Host&Device Heterogeneous
![]()
Overview
In deep learning, one usually has to deal with the huge model problem, in which the total size of parameters in the model is beyond the device memory capacity. To efficiently train a huge model, one solution is to employ homogeneous accelerators (e.g., Ascend 910 AI Accelerator and GPU) for distributed training. When the size of a model is hundreds of GBs or several TBs, the number of required accelerators is too overwhelming for people to access, resulting in this solution inapplicable. One alternative is Host+Device hybrid training. This solution simultaneously leveraging the huge memory in hosts and fast computation in accelerators, is a promisingly efficient method for addressing huge model problem.
In MindSpore, users can easily implement hybrid training by configuring trainable parameters and necessary operators to run on hosts, and other operators to run on accelerators. This tutorial introduces how to train Wide&Deep in the Host+Ascend 910 AI Accelerator mode.
Basic Principle
Pipeline parallel and operator-level parallel are suitable for the model to have a large number of operators, and the parameters are more evenly distributed among the operators. What if the number of operators in the model is small, and the parameters are concentrated in only a few operators? Wide & Deep is an example of this, as shown in the image below. The Embedding table in Wide & Deep can be trained as a parameter of hundreds of GIGabytes or even a few terabytes. If it is executed on an accelerator ( device ) , the number of accelerators required is huge, and the training cost is expensive. On the other hand, if you use accelerator computing, the training acceleration obtained is limited, and it will also trigger cross-server traffic, and the end-to-end training efficiency will not be very high.
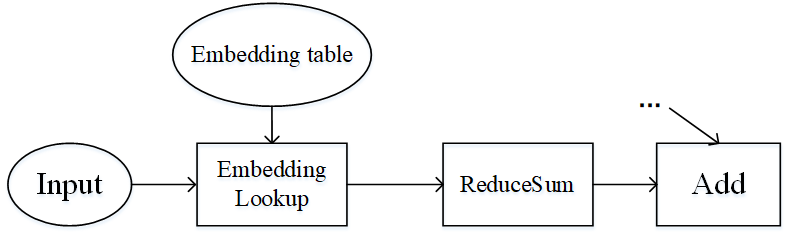
Figure: Part of the structure of the Wide & Deep model
A careful analysis of the special structure of the Wide & Deep model can be obtained: although the Embedding table has a huge amount of parameters, it participates in very little computation, and the Embedding table and its corresponding operator, the EmbeddingLookup operator, can be placed on the Host side, by using the CPU for calculation, and the rest of the operators are placed on the accelerator side. This can take advantage of the large amount of memory on the Host side and the fast computing of the accelerator side, while taking advantage of the high bandwidth of the Host to accelerator of the same server. The following diagram shows how Wide & Deep heterogeneous slicing works:
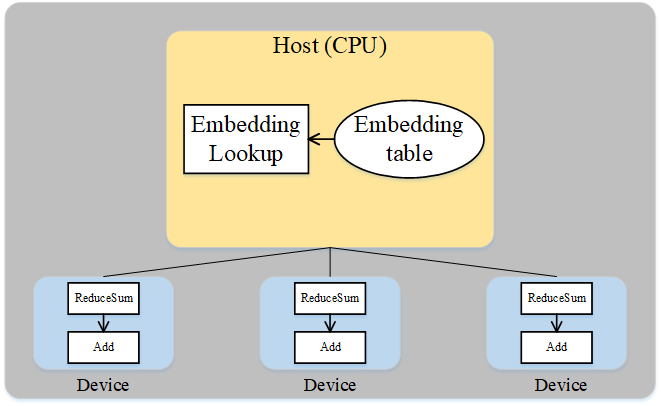
Figure: Wide & Deep Heterogeneous Approach
Practices
Sample Code Description
Prepare the model code. The Wide&Deep code can be found at: https://gitee.com/mindspore/models/tree/r1.8/official/recommend/wide_and_deep, in which
train_and_eval_auto_parallel.pydefines the main function for model training,src/directory contains the model definition, data processing and configuration files, andscript/directory contains the training scripts in different modes.Prepare the dataset. Please refer the link in [1] to download the dataset, and use the script
src/preprocess_data.pyto transform dataset into MindRecord format.Configure the device information. When performing distributed training in the bare-metal environment (That is, there is an Ascend 910 AI processor locally), the network information file needs to be configured. This example only employs one accelerator, thus
rank_table_1p_0.jsoncontaining #0 accelerator is configured. MindSpore provides an automated build script for generating this configuration file and related instructions. For the detailed, see HCCL_TOOL.
Configuring for Hybrid Training
Configure the flag of hybrid training. In the file
default_config.yaml, change the default value ofhost_device_mixto be1:host_device_mix: 1
Check the deployment of necessary operators and optimizers. In class
WideDeepModelof filesrc/wide_and_deep.py, check the execution ofEmbeddingLookupis at host:self.deep_embeddinglookup = nn.EmbeddingLookup() self.wide_embeddinglookup = nn.EmbeddingLookup()
In
class TrainStepWrap(nn.Cell)of filesrc/wide_and_deep.py, check two optimizers are also executed at host:self.optimizer_w.target = "CPU" self.optimizer_d.target = "CPU"
Training the Model
In order to save enough log information, use the command export GLOG_v=1 to set the log level to INFO before executing the script, and add the -p on option when compiling MindSpore. For the details about compiling MindSpore, refer to Compiling MindSpore.
Use the script script/run_auto_parallel_train.sh. Run the command bash run_auto_parallel_train.sh 1 1 <DATASET_PATH> <RANK_TABLE_FILE>, where the first 1 is the number of cards used in the case, the second 1 is the number of epochs, DATASET_PATH is the path of dataset, and RANK_TABLE_FILE is the path of the above rank_table_1p_0.json file.
The running log is in the directory of device_0, where loss.log contains every loss value of every step in the epoch. Here is an example:
epoch: 1 step: 1, wide_loss is 0.6873926, deep_loss is 0.8878349
epoch: 1 step: 2, wide_loss is 0.6442529, deep_loss is 0.8342661
epoch: 1 step: 3, wide_loss is 0.6227323, deep_loss is 0.80273706
epoch: 1 step: 4, wide_loss is 0.6107221, deep_loss is 0.7813441
epoch: 1 step: 5, wide_loss is 0.5937832, deep_loss is 0.75526017
epoch: 1 step: 6, wide_loss is 0.5875453, deep_loss is 0.74038756
epoch: 1 step: 7, wide_loss is 0.5798845, deep_loss is 0.7245408
epoch: 1 step: 8, wide_loss is 0.57553077, deep_loss is 0.7123517
epoch: 1 step: 9, wide_loss is 0.5733629, deep_loss is 0.70278376
epoch: 1 step: 10, wide_loss is 0.566089, deep_loss is 0.6884129
test_deep0.log contains the runtime log.
Search EmbeddingLookup in test_deep0.log, the following can be found:
[INFO] DEVICE(109904,python3.7):2020-06-27-12:42:34.928.275 [mindspore/ccsrc/device/cpu/cpu_kernel_runtime.cc:324] Run] cpu kernel: Default/network-VirtualDatasetCellTriple/_backbone-NetWithLossClass/network-WideDeepModel/EmbeddingLookup-op297 costs 3066 us.
[INFO] DEVICE(109904,python3.7):2020-06-27-12:42:34.943.896 [mindspore/ccsrc/device/cpu/cpu_kernel_runtime.cc:324] Run] cpu kernel: Default/network-VirtualDatasetCellTriple/_backbone-NetWithLossClass/network-WideDeepModel/EmbeddingLookup-op298 costs 15521 us.
The above shows the running time of EmbeddingLookup on the host.
Search FusedSparseFtrl and FusedSparseLazyAdam in test_deep0.log, the following can be found:
[INFO] DEVICE(109904,python3.7):2020-06-27-12:42:35.422.963 [mindspore/ccsrc/device/cpu/cpu_kernel_runtime.cc:324] Run] cpu kernel: Default/optimizer_w-FTRL/FusedSparseFtrl-op299 costs 54492 us.
[INFO] DEVICE(109904,python3.7):2020-06-27-12:42:35.565.953 [mindspore/ccsrc/device/cpu/cpu_kernel_runtime.cc:324] Run] cpu kernel: Default/optimizer_d-LazyAdam/FusedSparseLazyAdam-op300 costs 142865 us.
The above shows the running time of two optimizers on the host.
Reference
[1] Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, Xiuqiang He. DeepFM: A Factorization-Machine based Neural Network for CTR Prediction. IJCAI 2017.