Pipeline Parallel
![]()
Overview
In recent years, the scale of neural networks has increased exponentially. Limited by the memory on a single device, the number of devices used for training large models is also increasing. Due to the low communication bandwidth between servers, the performance of the conventional hybrid parallelism (data parallel + model parallel) is poor. Therefore, pipeline parallelism needs to be introduced. Pipeline parallel can divide a model in space based on stage. Each stage needs to execute only a part of the network, which greatly reduces memory overheads, shrinks the communication domain, and shortens the communication time. MindSpore can automatically convert a standalone model to the pipeline parallel mode based on user configurations.
Basic Principle
Pipeline parallel is the splitting of operators in a neural network into multiple stages, and then mapping the stages to different devices, so that different devices can compute different parts of the neural network. Pipeline parallel is suitable for graph structures where the model is linear. As shown in Figure 1, the network of 4 layers of MatMul is split into 4 stages and distributed to 4 devices. In forward calculations, each machine sends the result to the next machine through the communication operator after calculating the MatMul on the machine, and at the same time, the next machine receives (Receive) the MatMul result of the previous machine through the communication operator, and starts to calculate the MatMul on the machine; In reverse calculation, after the gradient of the last machine is calculated, the result is sent to the previous machine, and at the same time, the previous machine receives the gradient result of the last machine and begins to calculate the reverse of the current machine.
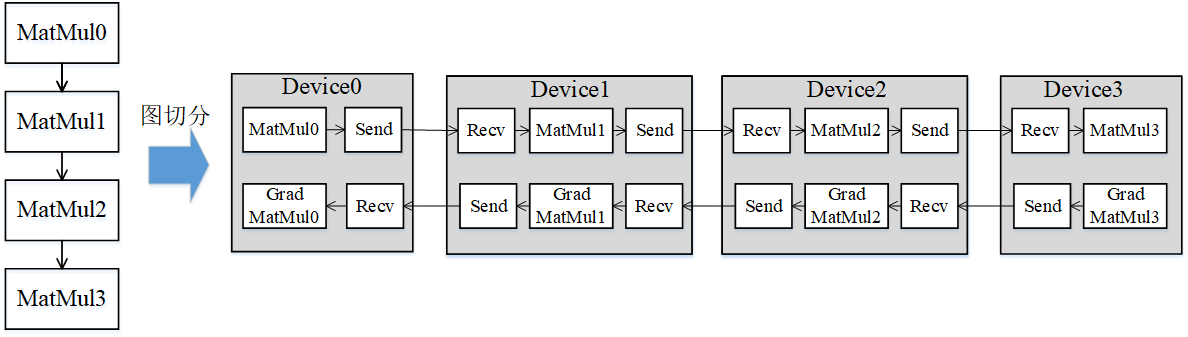
Figure 1: Schematic diagram of graph splitting in pipeline parallel
Simply splitting the model onto multiple devices does not bring about a performance gain, because the linear structure of the model has only one device at work at a time, while other devices are waiting, resulting in a waste of resources. In order to improve efficiency, the pipeline parallel further divides the small batch (MiniBatch) into more fine-grained micro batches (MicroBatch), and adopts a pipeline execution sequence in the micro batch, so as to achieve the purpose of improving efficiency, as shown in Figure 2. The small batches are cut into 4 micro-batches, and the 4 micro-batches are executed on 4 groups to form a pipeline. The gradient aggregation of the micro-batch is used to update the parameters, where each device only stores and updates the parameters of the corresponding group. where the white ordinal number represents the index of the micro-batch.
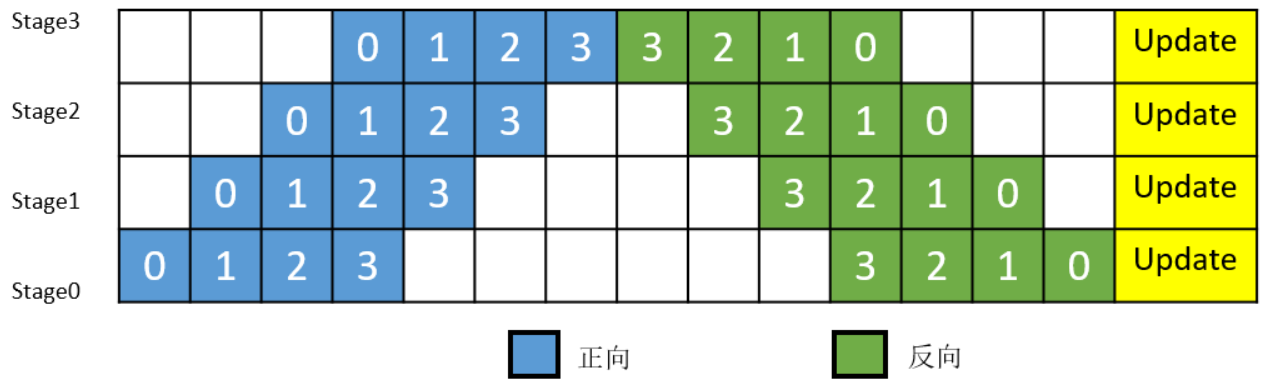
Figure 2: Schematic diagram of a pipeline parallel execution timeline with MicroBatch
In MindSpore’s pipeline parallel implementation, the execution order has been adjusted for better memory management. As shown in Figure 3, the reverse of the MicroBatch numbered 0 is performed immediately after its forward execution, so that the memory of the intermediate result of the numbered 0 MicroBatch is freed earlier (compared to Figure 2), thus ensuring that the peak memory usage is lower than in the way of Figure 2.
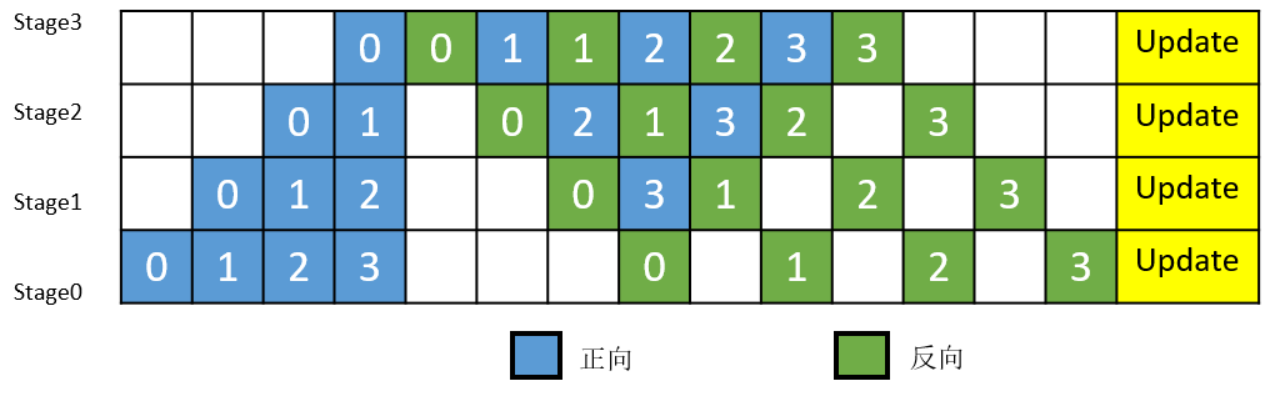
Figure 3: MindSpore Pipeline Parallel Execution Timeline Diagram
Operation Practices
Sample Code Description
Download address of the complete sample code:
https://gitee.com/mindspore/docs/tree/r1.8/docs/sample_code/distributed_training.
The directory structure is as follows:
└─sample_code
├─distributed_training
│ rank_table_16pcs.json
│ rank_table_8pcs.json
│ rank_table_2pcs.json
│ resnet.py
│ resnet50_distributed_training_pipeline.py
│ run_pipeline.sh
...
rank_table_16pcs.json, rank_table_8pcs.json and rank_table_2pcs.json are the networking information files. resnet.py and resnet50_distributed_training_pipeline.py are the network structure files. run_pipeline.sh are the execute scripts.
Downloading the Dataset
This example uses the CIFAR-10 dataset. For details about how to download and load the dataset,
visit https://www.mindspore.cn/tutorials/experts/en/r1.8/parallel/train_ascend.html#downloading-the-dataset.
Configuring the Distributed Environment
Pipeline parallelism supports Ascend and GPU.
For details about how to configure the distributed environment and call the HCCL, visit https://www.mindspore.cn/tutorials/experts/en/r1.8/parallel/train_ascend.html#preparations.
Defining the Network
The network definition is the same as that in the Parallel Distributed Training Example.
For details about the definitions of the network, optimizer, and loss function, visit https://www.mindspore.cn/tutorials/experts/en/r1.8/parallel/train_ascend.html#defining-the-network.
To implement pipeline parallelism, you need to define the parallel strategy and call the
pipeline_stageAPI to specify the stage on which each layer is to be executed. The granularity of thepipeline_stageAPI isCell.pipeline_stagemust be configured for allCellsthat contain training parameters.
class ResNet(nn.Cell):
"""ResNet"""
def __init__(self, block, num_classes=100, batch_size=32):
"""init"""
super(ResNet, self).__init__()
self.batch_size = batch_size
self.num_classes = num_classes
self.head = Head()
self.layer1 = MakeLayer0(block, in_channels=64, out_channels=256, stride=1)
self.layer2 = MakeLayer1(block, in_channels=256, out_channels=512, stride=2)
self.layer3 = MakeLayer2(block, in_channels=512, out_channels=1024, stride=2)
self.layer4 = MakeLayer3(block, in_channels=1024, out_channels=2048, stride=2)
self.pool = ops.ReduceMean(keep_dims=True)
self.squeeze = ops.Squeeze(axis=(2, 3))
self.fc = fc_with_initialize(512 * block.expansion, num_classes)
# pipeline parallel config
self.head.pipeline_stage = 0
self.layer1.pipeline_stage = 0
self.layer2.pipeline_stage = 0
self.layer3.pipeline_stage = 1
self.layer4.pipeline_stage = 1
self.fc.pipeline_stage = 1
def construct(self, x):
"""construct"""
x = self.head(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.pool(x, (2, 3))
x = self.squeeze(x)
x = self.fc(x)
return x
Training the Network
To enable pipeline parallelism, you need to add the following configurations to the training script:
Set
pipeline_stagesinset_auto_parallel_contextto specify the total number ofstages.Set the
SEMI_AUTO_PARALLELmode. Currently, the pipeline parallelism supports only this mode.Define the LossCell. In this example, the
nn.WithLossCellAPI is called.Finally, wrap the LossCell with
PipelineCell, and specify the Micro_batch size. To improve machine utilization, MindSpore divides Mini_batch into finer-grained Micro_batch to streamline the entire cluster. The final loss value is the sum of the loss values computed by all Micro_batch. The size of Micro_batch must be greater than or equal to the number ofstages.
import mindspore as ms
from mindspore import nn
from mindspore.nn import Momentum
from resnet import resnet50
def test_train_cifar(epoch_size=10):
ms.set_auto_parallel_context(parallel_mode=ms.ParallelMode.SEMI_AUTO_PARALLEL, gradients_mean=True)
ms.set_auto_parallel_context(pipeline_stages=2, save_graphs=True)
loss_cb = ms.LossMonitor()
data_path = os.getenv('DATA_PATH')
dataset = create_dataset(data_path)
batch_size = 32
num_classes = 10
net = resnet50(batch_size, num_classes)
loss = SoftmaxCrossEntropyExpand(sparse=True)
net_with_loss = nn.WithLossCell(net, loss)
net_pipeline = nn.PipelineCell(net_with_loss, 2)
opt = Momentum(net.trainable_params(), 0.01, 0.9)
model = ms.Model(net_pipeline, optimizer=opt)
model.train(epoch_size, dataset, callbacks=[loss_cb], dataset_sink_mode=True)
Running the Single-host with 8 devices Script
Using the sample code, you can run a 2-stage pipeline on 8 Ascend devices by using below scripts:
bash run_pipeline.sh [DATA_PATH] Ascend
You can run a 2-stage pipeline on 8 GPU devices using below scripts:
bash run_pipeline.sh [DATA_PATH] GPU