# Building a Parallel Large Language Model Network
[](https://gitee.com/mindspore/docs/blob/master/tutorials/source_en/model_infer/ms_infer/parallel.md)
In recent years, with the rapid development of deep learning technologies, especially the emergence of large-scale pre-trained models (such as ChatGPT, LLaMA, and Pangu), the AI field has made significant progress. However, as model sizes continue to expand, the computing resources required by these large models, particularly GPU memory, are growing exponentially. For example, the Pangu model with 71 billion parameters requires approximately 142 GB of GPU memory at half-precision (FP16). In addition, the increasing sequence length of large models places immense pressure on GPU memory.
The constraints of GPU memory not only affect model loading but also limit batch sizes. Smaller batch sizes may lead to decreased inference efficiency, consequently impacting the overall throughput of the system.
The pressure on GPU memory makes it challenging for a single device to complete inference tasks within a reasonable time frame, and parallel computing has become a key strategy to address this challenge.
## Model Parallelism
When the number of model parameters is too large to fit into the GPU memory capacity of a single device, model parallelism can distribute different parts of the model across multiple devices. This approach effectively reduces the GPU memory requirements of a single device and enables inference of larger-scale models.
### Basic MatMul Module
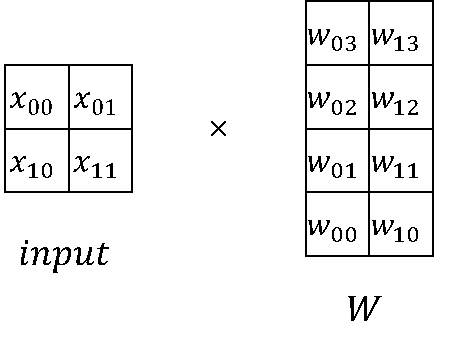
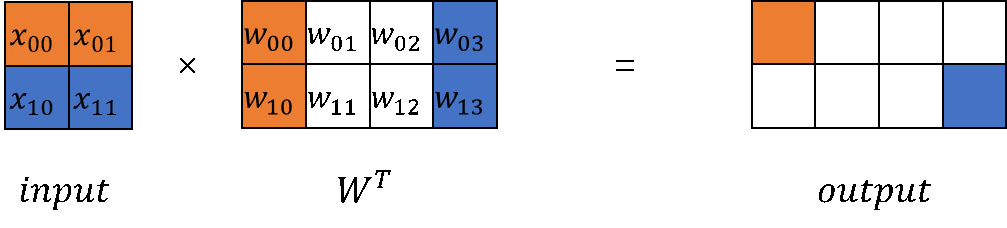
In large model computations, matrix multiplication (MatMul) accounts for a significant portion of both weight and computation workload. MatMul exhibits both column-wise parallelism and row-wise parallelism.
Starting with the original implementation of `nn.Dense` in MindSpore, we can build implementations for both column-wise and row-wise MatMul.
1. Creation and management of communication domains and management of large model configurations
Builds the `CommunicationHelper` class to manage the model parallel domain.
```python
from mindspore.communication import create_group, get_group_size
```
```python
class CommunicationHelper:
def __init__(self, group_name, size):
self.group_name = group_name
self.size = size
self.rank_list = [i for i in range(size)]
def create_tensor_model_parallel_group(self):
create_group(group=self.group_name, rank_ids=self.rank_list)
def get_tensor_model_parallel_group_size(self):
return get_group_size(group=self.group_name)
def get_tensor_model_parallel_group(self):
return self.group_name
```
Build `ConfigHelper` to manage and configure large model parameters.
```python
class ConfigHelper:
def __init__(self,
vocab_size,
hidden_size,
ffn_hidden_size,
num_layers,
batch_size,
seq_length, dtype,
num_heads,
has_bias=False):
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.ffn_hidden_size = ffn_hidden_size
self.num_layers = num_layers
self.batch_size = batch_size
self.seq_length = seq_length
self.dtype = dtype
self.num_heads = num_heads
self.has_bias = has_bias
```
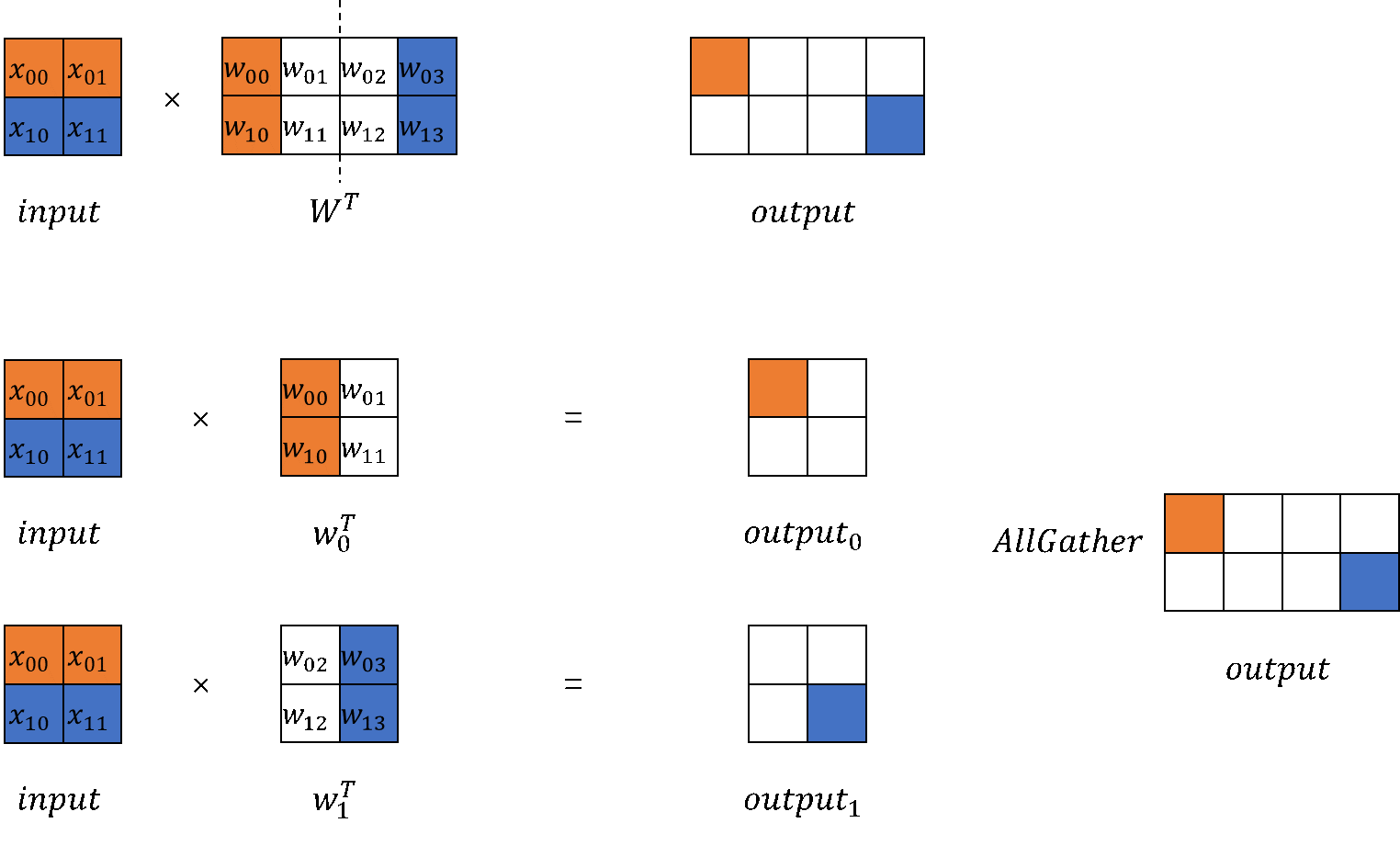
2. Column-wise MatMul
`ColumnParallelLinear` class calculates and initializes the sharded weights' shape based on the number of devices used for model parallelism. Column-wise means to shard `out_channels`. During the model's forward pass, MatMul is called to compute the parallel results. Finally, an `AllGather` operation can be optionally performed on the parallel results to obtain the complete output.
The MindSpore training and inference integrated framework supports enabling `infer_boost`. This parameter activates the high-performance self-developed operator library within the MindSpore framework. To enable this mode, you need to:
- Set variables.
```python
from mindspore import set_context
set_context(jit_config={"jit_level": 'O0', "infer_boost": 'on'})
```
- Set system environment variables.
```bash
export ASCEND_HOME_PATH={$ascend_custom_path}
```
For example, if there are 2 devices for model parallelism, set environment variables, initialize the communication group, and configure the model parameter `config` as follows:
```python
from mindspore import nn, Parameter, ops, Tensor
from mindspore.common import dtype as mstype
from mindspore.communication import init
from mindspore.common.initializer import initializer
import numpy as np
from mindspore import set_context
set_context(jit_config={"jit_level": 'O0', "infer_boost": 'on'})
TP_GROUP_NAME='tp'
TP_SIZE = 2
COMMUN_HELPER = CommunicationHelper(group_name=TP_GROUP_NAME, size=TP_SIZE)
init()
COMMUN_HELPER.create_tensor_model_parallel_group()
config = ConfigHelper(batch_size=64,
vocab_size=32000,
num_layers=4,
seq_length=2048,
hidden_size=1024,
ffn_hidden_size=4096,
dtype=mstype.float16,
num_heads=8,
has_bias=False)
```
Column-wise MatMul module
```python
class ColumnParallelLinear(nn.Cell):
def __init__(self,
in_channels,
out_channels,
weight_init=None,
bias_init=None,
has_bias=True,
dtype=mstype.float32):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.has_bias = has_bias
self.tensor_parallel_group_size = COMMUN_HELPER.get_tensor_model_parallel_group_size()
self.out_channels_per_partition = out_channels // self.tensor_parallel_group_size
self.dtype = dtype
weight_shape = (self.out_channels_per_partition, self.in_channels)
self.weight = Parameter(initializer(weight_init, weight_shape, self.dtype), name="weight")
if self.has_bias:
self.bias = Parameter(initializer(bias_init, (self.out_channels_per_partition), self.dtype), name="bias")
self.bias_add = ops.Add()
self.matmul = ops.BatchMatMul(transpose_b=True)
self.cast = ops.Cast()
def construct(self, x):
origin_dtype = x.dtype
x = self.cast(x, self.dtype)
out = self.matmul(x, self.weight)
if self.has_bias:
out = self.bias_add(
out, self.cast(self.bias, self.dtype)
)
out = self.cast(out, origin_dtype)
return out
```
The output of column-wise MatMul is parallel. To obtain a complete output, use `GatherLastDim`.
```python
class GatherLastDim(nn.Cell):
def __init__(self):
super().__init__()
self.all_gather = ops.AllGather(group=COMMUN_HELPER.get_tensor_model_parallel_group())
self.world_size = COMMUN_HELPER.get_tensor_model_parallel_group_size()
self.split = ops.Split(axis=0, output_num=self.world_size)
def construct(self, input_):
output = self.all_gather(input_)
tensor_list = self.split(output)
output = ops.cat(tensor_list, axis=-1)
return output
```
Inference of column-wise MatMul:
```python
column_parallel_linear = ColumnParallelLinear(in_channels=config.hidden_size,
out_channels=config.hidden_size,
weight_init='normal',
dtype=config.dtype,
has_bias=False)
input_x = Tensor(np.random.randn(config.batch_size, config.seq_length, config.hidden_size).astype(np.float32))
out_parallel = column_parallel_linear(input_x)
print(out_parallel.shape)
gather_last_dim = GatherLastDim()
out = gather_last_dim(out_parallel)
print(out.shape)
```
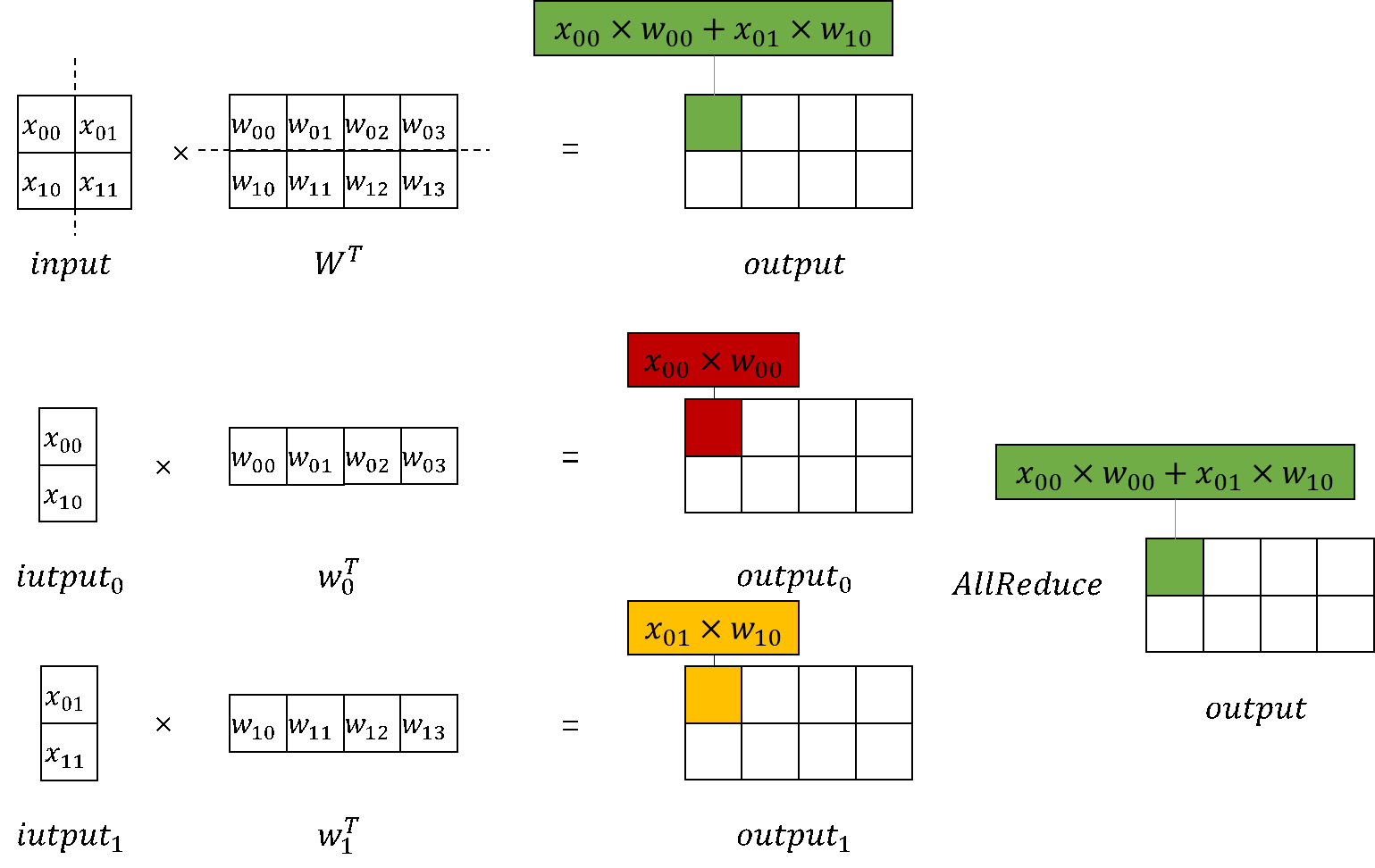
3. Row-wise MatMul
Similar to column-wise MatMul, `RowParallelLinear` shards the weight based on the size of the model parallel domain. During initialization, the sharding direction is row, that is, sharding `in_channels` before initialization. During the model's forward pass, after the MatMul is performed on the input and weight, the `AllReduce` operation needs to be performed on all `device` results.
The row-wise MatMul module is implemented as follows:
```python
class RowParallelLinear(nn.Cell):
def __init__(self,
in_channels,
out_channels,
weight_init='normal',
bias_init=None,
has_bias=True,
dtype=mstype.float32):
super().__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.has_bias = has_bias
self.tensor_parallel_group_size = COMMUN_HELPER.get_tensor_model_parallel_group_size()
self.in_channels_per_partition = in_channels // self.tensor_parallel_group_size
self.dtype = dtype
weight_shape = (self.out_channels, self.in_channels_per_partition)
self.weight = Parameter(initializer(weight_init, weight_shape, self.dtype), name="weight")
if self.has_bias:
self.bias = Parameter(initializer(bias_init, (self.in_channels_per_partition), self.dtype), name="bias")
self.bias_add = ops.Add()
self.bmm = ops.BatchMatMul(transpose_b=True)
self.all_reduce = ops.AllReduce(group=COMMUN_HELPER.get_tensor_model_parallel_group())
self.cast = ops.Cast()
def construct(self, x):
origin_dtype = x.dtype
x = self.cast(x, self.dtype)
output_parallel = self.bmm(x, self.weight)
if self.has_bias:
output_parallel = self.bias_add(output_parallel, self.cast(self.bias, self.dtype))
out = self.all_reduce(output_parallel)
out = self.cast(out, origin_dtype)
return out
```
Inference of row-wise MatMul:
```python
row_parallel_linear = RowParallelLinear(in_channels=config.hidden_size,
out_channels=config.hidden_size,
weight_init='normal',
dtype=config.dtype,
has_bias=False)
out = row_parallel_linear(out_parallel)
print(out.shape)
```
4. Embedding
In addition to MatMul, the Embedding layer can also be parallelized. The Embedding weights can be sharded across multiple devices, with each device responsible for mapping a different range of token IDs.
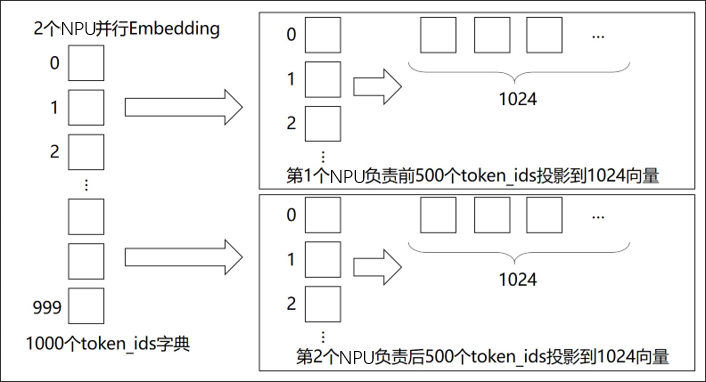
Specifically:
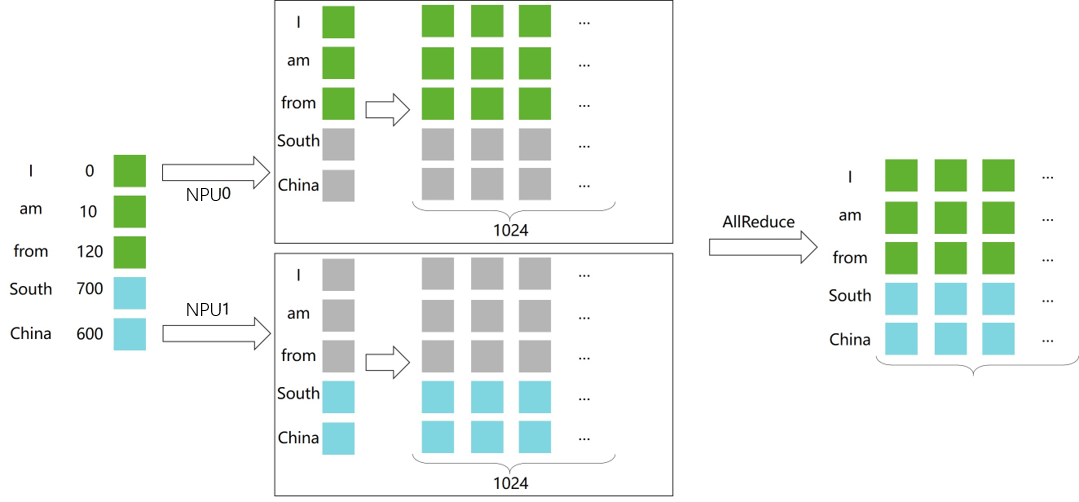
Based on nn.Embedding, build an Embedding layer for model parallelism.
```python
class VocabParallelEmbedding(nn.Cell):
def __init__(self,
num_embeddings,
embedding_dim,
init_method="normal",
init_type=mstype.float32):
super().__init__()
self.num_embeddings = num_embeddings
self.embedding_dim = embedding_dim
self.tensor_model_parallel_size = COMMUN_HELPER.get_tensor_model_parallel_group_size()
per_partition_vocab_size = self.num_embeddings // self.tensor_model_parallel_size
self.vocab_start_index = COMMUN_HELPER.get_tensor_model_parallel_group_rank() * per_partition_vocab_size
self.vocab_end_index = self.vocab_start_index + per_partition_vocab_size
self.num_embeddings_per_partition = (
self.vocab_end_index - self.vocab_start_index
)
self.embedding_weight = Parameter(
initializer(
init=init_method,
shape=(self.num_embeddings_per_partition, self.embedding_dim),
dtype=init_type,
),
name="embedding_weight",
)
self.all_reduce = ops.AllReduce(group=COMMUN_HELPER.get_tensor_model_parallel_group())
self.max_index_per_partition = Tensor(self.num_embeddings_per_partition - 1, dtype=mstype.int32)
self.expand_dims = ops.ExpandDims()
self.gather = ops.Gather()
self.sub = ops.Sub()
self.relu = ops.ReLU()
self.minimum = ops.Minimum()
self.eq = ops.Equal()
self.mul = ops.Mul()
def construct(self, x):
displaced_x = self.sub(x, self.vocab_start_index)
down_truncated_x = self.relu(displaced_x)
truncated_x = self.minimum(down_truncated_x, self.max_index_per_partition)
input_mask = self.eq(displaced_x, truncated_x)
input_mask = self.expand_dims(input_mask, -1)
output_parallel = self.gather(self.embedding_weight, truncated_x, 0)
output_parallel = self.mul(output_parallel, input_mask)
output = self.all_reduce(output_parallel)
return output
```
Inference of parallel Embedding:
```python
input_ids = np.random.randint(0, config.vocab_size, size=(config.batch_size, config.seq_length), dtype=np.int32)
input_ids = Tensor(input_ids)
embedding_output = vocab_parallel_embedding(input_ids)
print(embedding_output.shape)
```
### TransformerModel Parallel Adaptation
It can be seen that the tensor is processed sequentially. First, it passes through the `ColumnParallelLinear` column-wise MatMul to obtain the parallel results. Then, it is input to the `RowParallelLinear` row-wise MatMul, resulting in the complete output of the two MatMul operations.
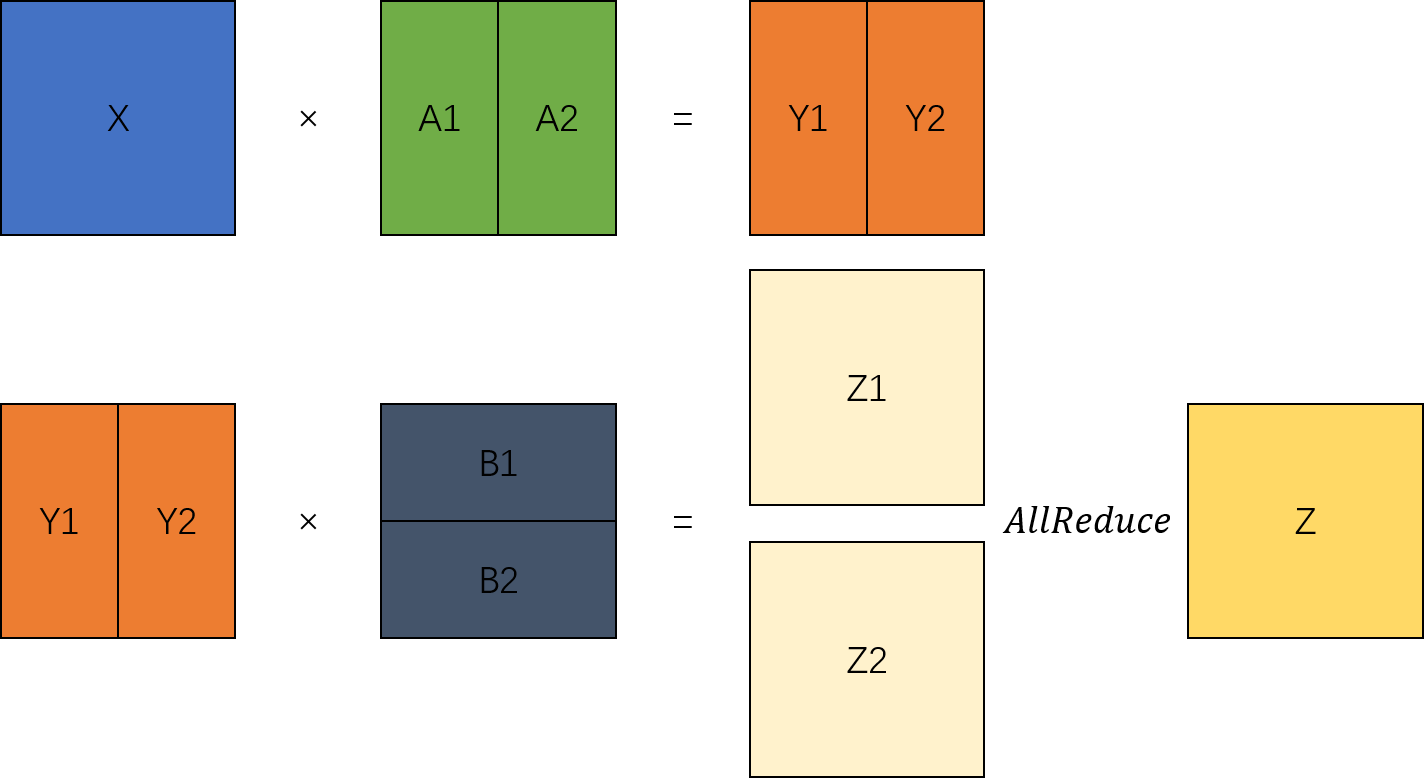
Based on the preceding analysis, you can change the TransformerModel built in [Building a Large Language Model Inference Network from Scratch](./model_dev.md) to a model structure that supports parallelism.
1. Attention
Take multi-head attention (MHA) as an example. The typical attention module in a Transformer is multi-headed, with each attention head operating independently. Therefore, when a single attention head is complete, the activation value can be sharded along the `hidden_size` dimension. For example, assume that the number of MHA headers (`num_heads`) is 16, the dimension (`head_dim`) of each header is 256, then the `hidden_size` is 4096, and the linears of Q/K/V have in/out dimensions of 4096. When the model parallelism is set to `tensor_model_parallel=4`, these linears are sharded into four devices. Each device(4096,1024) means that each device computes 4 heads.
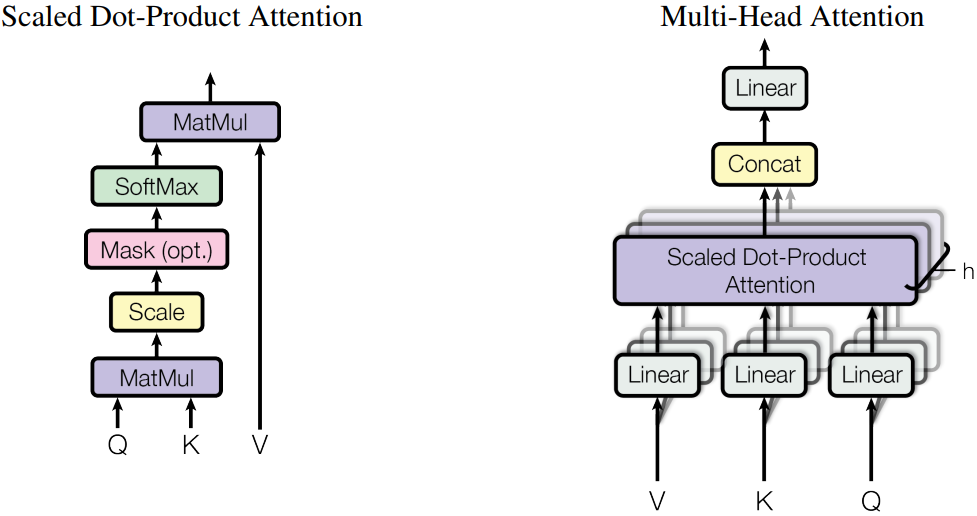
The following is an example of the Attention module code:
```python
class ParallelAttention(nn.Cell):
def __init__(self, config):
super().__init__()
self.tensor_model_parallel_size = COMMUN_HELPER.get_tensor_model_parallel_group_size()
self.num_heads_per_partition = config.num_heads // self.tensor_model_parallel_size
self.head_dim = config.hidden_size // config.num_heads
self.norm_factor = math.sqrt(self.head_dim)
self.q = ColumnParallelLinear(in_channels=config.hidden_size,
out_channels=config.hidden_size,
weight_init='normal',
has_bias=config.has_bias)
self.k = ColumnParallelLinear(in_channels=config.hidden_size,
out_channels=config.hidden_size,
weight_init='normal',
dtype=config.dtype,
has_bias=config.has_bias)
self.v = ColumnParallelLinear(in_channels=config.hidden_size,
out_channels=config.hidden_size,
weight_init='normal',
dtype=config.dtype,
has_bias=config.has_bias)
self.flash_attention = ops.operations.nn_ops.FlashAttentionScore(head_num=self.num_heads_per_partition,
scale_value=1.0/self.norm_factor,
next_tokens=0)
self.out = RowParallelLinear(in_channels=config.hidden_size,
out_channels=config.hidden_size,
weight_init='normal',
dtype=config.dtype,
has_bias=config.has_bias)
def construct(self, x, mask):
query = self.q(x)
key = self.k(x)
value = self.v(x)
_, _, _, context_layer = self.flash_attention(query, key, value, attn_mask=mask)
output = self.out(context_layer)
return output
```
2. MLP
The MLP module is actually two fully-connected layers, which can also be processed by parallel MatMul. The code is as follows:
```python
class ParallelMLP(nn.Cell):
def __init__(self, config):
super().__init__()
self.w1 = ColumnParallelLinear(in_channels=config.hidden_size,
out_channels=config.ffn_hidden_size,
weight_init='normal',
dtype=config.dtype,
has_bias=config.has_bias)
self.w2 = RowParallelLinear(in_channels=config.ffn_hidden_size,
out_channels=config.hidden_size,
weight_init='normal',
dtype=config.dtype,
has_bias=config.has_bias)
self.act_func = nn.SiLU()
self.mul = ops.Mul()
def construct(self, x):
x = self.w1(x)
x = self.act_func(x)
output = self.w2(x)
return output
```
3. TransformerLayer
TransformerLayer consists of Attention and MLP. Since there are no single operators that can be parallelized, you only need to pass the parallel parameters to Attention and MLP.
```python
class ParallelTransformerLayer(nn.Cell):
def __init__(self, config):
super().__init__()
self.attention = ParallelAttention(config=config)
self.feed_forward = ParallelMLP(config=config)
self.attention_norm = RMSNorm(dim=config.hidden_size, dtype=config.dtype)
self.ffn_norm = RMSNorm(dim=config.hidden_size, dtype=config.dtype)
self.add = ops.Add()
def construct(self, x, mask):
norm_output = self.attention_norm(x)
attention_output = self.attention(norm_output, mask)
norm_input = self.add(x, attention_output)
norm_output = self.ffn_norm(norm_input)
mlp_output = self.feed_forward(norm_output)
output = self.add(norm_input, mlp_output)
return output
```
4. TransformerModel
```python
class ParallelTransformer(nn.Cell):
def __init__(self, config):
super().__init__()
self.embedding = VocabParallelEmbedding(num_embeddings=config.vocab_size,
embedding_dim=config.hidden_size,
init_method='normal',
init_type=config.dtype)
self.layers = nn.CellList()
self.num_layers = config.num_layers
for _ in range(config.num_layers):
layer = ParallelTransformerLayer(config=config)
self.layers.append(layer)
self.norm_out = RMSNorm(dim=config.hidden_size, dtype=config.dtype)
def construct(self, x, mask):
hidden_state = self.embedding(x)
for i in range(self.num_layers):
hidden_state = self.layers[i](hidden_state, mask)
hidden_state = self.norm_out(hidden_state)
return hidden_state
```
For details about the end-to-end large language model code project, see [model_dev.py](https://gitee.com/mindspore/docs/blob/master/docs/sample_code/infer_code/model_dev.py) script. Run the following command to verify the code:
```shell
msrun --worker_num 2 --local_worker_num 2 --master_port 8124 --log_dir msrun_log --join True --cluster_time_out 300 model_dev.py
```