatchOp(ID:2)) getting low average worker cpu utilization 4.39062% < 35% threshold.
[WARNING] [auto_tune.cc:263 RequestConnectorCapacityChange] Added request to change "prefetch_size" of Operator: BatchOp(ID:2)From old value: [5] to new value: [9].
epoch: 3 step: 1875, loss is 0.9806979
epoch time: 17116.234 ms, per step time: 9.129 ms
...
[INFO] [profiling.cc:703 Stop] MD Autotune is stopped.
[INFO] [auto_tune.cc:52 Main] Dataset AutoTune thread is finished.
[INFO] [auto_tune.cc:53 Main] Printing final tree configuration
[INFO] [auto_tune.cc:66 PrintTreeConfiguration] CifarOp(ID:5) num_parallel_workers: 2 prefetch_size: 2
[INFO] [auto_tune.cc:66 PrintTreeConfiguration] MapOp(ID:4) num_parallel_workers: 1 prefetch_size: 2
[INFO] [auto_tune.cc:66 PrintTreeConfiguration] MapOp(ID:3) num_parallel_workers: 10 prefetch_size: 2
[INFO] [auto_tune.cc:66 PrintTreeConfiguration] BatchOp(ID:2) num_parallel_workers: 8 prefetch_size: 17
[INFO] [auto_tune.cc:55 Main] Suggest to set proper num_parallel_workers for each Operation or use global setting API: mindspore.dataset.config.set_num_parallel_workers
[INFO] [auto_tune.cc:57 Main] Suggest to choose maximum prefetch_size from tuned result and set by global setting API: mindspore.dataset.config.set_prefetch_size
Some analysis to explain the meaning of the log information:
How to check process of Dataset AutoTune:
Dataset AutoTune displays common status log information at INFO level. However, when AutoTune detects a bottleneck in the dataset pipeline, it will try to modify the parameters of dataset pipeline ops, and display this analysis log information at WARNING level.
How to read log messages:
The initial configuration of the dataset pipeline is suboptimal (Utilization of Device Connector is low).
[INFO] [auto_tune.cc:231 IsDSaBottleneck] Epoch #1, Device Connector Size: 0.0224, Connector Capacity: 1, Utilization: 2.24%, Empty Freq: 97.76% [WARNING] [auto_tune.cc:236 IsDSaBottleneck] Utilization: 2.24% < 75% threshold, dataset pipeline performance needs tuning.
The reason is mainly that the data processing pipeline generates data slowly and the network side reads the generated data very quickly. Based on this, Dataset AutoTune module adjusts the number of working threads ("num_parallel_workers") of MapOp(ID:3) and the depth of internal queue ("prefetch_size") of BatchOp(ID:2) operation.
[WARNING] [auto_tune.cc:297 Analyse] Op (MapOp(ID:3)) is slow, input connector utilization=0.975806, output connector utilization=0.298387, diff= 0.677419 > 0.35 threshold. [WARNING] [auto_tune.cc:253 RequestNumWorkerChange] Added request to change "num_parallel_workers" of Operator: MapOp(ID:3)From old value: [2] to new value: [4]. [WARNING] [auto_tune.cc:309 Analyse] Op (BatchOp(ID:2)) getting low average worker cpu utilization 1.64516% < 35% threshold. [WARNING] [auto_tune.cc:263 RequestConnectorCapacityChange] Added request to change "prefetch_size" of Operator: BatchOp(ID:2)From old value: [1] to new value: [5].
After tuning the configuration of the dataset pipeline, the step time is reduced.
epoch: 1 step: 1875, loss is 1.1544309 epoch time: 72110.166 ms, per step time: 38.459 ms epoch: 2 step: 1875, loss is 0.64530635 epoch time: 24519.360 ms, per step time: 13.077 ms epoch: 3 step: 1875, loss is 0.9806979 epoch time: 17116.234 ms, per step time: 9.129 ms
At the end of training, an improved configuration is created by Dataset AutoTune. For num_parallel_workers, Dataset AutoTune suggests to set new value for each Operation or using global setting API. For prefetch_size, Dataset AutoTune suggests to choose the maximum value and set by global setting API.
[INFO] [auto_tune.cc:66 PrintTreeConfiguration] CifarOp(ID:5) num_parallel_workers: 2 prefetch_size: 2 [INFO] [auto_tune.cc:66 PrintTreeConfiguration] MapOp(ID:4) num_parallel_workers: 1 prefetch_size: 2 [INFO] [auto_tune.cc:66 PrintTreeConfiguration] MapOp(ID:3) num_parallel_workers: 10 prefetch_size: 2 [INFO] [auto_tune.cc:66 PrintTreeConfiguration] BatchOp(ID:2) num_parallel_workers: 8 prefetch_size: 17 [INFO] [auto_tune.cc:55 Main] Suggest to set proper num_parallel_workers for each Operation or use global setting API: mindspore.dataset.config.set_num_parallel_workers [INFO] [auto_tune.cc:57 Main] Suggest to choose maximum prefetch_size from tuned result and set by global setting API: mindspore.dataset.config.set_prefetch_size
Saving AutoTune Recommended Configuration
Since Dataset AutoTune was enabled to generate a more efficient dataset pipeline, the improved dataset pipeline can be serialized (by passing in the 'filepath_prefix' parameter) and saved to the JSON configuration file.
After passing string to filepath_prefix, AutoTune will automatically generate JSON files corresponding to the device number according to the current training mode in a standalone or distributed environment.
For example, configure filepath_prefix='autotune_out'.
In distributed training on 4 devices, AutoTune will generate 4 tuning files: autotune_out_0.json, autotune_out_1.json, autotune_out_2.json, autotune_out_3.json, corresponding to the configuration of the dataset pipeline of the 4 devices.
In a standalone training on 1 device, AutoTune will generate autotune_out_0.json, which corresponds to the configuration of the dataset pipeline on this device.
Example of the JSON configuration file:
{
"remark": "The following file has been auto-generated by the Dataset AutoTune.",
"summary": [
"CifarOp(ID:5) (num_parallel_workers: 2, prefetch_size: 2)",
"MapOp(ID:4) (num_parallel_workers: 1, prefetch_size: 2)",
"MapOp(ID:3) (num_parallel_workers: 10, prefetch_size: 2)",
"BatchOp(ID:2) (num_parallel_workers: 8, prefetch_size: 17)"
],
"tree": {...}
}
The file starts with a summary of the configuration and is followed by the actual dataset pipeline (tree) information. The file is loadable using the deserialization API mindspore.dataset.deserialize.
Notes on the JSON configuration file:
Non-parallel dataset operations will show
NAfornum_parallel_workers.
Loading AutoTune Configuration
If Dataset AutoTune generated an improved pipeline configuration file, use deserialize support to load the dataset pipeline:
import mindspore.dataset as ds
new_dataset = ds.deserialize("/path/to/autotune_out_0.json")
The new_dataset is the tuned dataset object containing operations from Cifar to Batch as shown in the JSON content above.
Before Next Training
Before starting the next training process, the user can update the dataset loading code according to recommended improvements from Dataset AutoTune for a more efficient dataset pipeline.
This allows the dataset pipeline to be run at an improved speed from the beginning of the training process.
By the way, MindSpore also provides APIs to set the global value of num_parallel_workers and prefetch_size.
Please refer to mindspore.dataset.config: